jieba库的使用与词云
一、准备
在制作词云之前我们需要自行安装三个库,它们分别是:jieba, wordcloud, matplotlib
安装方法基本一致,下面我以安装wordcloud的过程为例。
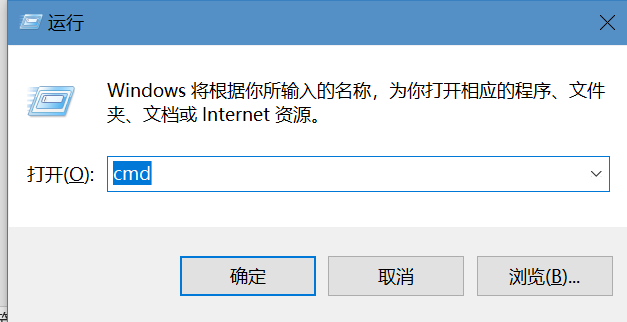
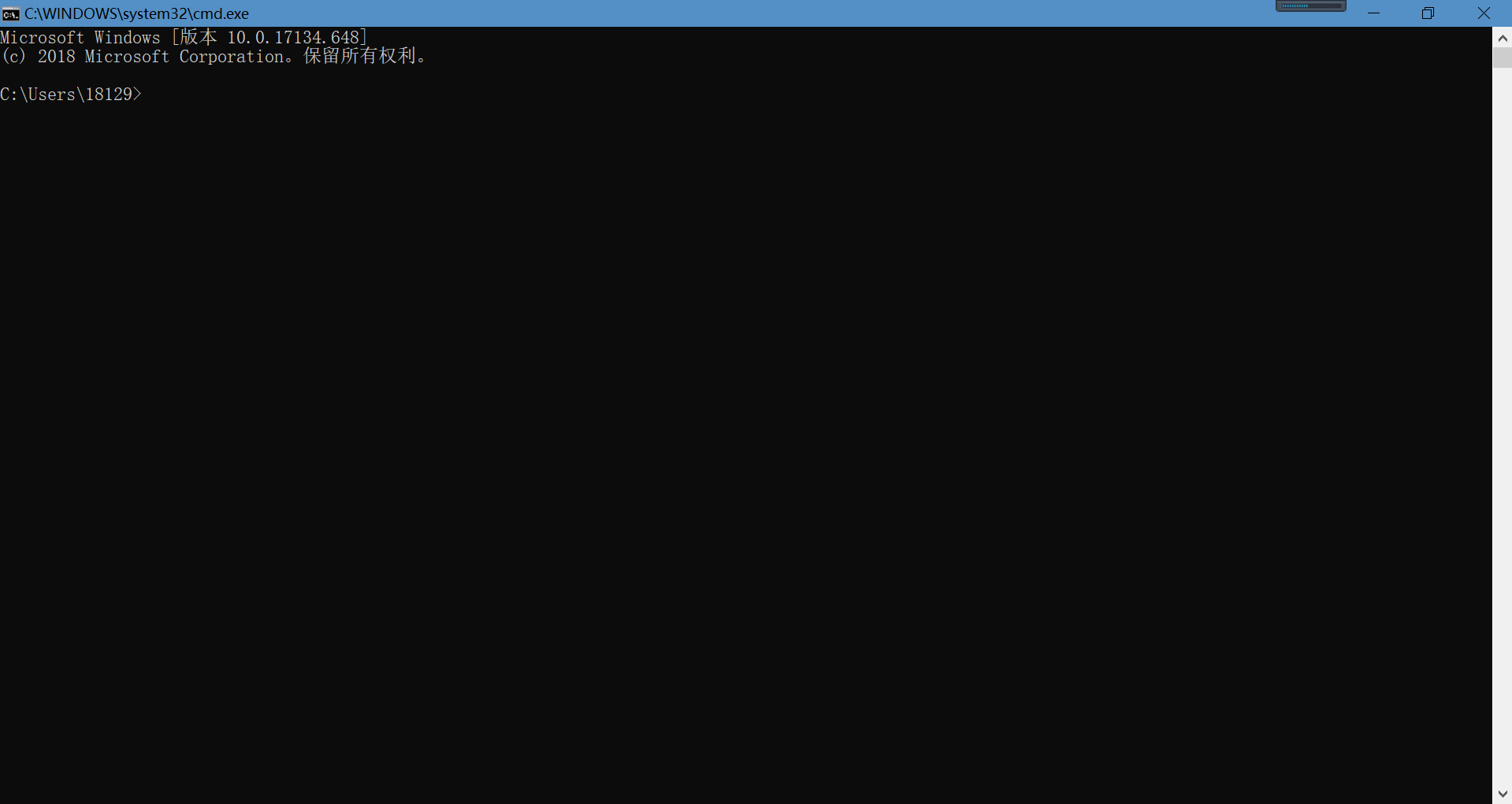
第一步,按下Win+R打开命令输入框,并输入cmd,点击确定
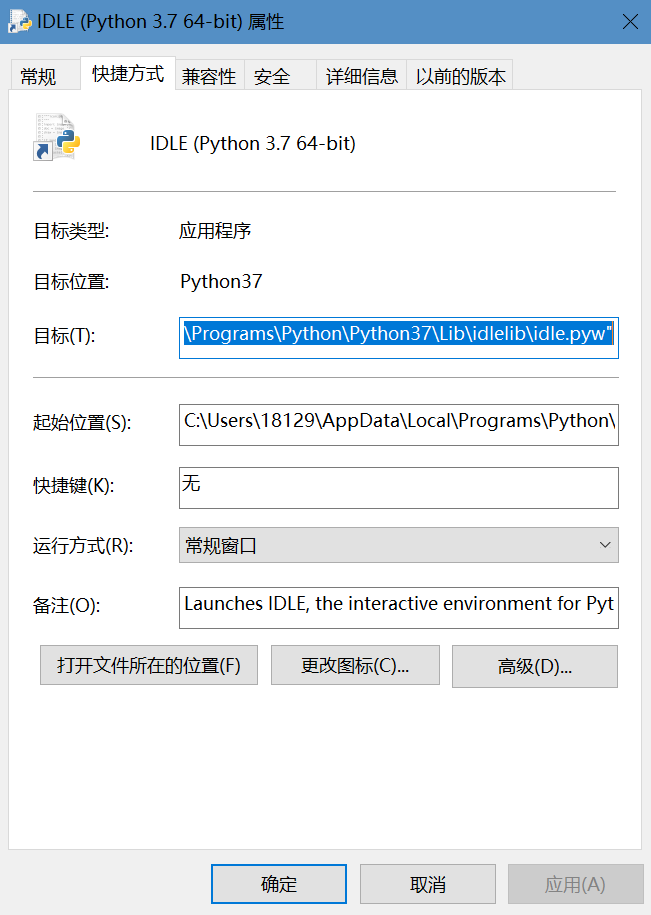
第二步,找到IDLE文件(即平时打代码的程序),右击,点击属性,得到如下界面,再点击打开文件所在的位置
打开Scripts文件,可以看到pip文件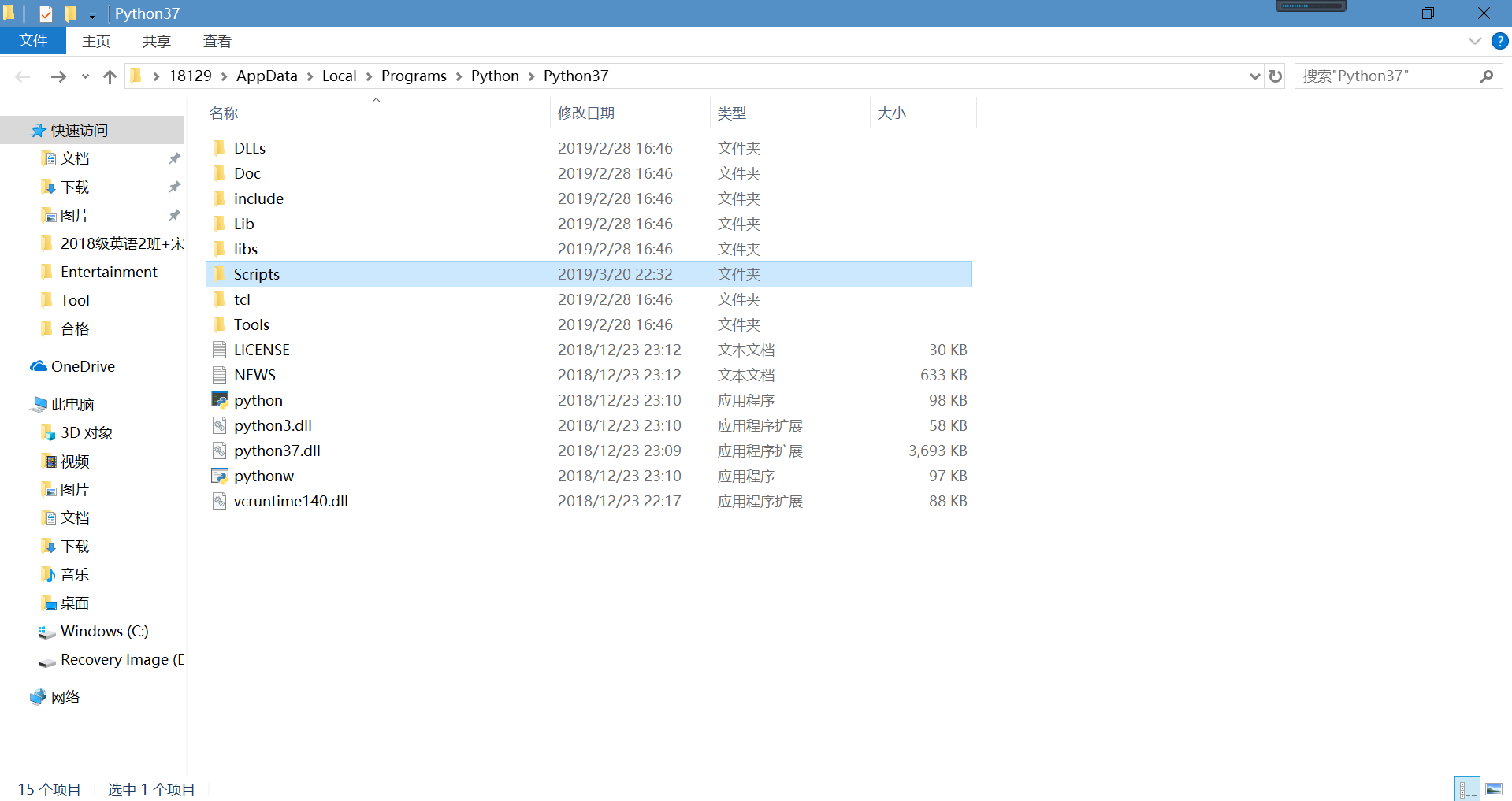

将pip文件直接拖至刚才输入cmd打开的界面
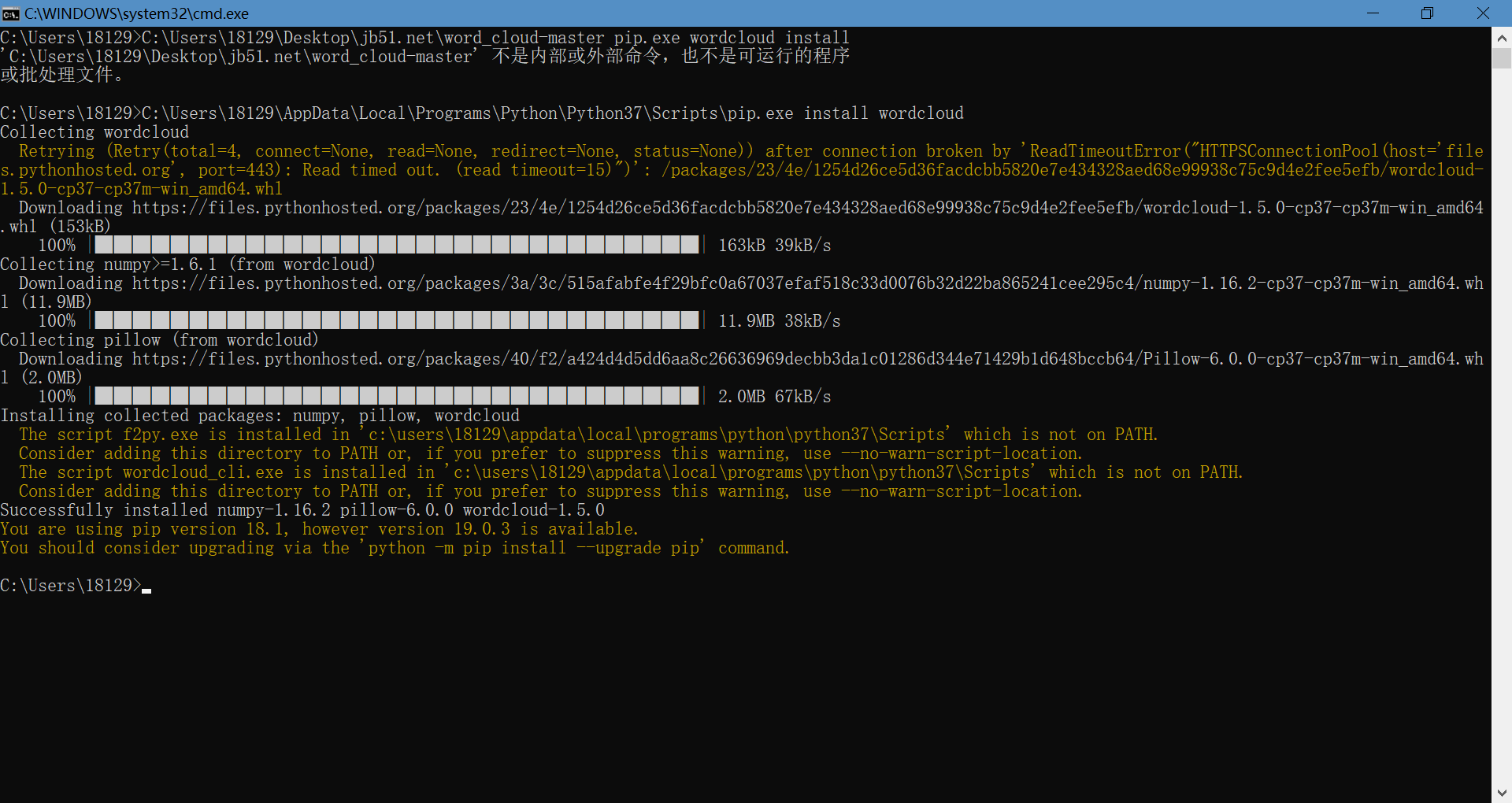
在pip.exe后方输入install wordcloud(注意以空格为间隔),然后点击回车,这样我们就安装好了wordcloud库函数
剩余两个jieba和matplotlib都是同样的操作,只需把上文中的wordcloud替换即可,这里就不再操作了
二、对文本中出现的文字频率进行统计
首先我们需要找到一篇文章,将其弄成txt格式的文件,这里我在网上下载了小说《盗墓笔记》
下载完成后需将txt文件与编写程序的文件放置在同一文件夹中
然后就是编写代码了,代码如下
import jieba
txt = open("盗墓笔记.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
运行程序,为节省时间,我只让程序输出频次最高的前十个词,效果如下
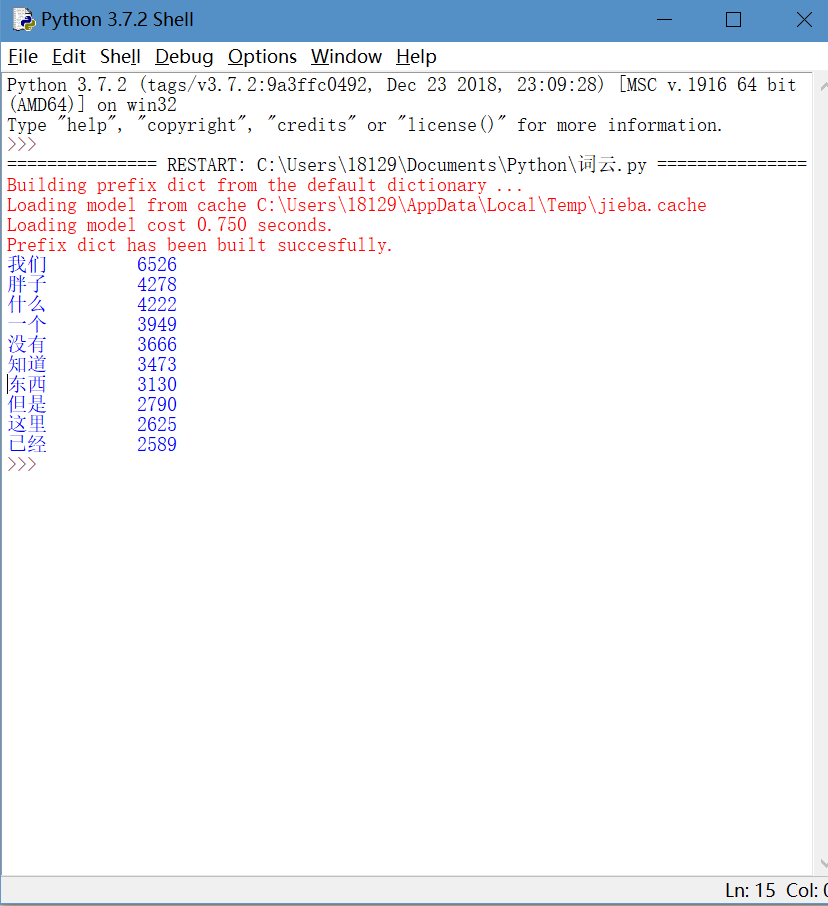
这样,统计词语频次的程序就搞定了
三、使小说中出现的词语以词云输出
这一步跟上一步统计频次一样的,我们都得将python程序与小说放置在同一文件夹中
然后就输入以下代码
from wordcloud import WordCloud
import matplotlib.pyplot as plt #绘制图像的模块
import jieba #jieba分词 path_txt='盗墓笔记.txt'
f = open(path_txt,'r',encoding='UTF-8').read() # 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(f)) wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1920,height=1080).generate(cut_text) plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
运行后,会出现如下的一个窗口
点击左下方最右边的形如磁盘的键,将该图片下载下来

词云也完成了
jieba库的使用与词云的更多相关文章
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- python jieba 库分词结合Wordcloud词云统计
import jieba jieba.add_word("福军") jieba.add_word("少安") excludes={"一个", ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- 使用jieba和wordcloud进行中文分词并生成《悲伤逆流成河》词云
因为词云有利于体现文本信息,所以我就将那天无聊时爬取的<悲伤逆流成河>的评论处理了一下,生成了词云. 关于爬取影评的爬虫大概长这个样子(实际上是没有爬完的): #!/usr/bin/env ...
- wordcloud + jieba 生成词云
利用jieba库和wordcloud生成中文词云. jieba库:中文分词第三方库 分词原理: 利用中文词库,确定汉字之间的关联概率,关联概率大的生成词组 三种分词模式: 1.精确模式:把文本精确的切 ...
- wordcloud库 词云
•wordcloud使用方法 常规使用方法 import wordcloud #创建一个词云对象 w = wordcloud.WordCloud(background_color="whit ...
- 用Python实现一个词频统计(词云+图)
第一步:首先需要安装工具python 第二步:在电脑cmd后台下载安装如下工具: (有一些是安装好python电脑自带有哦) 有一些会出现一种情况就是安装不了词云展示库 有下面解决方法,需看请复制链接 ...
- 利用python实现简单词频统计、构建词云
1.利用jieba分词,排除停用词stopword之后,对文章中的词进行词频统计,并用matplotlib进行直方图展示 # coding: utf-8 import codecs import ma ...
随机推荐
- 05 Maven 生命周期和插件
Maven 生命周期和插件 除了坐标.依赖以及仓库之外, Maven 另外两个核心概念是生命周期和插件.在有关 Maven 的日常使用中,命令行的输入往往就对应了生命周期,如 mvn package ...
- linux 操作系统rz sz 快速上传和下载文件
## Centos 安装 rz sz yum install lrzsz ### Ubuntu 安装 apt-get install lrzsz
- Linux shell脚本的字符串截取
http://blog.csdn.net/gumanren/article/details/5601544 Linux 的字符串截取很有用.有八种方法. 假设有变量 var=http://www.ha ...
- 2018.08.22 codves2370 小机房的树(lca+树上差分)
传送门 一道板子题. 直接树链剖分维护树上lca然后差分就行了. 代码: #include<bits/stdc++.h> #define N 50005 #define lc (p< ...
- 2018.07.18 HAOI2009 逆序对数列(线性dp)
传送门 目前只会n2" role="presentation" style="position: relative;">n2n2的dp" ...
- 用Java操作数据库Datetime数据
Date.Calendar.Timestamp的区别.相互转换与使用 1 Java.util.Date 包含年.月.日.时.分.秒信息. // String转换为Date String dateStr ...
- Tomcat & SVN
1. Tomcat简介 tomcat是一个web服务器,类似nginx,apache的http nginx,http只能处理html等静态文件(jpg) 网页分为静态网页(以.html或者.htm结尾 ...
- 表格边框重复合并属性: border-collapse:collapse;
table { border-collapse:collapse; }
- Spinner功能和用法
书中只是简单写了选择的界面,没有写出选择之后的结果显示,我做了进一步功能. MainActivity.java public class MainActivity extends Activity { ...
- BZOJ 1008 [HNOI2008]越狱 (简单排列组合 + 快速幂)
1008: [HNOI2008]越狱 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 10503 Solved: 4558[Submit][Status ...