安装部署OpenPAI + VSCode 提交
==========================================================
安装openpai请参考这篇
https://www.cnblogs.com/jins-note/p/9673883.html
==========================================================
首先准备两台服务器(必须为Ubuntu16.04 Server),一台作为master,一台作为worker(master和worker由我们自己指定)。每台服务器都必须要有的:
1、ssh服务(这在安装Ubuntu16.04 Server的时候有选择)
2、docker-ce
3、两台服务器必须要有相同的用户名以及密码
4、用于登录每台计算机的用户名应具有sudo权限
5、两台服务器要在同一个网段中
准备好之后,我们需要先在master的docker中执行以下命令:
sudo docker pull docker.io/openpai/dev-box sudo docker run -itd \ -e COLUMNS=$COLUMNS -e LINES=$LINES -e TERM=$TERM \ -v /var/lib/docker:/var/lib/docker \ -v /var/run/docker.sock:/var/run/docker.sock \ -v /pathHadoop:/pathHadoop \ -v /pathConfiguration:/cluster-configuration \ --pid=host \ --privileged=true \ --net=host \ --name=dev-box \ docker.io/openpai/dev-box sudo docker exec -it dev-box /bin/bash cd /pai/pai-management
第一条指令是拉dev-box的镜像
第二条指令是运行dev-box
第三条指令是进入dev-box
然后
cd quick-start cp quick-start-example.yaml ../quick-start.yaml cd .. vi quick-start.yaml
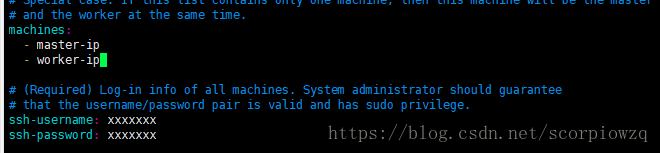
master-ip写你指定的master的ip
worker-ip就是另外一台服务器的ip
ssh-username就是你的服务器的username
ssh-password就是相应的password
完成之后
python paictl.py cluster generate-configuration \ -i quick-start.yaml \ -o /path/to/cluster-configuration/dir
/path/to/cluster-configuration/dir 这个路径可以随意放置,建议写成 /cluster-configuration/
然后进入 /cluster-configuration/ 会发现有四个.yaml文件,一般是不用改的。
然后执行
python paictl.py cluster k8s-bootup \ -p /path/to/cluster-configuration/dir
同样,这里的/path/to/cluster-configuration/dir 写成你放那四个.yaml配置文件的地方,/cluster-configuration/
这时可能要等一段时间,执行快完成的时候如果出现kube-proxy已经存在的错误的话,执行
python paictl.py cluster k8s-clean -p /cluster-configuration 这个paictl.py文件在/pai/pai-management/ 目录下
然后再执行第二步的命令就可以了。
此时你可以访问
http://<master>:9090
这个网页
然后就是最后一步
python paictl.py service start \ -p /path/to/cluster-configuration/dir
同样的/path/to/cluster-configuration/dir改为你放四个.yaml文件的目录,这里是 /cluster-configuration/
这里执行也要等一段时间,如果出现了driver-one-shot等待,这里可以等一段时间,如果等待时间过长的话,直接终止,然后执行
python paictl.py service delete -p /cluster-configuration
这里的/cluster-configuration改为你存放四个.yaml文件的目录,相当于清理容器内容
然后再执行
python paictl.py cluster k8s-clean -p /cluster-configuration
这个命令,相当于卸载k8s
然后再从第二步开始执行。
如果出现zookeeper错误的话,你执行
echo hostname
这个命令,然后进入你存放四个yaml文件的目录,查看cluster-configuration.yaml这个文件,看看machine-list中的master的hostname是否和执行上面的命令的hostname不一样,如果不一样则修改回和执行上面的命令一样的hostname。
如果你发现执行上面的命令和.yaml文件一样的hostname,那很遗憾,执行这两条命令吧:
python paictl.py service delete -p /cluster-configuration python paictl.py cluster k8s-clean -p /cluster-configuration
然后从第二步开始执行。
如果一直没报错的话,恭喜你安装成功可以访问
http://<master>:9286
这个网页,如果你发现你的GPU没有显示信息,很可能是因为你的GPU版本太低,楼主的GeForce GT 730就是不支持显示,但不代表没有GPU。
然后就是如何提交代码了。
=================================================================
我们这里使用vscode,首先安装vscode,最新版就可以,然后下载vs的插件https://marketplace.visualstudio.com/items?itemName=ms-toolsai.vscode-ai 点击install然后再vscode里面安装即可。
安装完成之后会有这些东西
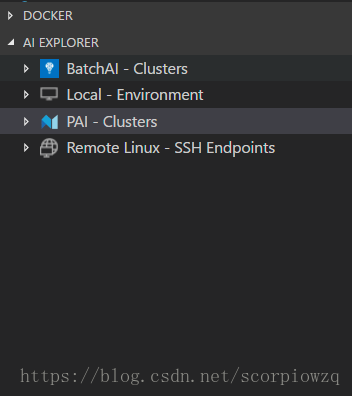
然后右击PAI-Cluster Add Configuration
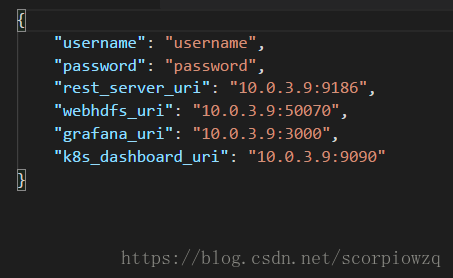
这个username 是 admin
password 是admin-password
这个账号密码是默认的,如何添加新的账户,我还没研究好。
然后其他的uri将ip改为你的master的ip,端口别改。
然后点finish你会发现你的PAI-Cluster目录里面多了一个东西,然后右击它,点击submit job,会进入一个json文件,需要改的地方为

改为这个,*为通配符,这里是提交.py文件,如果你要提交其他东西的话,如名字为data.xls你可以再includes里面再加入"*.xls"即可。

这个是docker的镜像,你可以去docker-hub找到。

这个codeDir是存放代码文件的目录,你可以右击PAI-Clusters目录下的东西,然后点击open storage explorer,就可以看到一些目录,你可以自己创一个目录,或者使用里面已经有的目录,在codeDir添加上去就可以了。

然后这个command 就是你执行这个代码文件的命令,如python 123.py (如果有参数,可以添加)。
然后点击Finish就可以了,然后他就会上传。
如果出现submit fail 没有这个文件的是因为你的AI Storage Explorer里面没有这个目录,你可以自己添加进去。就像outputDir一样。
安装部署OpenPAI + VSCode 提交的更多相关文章
- 安装部署 OpenPAI Install OpenPAI on Ubuntu
介绍 不管是机器学习的老手,还是入门的新人,都应该装备上尽可能强大的算力.除此之外,还要压榨出硬件的所有潜力来加快模型训练.OpenPAI作为GPU管理的利器,不管是一块GPU,还是上千块GPU, ...
- OpenPAI大规模人工智能平台安装部署文档
环境要求: 如果需要图形界面,需要在Ubuntu系统安装,否则centos系统安装时是没有问题的(web端和命令行进行任务提交) 安装过程需要有另外一台控制端机器(注意:区别于集群所在的任何一台服务器 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- 161209、简要分析ZooKeeper基本原理及安装部署
一.ZooKeeper 基本概念 1.ZooKeeper 是什么? Zookeeper官网地址: http://zookeeper.apache.org/ Zookeeper官网文档地址:http:/ ...
- 开源分布式实时计算引擎 Iveely Computing 之 安装部署(2)
在Github中下载代码和二进制程序中,您都会看到一个bin\iveely computing目录,里面即是Iveely Computing的运行库. 以前总是有 ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- 使用docker安装部署Spark集群来训练CNN(含Python实例)
使用docker安装部署Spark集群来训练CNN(含Python实例) http://blog.csdn.net/cyh_24/article/details/49683221 实验室有4台神服务器 ...
- Storm-0.9.0.1安装部署 指导
可以带着下面问题来阅读本文章: 1.Storm只支持什么传输 2.通过什么配置,可以更改Zookeeper默认端口 3.Storm UI必须和Storm Nimbus部署在同一台机器上,UI无法正常工 ...
随机推荐
- php7 改为从栈上分配内在的思路
php7的特点是规则上不从堆上分配内存,改为从栈上分配内存, 因为有些场景是从堆上分配内在后,还要手动释放内存,利用栈分配内在快的特点,在有需要的时候,再在堆上分配内在 但是栈上分配的内存,不能返回, ...
- 【LeetCode】 617. 合并二叉树
题目 给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠. 你需要将他们合并为一个新的二叉树.合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否 ...
- Binder AIDL中自定义类型传递的源码分析
binder机制实现的IPC和共享内存的方式不同,它采取的是值拷贝的方式,即进程间传递的实体遵循Parcelable协议, Bp端负责向Parcel里写东西,Bn端负责从Parcel里读取还原,顺序是 ...
- linux 可执行文件与写操作的同步问题
当一个可执行文件已经为write而open时,此时的可执行文件是不允许被执行的.反过来,一个文件正在执行时,它也是不允许同时被write模式而open的.这个约束很好理解,因为文件执行和文件被写应该需 ...
- 一口一口吃掉Hexo(六)
如果你想得到更好的阅读效果,请访问我的个人网站 ,版权所有,未经许可不得转载! 不知不觉已经更新到了最后一节了,很开心你能看到这一节,相信你也已经在你的虚拟主机上成功部署了你的网站,但是可能总会遇到一 ...
- 桌面程序开发入门(WinForm with C#)
1.使用Visual Studio 2013创建新项目 2.创建一个主窗体和4个子窗体 3.创建一个数据库.一个表.一个存储过程 4.在配置文件里添加数据库连接字符串 5.真正的编码工作. 第一步:创 ...
- eclipse 中文件引用报错不能编译,但引用文件确实存在
方法1:clean工程 方法2: 检查.classpath文件中该引用文件是否被排除在外.
- Spring Framework’s WebDataBinder
Last week, I was just outside our nation’s capital teaching Spring Web MVC Framework to a wonderful ...
- docker1-安装和使用
docker安装和使用 一.安装docker 1.1 centos7.2安装docker 环境:centos7.2 安装方法:https://docs.docker.com/engine/instal ...
- txt文本框设为密码模式后,后台(服务器端)设置不了值
txt文本框设为密码模式后,因为安全问题,后台(服务器端)设置不了值,只有在前台(客户端)复制才能显示