Pig安装与应用
1. 参考说明
参考文档:
http://pig.apache.org/docs/r0.17.0/start.html#build
2. 安装环境说明
2.1. 环境说明
CentOS7.4+ Hadoop2.7.5的伪分布式环境
|
主机名 |
NameNode |
SecondaryNameNode |
DataNodes |
|
centoshadoop.smartmap.com |
192.168.1.80 |
192.168.1.80 |
192.168.1.80 |
Hadoop的安装目录为:/opt/hadoop/hadoop-2.7.5
3. 安装
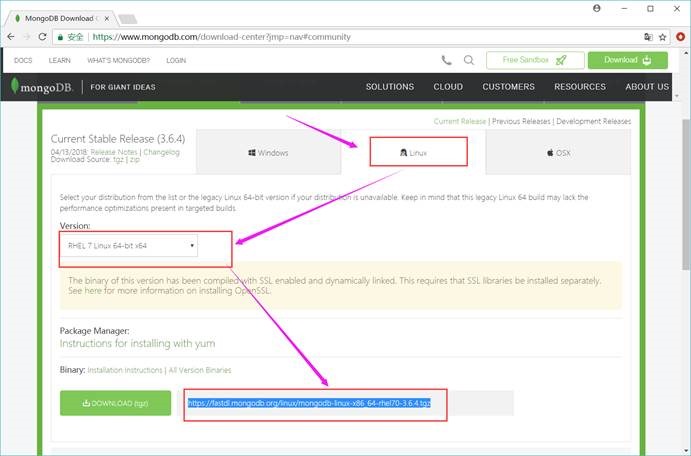
3.1. Pig下载
http://pig.apache.org/releases.html#Download
[root@server1 ~]# mkdir /opt/mongodb
[root@server1 ~]# chown -R mongodb:mongodb
/opt/mongodb/
3.2. Pig解压
将下载的pig-0.17.0.tar.gz解压到/opt/hadoop/pig-0.17.0目录下
4. 配置
4.1. 修改profile文件
vi
/etc/profile
export PIG_HOME=/opt/hadoop/pig-0.17.0
export PATH=$PATH:$PIG_HOME/bin
4.2. 将JDK升级为1.8版本
将JDK切换成1.8的版本,并修改所有与JAVA_HOME相关的变量
4.3. 修改pig的配置文件
vi
/opt/hadoop/pig-0.17.0/conf/pig.properties
exectype=mapreduce
4.4. 修改mapred-site.xml以启用jobhistory
vi
/opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.80:10020</value>
</property>
5. 启动Hadoop
5.1. 启动YARN与HDFS
cd
/opt/hadoop/hadoop-2.7.5/sbin
start-all.sh
5.2. 启动historyserver
cd
/opt/hadoop/hadoop-2.7.5/sbin
mr-jobhistory-daemon.sh start historyserver
6. 应用Pig工具
6.1. 导入文件到HDFS中
hadoop
fs -mkdir -p /input/ncdc/micro-tab
hadoop
fs -copyFromLocal sample.txt /input/ncdc/micro-tab/sample.txt
6.2. 启动运行Pig的交互式Shell环境
cd
/opt/hadoop/pig-0.17.0/bin
pig
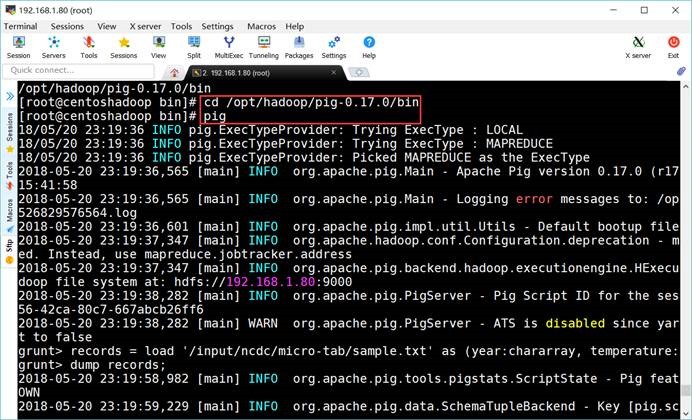
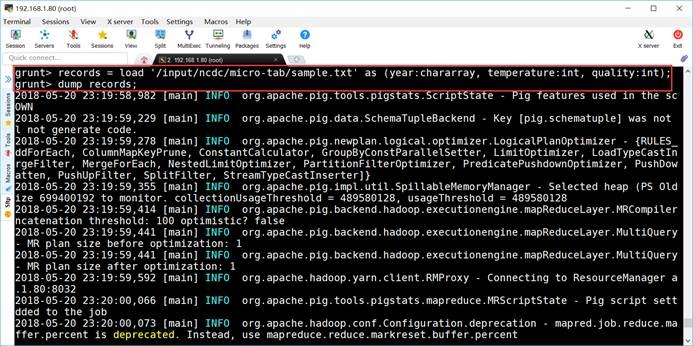
6.3. 运行任务
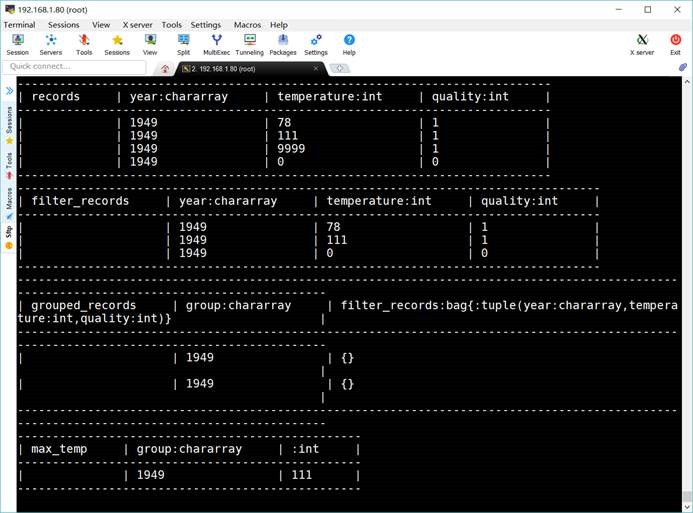
grunt> records = load
'/input/ncdc/micro-tab/sample.txt' as (year:chararray, temperature:int,
quality:int);
grunt> dump records;

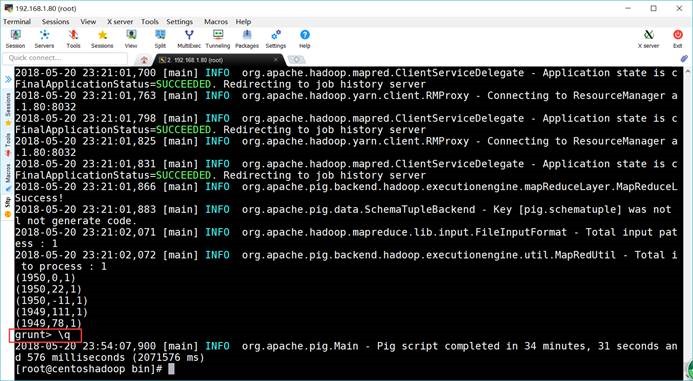
6.4. 退出
grunt> \q
6.5. 显示模式
cd
/opt/hadoop/pig-0.17.0/bin
pig
grunt> records = LOAD
'/input/ncdc/micro-tab/sample.txt' as (year:chararray, temperature:int,
quality:int);
grunt> DUMP
records;
grunt> DESCRIBE records
records:
{year: chararray,temperature: int,quality: int}
grunt>
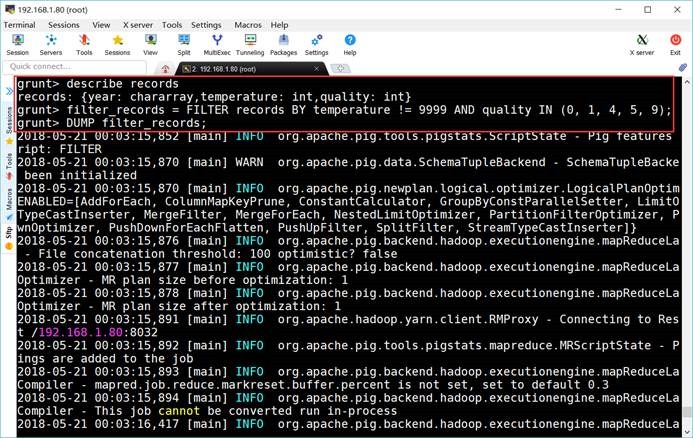
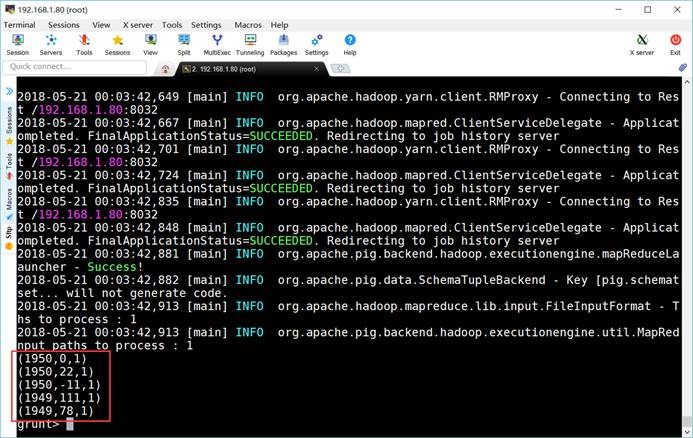
6.6. 过滤数据
grunt> filter_records =
FILTER records BY temperature != 9999 AND quality IN (0, 1, 4, 5,
9);
grunt> DUMP
filter_records;
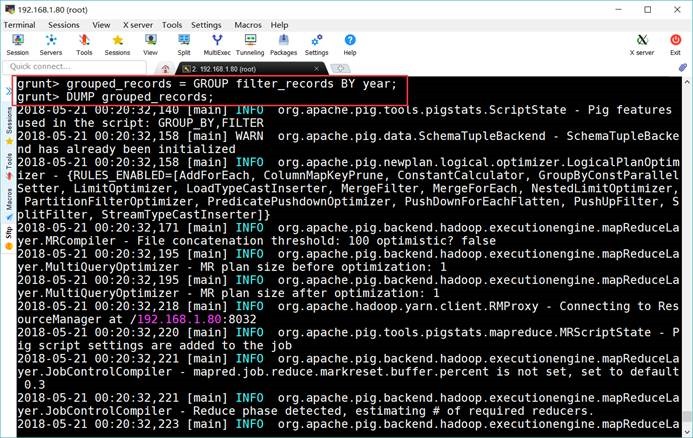
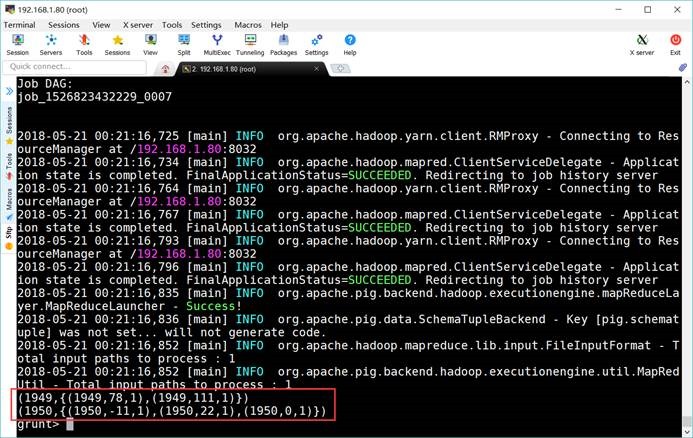
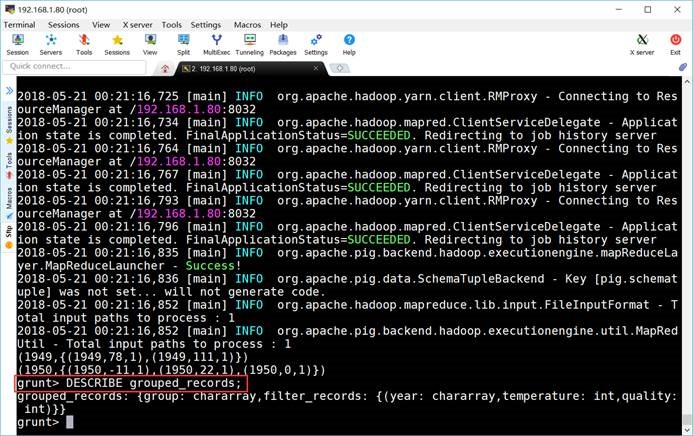
6.7. 分组记录
grunt> grouped_records =
GROUP filter_records BY year;
grunt> DUMP
grouped_records;
grunt> DESCRIBE
grouped_records;
grouped_records: {group: chararray,filter_records:
{(year: chararray,temperature: int,quality: int)}}
grunt>
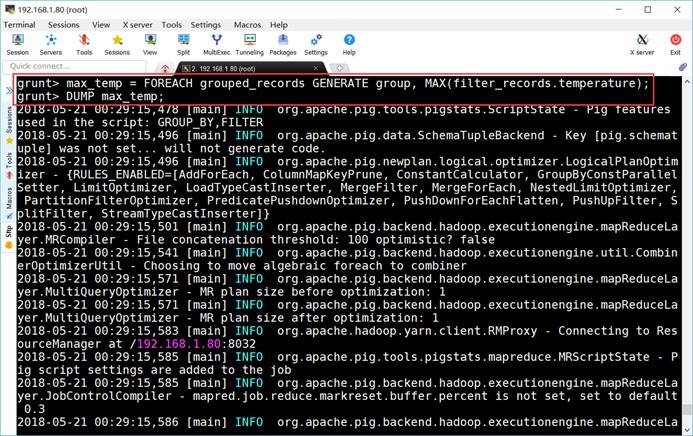
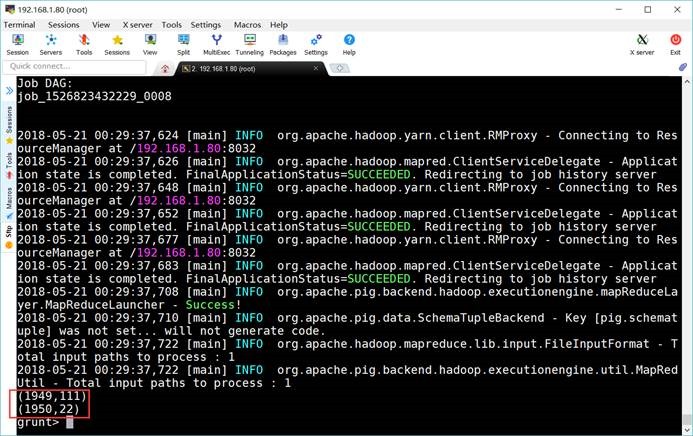
6.8. 计算最大值
grunt> max_temp = FOREACH
grouped_records GENERATE group, MAX(filter_records.temperature);
grunt> DUMP
max_temp;
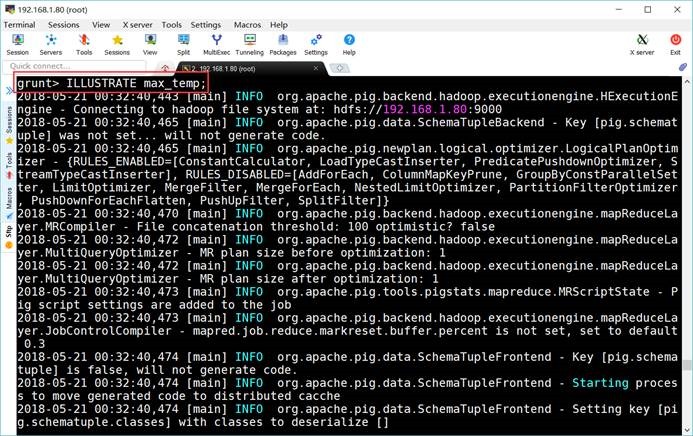
6.9. 查看执行过程
grunt> ILLUSTRATE max_temp;
Pig安装与应用的更多相关文章
- 大数据之pig安装
大数据之pig安装 1.下载 pig download 2. 解压安装 mapreduce模式安装: 1:设置HADOOP_HOME,如果pig所在节点不是集群中的节点,那就需要把集群中使用的hado ...
- Pig安装及简单使用(pig版本0.13.0,Hadoop版本2.5.0)
原文地址:http://www.linuxidc.com/Linux/2014-03/99055.htm 我们用MapReduce进行数据分析.当业务比较复杂的时候,使用MapReduce将会是一个很 ...
- Hadoop:pig 安装及入门示例
pig是hadoop的一个子项目,用于简化MapReduce的开发工作,可以用更人性化的脚本方式分析数据. 一.安装 a) 下载 从官网http://pig.apache.org下载最新版本(目前是0 ...
- Hadoop之Pig安装
Pig可以看做是Hadoop的客户端软件,使用Pig Latin语言可以实现排序.过滤.求和.分组等操作. Pig的安装步骤: 一.去Pig的官方网站下载.http://pig.apache.org/ ...
- Pig安装
环境: hadoop-2.4.1.jdk1.6.0_45.pig-0.12.1 1.下载pig并解压 tar -xzvf pig-0.12.1.tar.gz 2.设置环境变量 export PIG ...
- pig安装配置
pig的安装配置很简单,只需要配置一下环境变量和指向hadoop conf的环境变量就行了 1.上传 2.解压 3.配置环境变量 Pig工作模式 本地模式:只需要配置PATH环境变量${PIG_HOM ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- pig安装配置及实例
一.前提 1. hadoop集群环境配置好(本人hadoop版本:hadoop-2.7.3) 2. windows基础环境准备: jdk环境配置.esclipse环境配置 二.搭建pig环境 1.下载 ...
- hadoop,hbase,pig安装
注意端口,办公网只能访问8000-9000的端口 pig的一些lib文件版本 /home/map/hadoop/lib下一些98.5的lib没删除
随机推荐
- python学习笔记07-元组 字典
元组: 元组里面的元素不可修改 创建后只可读 不可写 一个元素的时候 在后面加一个逗号 字典: 无序的 Python 中唯一的映射类型 采用键值对的形式存储数据 key必须是可哈希的 可哈希表示 ...
- gitHub-高仿58同城加载动画
导入方式: /build.gradle repositories { maven { url "https://jitpack.io" } } /app/build.gradle ...
- Android 开发工具类 01_AppUtils
1.获取应用程序名称: 2.获取应用程序版本信息. import android.content.Context; import android.content.pm.PackageInfo; imp ...
- 安装微软dynamics AX2012R3-AOS(含域服务器的安装)
安装之前首先要确保硬盘可用量>60G,内存要在7G及以上,我是在Mac里装的虚拟机,分配了7G内存(我的电脑总共才8G),编译CIL内存占用到了98% 一.Server 2016新建域控服务器 ...
- 计算机上面常用的计算单位 & 个人计算机架构与接口设备
不多说,直接上干货! 计算机上面常用的计算单位 容量单位 速度单位 此网络常使用的单位为 Mbps 是 Mbits per second,亦即是每秒多少 Mbit. 个人计算机架构与接口设备 整个 ...
- mysql 设置隔离级别
查看隔离级别: mysql> select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ ...
- .Net Core使用NLog记录日志
参见:https://github.com/NLog/NLog.Web/wiki/Getting-started-with-ASP.NET-Core-2 大致步骤: Nuget中引用NLog及NLog ...
- lucene基本原理
1.术语 lucene 在存储它的全文索引结构时,是有层次结构的,这涉及到5个层次:索引(Index):段(Segment):文档(Document):域(Field):词(Term),他们的关系如下 ...
- 遇见CUBA CLI
原文:Meet CLI for CUBA Platform 翻译:CUBA China CUBA-Platform 官网 : https://www.cuba-platform.com CUBA Ch ...
- [转]数据库中Schema(模式)概念的理解
在学习数据库时,会遇到一个让人迷糊的Schema的概念.实际上,schema就是数据库对象的集合,这个集合包含了各种对象如:表.视图.存储过程.索引等. 如果把database看作是一个仓库,仓库很多 ...