HBase(一)HBase入门简介
一 HBase 的起源
HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop 的子项目来开发维护,用于支持结构化的数据存储。
Apache HBase™是Hadoop数据库,这是一个分布式,可扩展的大数据存储。
当您需要随机,实时读取/写入您的大数据时使用Apache HBase™。该项目的目标是托管非常大的表 - 数十亿行×数百万列 - 在商品硬件集群上。Apache HBase是一个开源的,分布式的,版本化的非关系数据库,其模型是由Chang等人在Google的Bigtable:一种用于结构化数据的分布式存储系统之后建模的。就像Bigtable利用Google文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS之上提供了类似Bigtable的功能。
官方旧版本下载地址:http://archive.apache.org/dist/hbase/ 官方网站:http://hbase.apache.org
-- 2006 年 Google 发表 BigTable 白皮书
-- 2006 年开始开发 HBase
-- 2008 年北京成功开奥运会,程序员默默地将 HBase 弄成了 Hadoop 的子项目
-- 2010 年 HBase 成为 Apache 顶级项目
-- 现在很多公司二次开发出了很多发行版本,你也开始使用了。
不一定所有的企业都会使用 HBase,大数据的框架可以是相互配合相互依赖的,同时,根据不同的业务,部分框架之间的使用也可以是相互独立的。例如有些企业在处理整个业务时, 只是用 HDFS+Spark 部分的内容。所以在学习 HBase 框架时,一定要有宏观思维,了解其框架特性,不一定非要在所有的业务中使用所有的框架,要具体情况具体分析,酌情选择。
二 HBase在商业项目中的能力
每天:
1) 消息量:发送和接收的消息数超过 60 亿
2) 将近 1000 亿条数据的读写
3) 高峰期每秒 150 万左右操作
4) 整体读取数据占有约 55%,写入占有 45%
5) 超过 2PB 的数据,涉及冗余共 6PB 数据
6) 数据每月大概增长 300 千兆字节。
三 HBase 的架构
HBase 一种是作为存储的分布式文件系统,另一种是作为数据处理模型的 MR 框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在 HDFS 直接存储的文件往往不具有结构化,所以催生出了 HBase 在 HDFS 上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
架构图如下图所示:
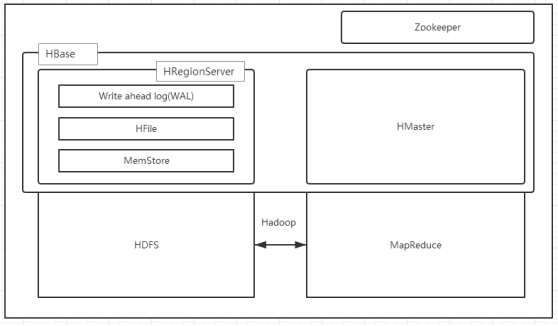
HBase 内置有 Zookeeper ,但一般我们会有其他的 Zookeeper 集群来监管 master 和region server,Zookeeper 通过选举,保证任何时候,集群中只有一个活跃的 HMaster,HMaster与 HRegionServer 启动时会向 ZooKeeper 注册,存储所有 HRegion 的寻址入口,实时监控HRegionserver 的上线和下线信息。并实时通知给 HMaster,存储 HBase 的 schema 和 table 元数据,默认情况下,HBase 管理 ZooKeeper 实例,Zookeeper 的引入使得 HMaster 不再是单点故障。一般情况下会启动两个 HMaster,非 Active 的 HMaster 会定期的和 Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个 HMaster 反而增加了 Active HMaster 的负担。
一个 RegionServer 可以包含多个 HRegion,每个 RegionServer 维护一个 HLog,和多个 HFiles以及其对应的 MemStore。RegionServer 运行于 DataNode 上,数量可以与 DatNode 数量一致, 请参考如下架构图:
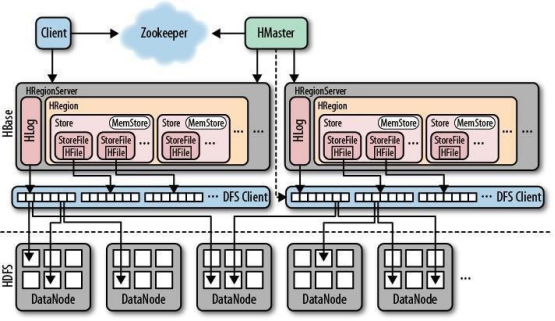
四 HBase 的角色
1. HMaster
功能:
1) 监控 RegionServer
2) 处理 RegionServer 故障转移
3) 处理元数据的变更
4) 处理 region 的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过 Zookeeper 发布自己的位置给客户端
2. RegionServer
功能:
1) 负责存储 HBase 的实际数据
2) 处理分配给它的 Region
3) 刷新缓存到 HDFS
4) 维护 HLog
5) 执行压缩
6) 负责处理 Region 分片
组件:
1) Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中, 然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 WAL
中之后,RegsionServer 会在内存中存储键值对。
5) Region
Hbase 表的分片,HBase 表会根据 RowKey 值被切分成不同的 region 存储在 RegionServer 中,在一个 RegionServer 中可以有多个不同的 region。
五 HBase2.0 新特性
2017 年 8 月 22 日凌晨 2 点左右,HBase 发布了 2.0.0 alpha-2,相比于上一个版本,修复了
500 个补丁,我们来了解一下 2.0 版本的 HBase 新特性。最新文档:
http://hbase.apache.org/book.html#ttl
官方发布主页:
http://mail-archives.apache.org/mod_mbox/www-announce/201708.mbox/<CADcMMgFzmX0x
YYso-UAYbU7V8z-Obk1J4pxzbGkRzbP5Hps+iA@mail.gmail.com
举例:
1) region 进行了多份冗余
主 region 负责读写,从 region 维护在其他 HregionServer 中,负责读以及同步主 region 中的信息,如果同步不及时,是有可能出现 client 在从 region 中读到了脏数据(主 region 还没来得及把 memstore 中的变动的内容 flush)。
2) 更多变动
https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12340859&styleName=&projectId
=12310753&Create=Create&atl_token=A5KQ-2QAV-T4JA-FDED%7Ce6f233490acdf4785b697
HBase(一)HBase入门简介的更多相关文章
- 【HBase】HBase Getting Started(HBase 入门指南)
入门指南 1. 简介 Quickstart 会让你启动和运行一个单节点单机HBase. 2. 快速启动 – 单点HBase 这部分描述单节点单机HBase的配置.一个单例拥有所有的HBase守护线程- ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- Hbase系列-Hbase简介
自1970年以来,关系数据库用于数据存储和维护有关问题的解决方案.大数据的出现后,好多公司实现处理大数据并从中受益,并开始选择像 Hadoop 的解决方案.Hadoop使用分布式文件系统,用于存储大数 ...
- Hbase之三:Hbase Shell使用入门
HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”.HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建.删 ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
随机推荐
- K8S调度之标签选择器
Kubernetes 调度简介 除了让 kubernetes 集群调度器自动为 pod 资源选择某个节点(默认调度考虑的是资源足够,并且 load 尽量平均),有些情况我们希望能更多地控制 pod 应 ...
- AVC的三种规格
AVC其实就是H.264标准,是由ITU-T和ISO/IEC组成的联合视频组(JVT,Joint Video Team)一起开发的,ITU-T给这个标准命名为H.264(以前叫做H.26L),而ISO ...
- jQuery插件开发中$.extend和$.fn.extend辨析
jQuery插件开发分为两种: 1 类级别 类级别你可以理解为拓展jquery类,最明显的例子是$.ajax(...),相当于静态方法. 开发扩展其方法时使用$.extend方法,即jQuery. ...
- java 根据二叉树前序 ,中序求后续
在一棵二叉树总,前序遍历结果为:ABDGCEFH,中序遍历结果为:DGBAECHF,求后序遍历结果. 我们知道: 前序遍历方式为:根节点->左子树->右子树 中序遍历方式为:左子树-> ...
- C语言入门教程-(2)基本程序结构
1.简单的C语言程序结构 要建造房屋,首先需要打地基.搬砖搭建框架(这大概就是为什么叫搬砖的原因).学习计算机语言的时候也一样,应该从基本的结构开始学起.下面,我们看一段简单的源代码,这段代码希望大家 ...
- zookeeper日常报错总结
1:创建子节点的时候 没有根节点 org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for ...
- 关于在函数中使用Array.prototype.slice.call而不是直接用slice
arguments是每个函数在运行的时候自动获得的一个近似数组的对象(除了length外没有其他属性),这个arguments对象其实并不是Array,所以没有slice方法. Array.proto ...
- 程序移植到AUTOCAD2013笔记
1:需要引用acmgd.dll acdbmgd.dll,AcCoreMdg.dll, accui.dll 四个dll 2: 2010下的的acmgd.dll被拆分为acmgd.dll和AcCoreMd ...
- JavaScript的基本概念
主要内容: 语法 数据类型 流控制语句 理解函数 ECMA-262描述了JavaScript语法等基本概念.目前,ECMA-262第3版中定义的ECMAScript是各个浏览器实现最多的版本.所以主要 ...
- spfa+floyed+最长路+差分约束系统(F - XYZZY POJ - 1932)(题目起这么长感觉有点慌--)
题目链接:https://cn.vjudge.net/contest/276233#problem/F 题目大意:给你n个房子能到达的地方,然后每进入一个房子,会消耗一定的生命值(有可能是负),问你一 ...