Ubuntu16.04下Hive的安装与配置
一、系统环境
os : Ubuntu 16.04 LTS 64bit
jdk : 1.8.0_161
hadoop : 2.6.4
mysql : 5.7.21
hive : 2.1.0
在配置hive之前,要先配置hadoop。
二、安装步骤
1、hive的安装与配置
1.1 hive的安装
下载hive2.1.0,使用以下命令安装到/usr/local

最后一条 sudo chown -R hadoop hive 中的hadoop是我的用户名,要更改成自己的用户名。
1.2 配置环境变量

添加以下代码:
export HIVE_HOME=/usr/local/hive
export HCAT_HOME=$HIVE_HOME/hcatalog
export HIVE_CONF=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin
保存,然后

1.3 配置hive-site.xml
以下操作默认是再hive安装目录/usr/local/hive下进行
cp conf/hive-default.xml.template conf/hive-site.xml
然后修改hive-site.xml中的部分内容,将对应的name修改成下面的value:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
将hvie-site.xml中的${system:java.io.tmpdir}全部替换为/usr/local/hive/tmp,将${system:user.name}全部替换为${user.name}
2、安装并配置MySQL
2.1 安装MySQL
运行 sudo apt-get install mysql-server ,安装mysql,安装过程中会有提示输入登录密码。
启动mysql服务 service mysql start
下载mysql-jdbc包,我下载的是mysql-connector-java-5.1.45.tar.gz,然后执行以下操作:

2.2 创建hive用户
mysql -u root -p
create user 'hive' identified by 'hive';
grant all privileges on *.* to 'hive'@'localhost' identified by 'hive';
2.3 使用hive用户再在mysql中创建名为hive的数据库
mysql -uhive -phive
mysql> create database hive;
3、启动hive
$ start-dfs.sh
$ hive
可能会出现问题
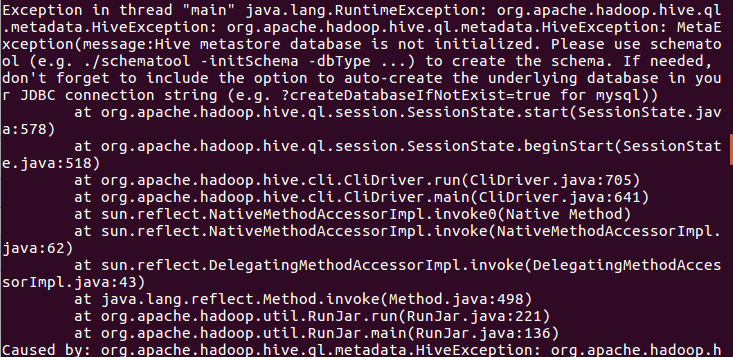
出现此问题的原因是元数据库没有初始化,使用命令
schematool -dbType mysql -initSchema
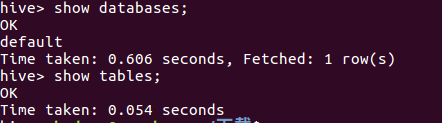
后再使用命令 $ hive 即可成功进入
三、参考
1、http://dblab.xmu.edu.cn/blog/install-hive/
Ubuntu16.04下Hive的安装与配置的更多相关文章
- ubuntu16.04下sublime text3安装和配置
ubuntu16.04下sublime text3安装和配置 2018年04月20日 10:31:08 zhengqijun_ 阅读数:1482 1.安装方法 1)使用ppa安装 sudo add-a ...
- Ubuntu16.04下Kylin的安装与配置
一.系统环境 kylin的安装配置并不像官方文档中描述的那样简单,复杂的原因在于hadoop,hive,hbase,kylin的版本一定要兼容,不然就会出现各种奇怪的错误.以下各软件版本可以成功运行k ...
- Ubuntu16.04下HBase的安装与配置
一.环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : mysql : hive : hbase: -hadoop2 安装HBase前,系统 ...
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
- ubuntu16.04下vim的安装与配置
一.安装vim 使用命令 $ sudo apt-get install vim 来安装vim,安装后的vim需要进行一些配置,不然使用起来会有些不方便,比如不会自动缩进. 二.配置vim 使用命令 ...
- Ubuntu16.04下,erlang安装和rabbitmq安装步骤
文章来源: Ubuntu16.04下,erlang安装和rabbitmq安装步骤 准备工作,先下载erlang和rabbitmq的安装包,注意他们的版本,版本不对可能会导致rabbitmq无法启动,这 ...
- Ubuntu 14.04 下 android studio 安装 和 配置【转】
本文转载自:http://blog.csdn.net/xueshanfeihu0/article/details/52979717 Ubuntu 14.04 下 android studio 安装 和 ...
- ubuntu16.04下源码安装onos1.0.2
由于工作需要,下载安装onos1.0.2的版本,大家看需求可以下载安装更高级的版本 参考链接:http://www.sdnlab.com/14650.html 1.系统环境 Ubuntu16.04 L ...
- ubuntu16.04下snort的安装(官方文档安装)(图文详解)
不多说,直接上干货! 最近为了科研,需要安装和使用Snort. snort的官网 https://www.snort.org/ Snort作为一款优秀的开源主机入侵检测系统,在windows和Linu ...
随机推荐
- Java HashMap源码分析
貌似HashMap跟ConcurrentHashMap是面试经常考的东西,抽空来简单分析下它的源码 构造函数 /** * Constructs an empty <tt>HashMap&l ...
- TPS低,CPU高--记一次storm压测问题排查过程
一.业务背景+系统架构 本次场景为kafka+storm+redis+hbase,通过kafka的数据,进入storm的spout组件接收,转由storm的Bolt节点进行业务逻辑处理,最后再推送进k ...
- 监控Elasticsearch的插件【check_es_system】
监控Elasticsearch的插件推荐 强大的shell脚本 #!/bin/bash ####################################################### ...
- java 根据二叉树前序 ,中序求后续
在一棵二叉树总,前序遍历结果为:ABDGCEFH,中序遍历结果为:DGBAECHF,求后序遍历结果. 我们知道: 前序遍历方式为:根节点->左子树->右子树 中序遍历方式为:左子树-> ...
- UCenter在JAVA项目中实现的单点登录应用实例
Comsenz(康盛)的UCenter当前在国内的单点登录领域占据绝对份额,其完整的产品线令UCenter成为了账号集成方面事实上的标准. 基于UCenter,可以将Comsenz旗下的Discuz! ...
- 可视化爬虫Portia安装和部署踩过的坑
背景 Scrapy爬虫的确是好使好用,去过scrapinghub的官网浏览一下,更是赞叹可视化爬虫的犀利.scrapinghub有一系列的产品,开源了大部分项目,Portia负责可视化爬虫的编辑,Sp ...
- HDU 2062 Subset sequence (找规律)
题目链接 Problem Description Consider the aggregate An= { 1, 2, -, n }. For example, A1={1}, A3={1,2,3}. ...
- Linux dig命令
dig(Domain Information Groper),和nslookup作用有些类似,都是DNS查询工具 1.dig命令格式 dig @dnsserver name querytype 如果你 ...
- Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
问题: 当我们打开数据库,即use dbname时,要预读数据库信息,当使用-A参数时,就不预读数据库信息. 解决方法:mysql -hhostname -uusername -ppassword - ...
- 2016.5.57—— Remove Duplicates from Sorted List
Remove Duplicates from Sorted List 本题收获: 指针: 不管什么指针在定义是就初始化:ListNode *head = NULL; 如果给head指针赋值为第一个no ...