real-Time Correlative Scan Matching
启发式算法(heuristic algorithm)是相对于最优化算法提出的。一个问题的最优算法求得该问题每个实例的最优解。启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。现阶段,启发式算法以仿自然体算法为主,主要有蚁群算法、模拟退火法、神经网络等
Abstract-we advocate a probabilistically-motivated(概率激发的) scan-matching algorithm that produces higher quality and more robust results at the cost of additional computation time.
We describe several novel implementations of this approach that achieve real-time performance on modern hardware, including a multi-resolution approach for conventional CPUs, and a parallel approach for
graphics processing units (GPUs).
The robustness of the methods make them especially useful for global loop-closing.
1.Introduction
Aside from being an interesting perceptual problem, scan matching is at the center of most navigation, mapping, and localization systems.
scan matching plays a central role in estimating the motion of the robot.
The primary challenge in designing a scan matcher is to minimize the runtime complexity while maximizing the quality (and robustness) of the solutions.
This paper describes a family of scan matching algorithms based upon cross-correlation of two lidar scans. Our approach casts the problem in a probabilistic framework: it finds the
rigid-body transformation that maximizes the probability of having observed the data.
Rather than trusting a local search algorithm to find the global maximum (an approach that does not work well in the presence of initialization noise, as we will illustrate),
we perform a search over the entire space of plausible rigid-body transformations. This plausible region is derived from a prior which, in turn, can be derived from the commanded motion or wheel/visual odometry.
The quality and robustness of our methods, coupled with their ability to operate in real-time, make them ideal for any robotic platform in which robustness and accuracy are of high importance.
II-Prior Work
Iterative Closest Point (ICP) [1], [2] and Iterative Closest Line (ICL) [3], [4], [5] are used pervasively in scan matching.Horn’s exact closed-form algorithm [6] is especially well suited to the task.
Our work is quite similar in spirit to Konolige’s correlation based localization approach [15]. While the formulations of the problem are almost identical, we describe new methods for computing the answers.
III APPROACH
A Probabilistic formulation
The central contribution of this paper is a method for efficiently computing the distribution p(z|x i , m) so that we can compute the posterior distribution of the robot’s position
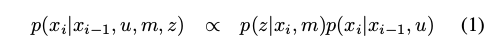
Our approach results in both a more robust maximum likelihood estimate and a principled uncertainty estimate.
Like previous work, we assume that each individual lidar return z j is independent,
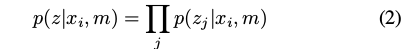
The probability distribution for a single lidar sample z j should, in principle, consider which surface of the map m would be visible from position x i along a particular bearing. This would require an expensive ray-casting type operation. Like others [15], we neglect visibility and occlusion effects, and approximate the probability of z j in terms of its distance from any surface in m.
B Lookup-Table Rasterization
The computation of the probability p(z|x i , m) can be accelerated by building a 2D lookup table. We follow the approach of previous approaches [18], [19] by pre-computing a lookup table containing log probabilities of lidar observation at each(x, y) position in the world(预先计算一个查找表,该表包含每一个雷达观测点在世界坐标系下的(x,y)所对应的对数概率).
Our rasterization(栅格化) process begins with map m.For each observable point m i in the map, we can the compute the conditional probability that the sensor observes a nearby point p given that m i was the cause of that observation.(栅格化过程以地图m开始,对于在地图中的每一个可观测的点mi,我们可以计算传感器观测到附近点p在给定mi的条件下的条件概率,mi是这个观测的原因)。
We repeat this process for each point in the map, recording the maximum probability for each point in the lookup table.
Since our lookup table must be viewpoint independent, we approximate the potentially banana-shaped distribution arising from the sensor model (which has independent range and bearing noise) as a radially-symmetric distribution.
we approximate the potentially banana-shaped distribution arising from the sensor model (which has independent range and bearing noise) as a radially-symmetric distribution.(我们近似这个来自于传感器模型的香蕉形状的分布作为一个径向对称的分布)
The resulting lookup table can be visualized as an image, as seen in Fig. 3.
光栅化:http://blog.csdn.net/u010356727/article/details/50594401
http://www.cnblogs.com/wantnon/p/4894597.html
A critical question is: “where does the model m come from?”,In rare cases, a model is known in advance [10],but more often, the model must be estimated from previousobservations of the environment.Estimating this model is a complex issue on its own, and in the limit, requires a full solution to the SLAM problem.
In this paper, we will simply use an earlier laser scan (the reference scan) as our model. This approach has the advantages of being easy to implement, robust (in that model cannotdiverge due to earlier data association errors), and perhaps most pragmatically, serves as a baseline implementation aiding replication of our results. More sophisticated implementations can build up more detailed models by combining multiple scans (e.g. CARMEN’s Vasco), or by extrapolating continuous surfaces from lidar points [4].
C.Approach Overview
our goal is to estimate the distribution p(z|x i , m),we are interested not only in the maximum likelihood value of p(x i |...), but the distribution itself so that we can obtain a measure of uncertainty.
There is no simple expression for this distribution:it must be evaluated numerically. In the following two sections, we will describe two algorithms for rapidly evaluating the distribution p(z|x i , m) over many values of x i .
D.Multi-Level Resolution Implementation
Our approach reflects this, attempting to minimize the number of evaluations required while 1) characterizing the distribution over a large area and 2) precisely locating the maximum likelihood value. We describe our approach in three pieces: building from a naive implementation towards our multi-resolution approach.
1)Brute Force(普通的模式匹配算法,BF算法):
In principle, we need to evaluate p(z|x i , m)over a three-dimensional volume of points; the three di-mensions correspond to the unknown parameters of T : ∆x,∆y, and θ. Our naive implementation consists of three nested loops; for each voxel, the probability is computed and recorded. The evaluation at a single voxel involves a fourth nested loop, iterating over each point in the query scan, projecting it, and looking up the cost in the lookup table. This method is quite slow, as our results sections illustrates.
2)Computing 2D Slices(先查找旋转角度,再查找平移量,能大量较少时间):
One of the reasons the brute-force method is slow is that the points in the query scan are reprojected for each voxel. This is unfortunate, since for a given value of θ, the projected query points are related by pure translation for the x̂ and ŷ search directions. In other words, a significant amount of computational time can be saved by iterating over θ in the outer-most loop at which time the query points are properly rotated. The inner two loops (for x̂ and ŷ) simply translate the query points. This operation can be made even faster by making the step size of the translational search match the resolution of the lookup table. This method is significantly faster than the brute force method, as illustrated in the results section.
3)Multi-Level Resolution(多层分辨率):
基于cpu实现的算法使用多分辨率的栅格查找表:高分辨率为3cm,低分辨率为30cm。
在非常低的分辨率下,参考帧中的细节可能消失。在计算低分辨率表时,其表中的每一个cell设置为高分辨率地图中对应cell的最大值。这使得由低分辨率地图计算的概率值至少总是跟高分辨率地图计算出来的概率值一样大。换句话说,保证了不会丢掉最大值。
策略是使用低分辨率地图来快速识别某区域是否包含全局最大值。目的是最小化在高分辨率下的搜索空间。方法是:
a、使用低分辨率表来对整个3D搜索窗口进行概率p(z/xi,m)估计.假设最大值发生在体素i上,用Li表示最大值。
b、使用高分辨率地图在体素i当中进行搜索。假设体素i的log似然为Hi。注意Hi小于等于Li,因为低分辨率地图对log似然估计过高。
c、在步骤1中计算的每一个低分辨率体素,其log似然至少是Hi,然后在高分辨率下估计该体素。如果有更好的log似然被找到则更新Hi。
d、在步骤3中通过高分辨率评估的所有体素的最大值是高分辨率率评估的所有搜索空间的最大值。
多分辨率方法非常快速,使得实时相关性扫描匹配称为可能,同样也非常鲁邦。
E、 Graphics Processor Approach(GPU处理方法)
F、Computing Covariances(协方差的计算)
在许多应用当中,xi的最大似然估计已经足够了。然而,本方法允许一个准则性的不确定的估计。
一旦代价函数的值在一系列xi值中被估计后,一个多维的高斯分辨可以被拟合进数据。xi的第j次被评估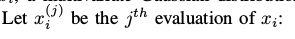
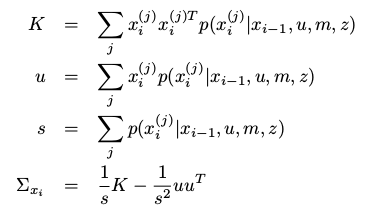
从计算的概率值p(z/xi,m)中估计扫描匹配器的不确定性要把以下两项主要的因素考虑进去:
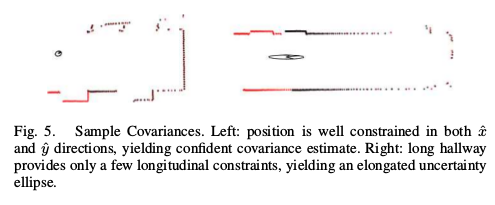
传感器本身的噪声,以及哪一个查询激光点应当对应到模型的那一部分的不确定性。本方法的缺点是产生的高斯只适合于已经计算过的样本。任何高可能的区域只要不在样本中,将不会在高斯中反应出来,导致过于自信的估计。因此,对xi的大区域进行概率估计p(z/xi,m)是很重要的,如下图,协方差估计的两个例子:

http://april.eecs.umich.edu.
real-Time Correlative Scan Matching的更多相关文章
- 【论文阅读记录】Real-Time Correlative Scan Matching
这篇文章是谷歌的Cartograph中实现real_time_correlative_scan_matcher的论文 Real-Time Correlative Scan MatchingEdwin ...
- cartographer 3D scan matching 理解
cartographer 3D scan matching没有论文和其它资料,因此尝试通过源码理解其处理方法,理解不当之处还请指正. 目录: 0.2D 匹配方法简介 1.real time corre ...
- 【High-Speed and Accurate Laser Scan Matching Using Classified Features】
所谓的"分类特征",就是把特征分成 1. 旋转特征:用直线表示 2. 平移特征,用撕裂点和临界点表示 最大的创新点 应该就是下面的分组吧 匹配的时候,用RANSAC 或者动态规划, ...
- 【A Global Line Matching Algorithm for 2D Laser Scan Matching in Regular Environment】
只看了前面的部分,灭有看实验,觉得整体风格比较傻白甜,与我的想法不谋而合.简单明了,用起来应该比较方便. 初步探测:如果有直线,就给线性插值一下. 分级聚类:利用简单的阈值给聚类了一下,分成了段段. ...
- cartographer 分析
原文链接:http://blog.csdn.net/zyh821351004/article/details/52421005 cartographer与karto的比较 1. 两者采取的都是图优化框 ...
- SLAM(二)----学习资料下载
有位师兄收集了很多slam的学习资料, 做的很赞, 放到了github上, 地址:https://github.com/liulinbo/slam.git ruben update 0823 2016 ...
- [SLAM]Karto SLAM算法学习(草稿)
Karto_slam算法是一个Graph based SLAM算法.包括前端和后端.关于代码要分成两块内容来看. 一类是OpenKarto项目,是最初的开源代码,包括算法的核心内容: https:// ...
- [SLAM] GMapping SLAM源码阅读(草稿)
目前可以从很多地方得到RBPF的代码,主要看的是Cyrill Stachniss的代码,据此进行理解. Author:Giorgio Grisetti; Cyrill Stachniss http: ...
- 点云匹配和ICP算法概述
Iterative Closest Point (ICP) [1][2][3] is an algorithm employed to minimize the difference between ...
随机推荐
- 简述FPGA项目之前的一些事
FPGA的设计是一个系统工程,是一种道,会编程会仿真会调试可能更多是一种术.很多这方面的书籍,写什么自顶向下之类的很多,还是停留在方法学上,而对于一个公司的项目来说,FPGA的设计是从立项开始的. 拿 ...
- Appium+python自动化23-Android夜神模拟器
前言 Android SDK虽然也自带了模拟器,但是那速度会让你怀疑人生,并且不稳定经常卡死异常.夜神模拟器可以说是android模拟器里面的一个神器. 环境安装 1.官网下载地址:https://w ...
- SpringMVC之五:自定义DispatcherServlet配置及配置额外的 servlets 和 filters
相关文章 <Servlet3.0之四:动态注册和Servlet容器初始化> <SpringBoot中通过SpringBootServletInitializer如何实现组件加载> ...
- [Java][Web]Web 工程中的各类地址的写法
// 1. request.getRequestDispatcher("/index.html").forward(request,response); // 以 / 开头,对于浏 ...
- SCI 美国《科学引文索引》(Science Citation Index, 简称 SCI )
科学引文索引 编辑锁定同义词SCI(科学引文索引)一般指科学引文索引 美国<科学引文索引>(Science Citation Index, 简称 SCI )于1957 年由美国科学信息 ...
- css/css3实现未知宽高元素的垂直居中和水平居中
题目:.a{ width: 200px; height: 200px; background-color: #ccc;} <body> <div class="a" ...
- adb命令检测apk启动时间、内存、CPU使用情况、流量、电池电量等——常用的adb命令
ADB:Android Debug Bridge,是Android SDK里一个可以直接操作安卓模拟器或真实设备的工具,颇为强大. 检测APP: adb shell am start -W p ...
- ReportMachine 打印机横向
Portrait 纵向 landscape 横向 RM_reg.pas :TRMPageSetupForm 打印机设置RM_PageSetup.dfm TRMPageSetting定义在RM_Pri ...
- 【源码阅读】Java集合之一 - ArrayList源码深度解读
Java 源码阅读的第一步是Collection框架源码,这也是面试基础中的基础: 针对Collection的源码阅读写一个系列的文章,从ArrayList开始第一篇. ---@pdai JDK版本 ...
- 【Consul】Consul实践指导-配置文件
Agent有各种各样的配置选项,这些配置选项可以通过命令行参数的方式设定,也可用通过配置文件的方式设定--所有的配置选项都是可选的,当然也是有默认值的. 当加载配置选项时,consul是按照词典顺序从 ...