Python编程中 re正则表达式模块 介绍与使用教程
Python编程中 re正则表达式模块 介绍与使用教程
一、前言:
这篇文章是因为昨天写了一篇 shell script 的文章,在文章中俺大量调用多媒体素材与网址引用。这样就会有一个问题就是:随着俺的技能的提高,需要类比的、引用的、整理的就会越来越多。这样会出现一个问题就是 针对 url 做一个全面的检查,保证所有链接读者都可以打开。嗯,就是这样的一个轮子。目前计划先是 **re模块找到url链接,requests 模块再进行源码爬取与判断 。后面再升级的话可以考虑修复链接的错误,更强可以再修复文档中各种错误(这些就是后话了)。为啥会写这篇文章呢?俺觉得网上很多人都是抄袭或没有实战经验,写的东西不容易懂也不容易被利用 **。正好现在俺在造轮子,那就参考参考权威资料和几位前辈的美文,动动手,写篇 re模块 的详细介绍。
二、介绍:
I、正则表达式
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用**单个字符串来描述、匹配一系列匹配某个句法规则的字符串 **。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。——摘自维基百科
文字表达式全集 (番茄) 正则表达式语法(IBM) 图片表达式全集 Regular Expression Syntax
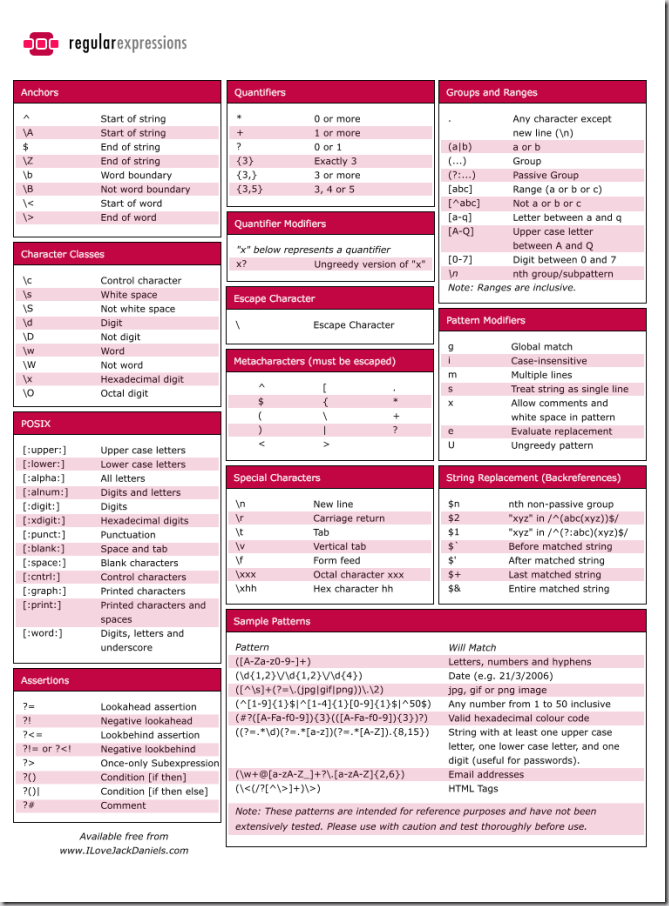{kind=link}
II、re 模块
This module provides regular expression matching operations similar to those found in Perl. ——摘自官方手册
Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使用这一内嵌于 Python 的语言工具,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。Python 会将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配。——摘自IBM
In [9]: print(str(len(re.__all__))+" 个子模块")
27 个子模块
In [10]: print(re.__all__)
['match', 'fullmatch', 'search', 'sub', 'subn', 'split', 'findall', 'finditer', 'compile', 'purge', 'template', 'escape', 'error', 'A', 'I', 'L', 'M', 'S', 'X', 'U', 'ASCII', 'IGNORECASE', 'LOCALE', 'MULTILINE', 'DOTALL', 'VERBOSE', 'UNICODE']
三、约定:
1、反斜杠
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
2、匹配模式
re 所定义的 flag 包括:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为’ . ’并且包括换行符在内的任意字符(’ . ’不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和’ # ’后面的注释
3、条件返回值
In [30]: a='afoaisfoasnfo'
In [31]: if re.match(r'[a-z]*',a):
...: print('It\'s Ture')
...:
It's Ture
四、使用:

I、re.compile
将正则表达式(以字符串书写的)转换为模式对象,供 match() 和 search() 这两个函数使用,可以实现更有效率的匹配。
re.compile(pattern[, flags])

# 如果在调用 match 或 search 函数时,使用字符串表示的正则表达式,它们会在内部将字符串转换成正则表示式对象。但是如果使用了compile 进行一次转换之后,在每次使用模式的时候就不需要再次进行转换。(没有特殊情况基本不用会比较麻烦)
# 例:以下两种用法结果相同:
# A)
compiled_pattern = re.compile(pattern)
result = compiled_pattern.match(string)
# B)
result = re.match(pattern, string)
II、re.search
在字符串中查找匹配正则表达式模式的位置,**一旦找到子字符串 **返回 MatchObject 的实例(值为True),否则返回 None(值为False)。
re.search(pattern, string[, flags])
# 例:以下代码为俺的半成品项目
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.search(r'(ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/)',doc_files.read())
# 千万注意,search() 函数是扫描整个字符串来查找匹配。一旦使用了 re.search 找到了第一个符合的字符串会立刻停止查找。
III、re.march
从字符串开头位置开始匹配正则表达式,match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是只报告从位置 0 开始的匹配情况。
re.match(pattern, string[, flags])
# 如果想要搜索整个字符串来寻找匹配,应当用 search()。
# 例:
In [79]: if re.match('a','www.python.org')==None: print('Match False')
Match False
In [80]: if re.match('w','www.python.org')==None: print('Match False')
In [81]: if re.match('ww','www.python.org')==None: print('Match False')
IIII、re.split
可以将字符串匹配正则表达式的匹配项来切割字符串并返回一个列表。
re.split(pattern, string[, maxsplit=0, flags=0])
In [85]: modleText='this is the test'
In [86]: print(modleText.split(' '))
['this', 'is', 'the', 'test']
In [87]: print(re.split(' ',modleText))
['this', 'is', 'the', 'test']
V、re.findall
在字符串中找到正则表达式所匹配的所有子串,返回给定模式的所有匹配项并组成一个列表返回。
re.findall(pattern, string[, flags])
# 实例1
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.findall(r'(ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/)',doc_files.read())
> python lsurl.py
Please Input The Path About Documents: c:\users\rabbit\Desktop\example.txt
[('ht', 'tp', '', '://', '', '/'), ('ht', 'tp', 's', '://', ':2121', '/')]
# 实例2(给正则加上了括号)
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.findall(r'((ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/))',doc_files.read())
> python lsurl.py
Please Input The Path About Documents: c:\users\rabbit\Desktop\example.txt
[('http://c.example.net/', 'ht', 'tp', '', '://', '', '/'), ('https://ira.be.me:2121/', 'ht', 'tp', 's', '://',
:2121', '/')]
VI、re.sub
使用给定的替换内容将匹配模式的字符串替换掉。在字符串 string 中找到匹配正则表达式 pattern 的所有子串,用另一个字符串 repl 进行替换。如果没有找到匹配 pattern 的串,则返回未被修改的 string。repl 既可以是字符串也可以是一个函数。
re.sub(pattern, repl, string[, count, flags])
In [91]: help(re.sub)
Help on function sub in module re:
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.
In [92]: re.sub('(is|this)','sub','this is contect')
Out[92]: 'sub sub contect'
In [93]: re.sub('(is|this)','sub','this is contect',count=1)
Out[93]: 'sub is contect'
----------------
In [94]: p = re.compile( '(one|two|three)')
In [95]: p.sub( 'num', 'one word two words three words')
Out[95]: 'num word num words num words'
In [96]: p.subn( 'num', 'one word two words three words')
# 该函数的功能和 sub() 相同,但它还返回新的字符串以及替换的次数。
Out[96]: ('num word num words num words', 3)
VII、re.escape
它可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。
re.escape(pattern)
In [99]: re.escape('https://cdn.itxdm.com')
Out[99]: 'https\\:\\/\\/irabe\\.me'
In [100]: re.escape('https://www.itxdm.com')
Out[100]: 'https\\:\\/\\/www\\.itxdm\\.com'
相关主题:
引用维基百科:https://zh.wikipedia.org/wiki/正则表达式/
参考IBM一文:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonre/index.html
参考 "Python基础教程" 一书
推荐后续阅读1:https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
推荐后续阅读2:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonre/index.html
Python编程中 re正则表达式模块 介绍与使用教程的更多相关文章
- Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块 欢迎加入Linux_Python学习群 群号:478616847 目录: 模块与导入介绍 包的介绍 time &datetime模块 rando ...
- 简学Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块 欢迎加入Linux_Python学习群 群号:478616847 目录: 模块与导入介绍 包的介绍 time &datetime模块 rando ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
- 解析Python编程中的包结构
解析Python编程中的包结构 假设你想设计一个模块集(也就是一个"包")来统一处理声音文件和声音数据.通常由它们的扩展有不同的声音格式,例如:WAV,AIFF,AU),所以你可能 ...
- 详解Python编程中基本的数学计算使用
详解Python编程中基本的数学计算使用 在Python中,对数的规定比较简单,基本在小学数学水平即可理解. 那么,做为零基础学习这,也就从计算小学数学题目开始吧.因为从这里开始,数学的基础知识列位肯 ...
- Python编程中NotImplementedError的使用
Python编程中raise可以实现报出错误的功能,而报错的条件可以由程序员自己去定制.在面向对象编程中,可以先预留一个方法接口不实现,在其子类中实现.如果要求其子类一定要实现,不实现的时候会导致问题 ...
- Python学习笔记6-Python中re(正则表达式)模块学习
今天学习了Python中有关正则表达式的知识.关于正则表达式的语法,不作过多解释,网上有许多学习的资料.这里主要介绍Python中常用的正则表达式处理函数. re.match re.match 尝试从 ...
- python之路8-内置模块介绍
time & datetime模块 1 #_*_coding:utf-8_*_ 2 __author__ = 'Alex Li' 3 4 import time 5 6 7 # print(t ...
随机推荐
- vuejs 2.0 键盘事件
<!DOCTYPE html> <html> <head> <title></title> <meta charset="u ...
- Avro总结(RPC/序列化)
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人,膜拜)牵头开发,当前最新版本1.3.3.Avr ...
- Renderer.materials 和sharedMaterials一些用法上的区别
Not allowed to access Renderer.materials on prefab object. Use Renderer.sharedMaterials insteadUnity ...
- dll详解
[转]http://www.cnblogs.com/xuemaxiongfeng/articles/2461632.html 不解为什么要用WINAPI宏定义,查了后发现下面的定义.于是乎需要区别 _ ...
- [C++] 2D Array's memory allocation
2D Array's memory allocation
- hdu 2049 不容易系列之(4)——考新郎 (错排递推)
当n个编号元素放在n个编号位置,元素编号与位置编号各不对应的方法数用M(n)表示,那么M(n-1)就表示n-1个编号元素放在n-1个编号位置,各不对应的方法数,其它类推. 第一步,把第n个元素放在一个 ...
- sklearn中的随机森林
阅读了Python的sklearn包中随机森林的代码实现,做了一些笔记. sklearn中的随机森林是基于RandomForestClassifier类实现的,它的原型是 class RandomFo ...
- 37 有n个人围成一圈,顺序排号,从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号那位.
题目:有n个人围成一圈,顺序排号,从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号那位. public class _037NumberOff { public st ...
- 如何快速增加pdf书签,解除pdf限制
一.需要的工具 福昕PDF阅读器 Foxit PDF Editor 2.2.1 build 1119 汉化版 下载地址:http://www.onlinedown.net/soft/51002.htm ...
- MySQL中如何为查询的数据添加自增序号、顺序呢?
背景介绍 很多时候我们在使用mysql查询数据的时候都会遇到一个问题,就是查询出来了一堆数据,但是查询的数据的表并没有序号,然而部分数据库显示工具是有外带序号显示,但是这种序号不是由sql产生的,而是 ...