spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)
问题
datafrme提供了强大的JOIN操作,但是在操作的时候,经常发现会碰到重复列的问题。在你不注意的时候,去用相关列做其他操作的时候,就会出现问题!
假如这两个字段同时存在,那么就会报错,如下:org.apache.spark.sql.AnalysisException: Reference 'key2' is ambiguous
实例
1.创建两个df演示实例
val df = sc.parallelize(Array(
("yuwen", "zhangsan", 80), ("yuwen", "lisi", 90), ("shuxue", "zhangsan", 90), ("shuxue", "lisi", 95)
)).toDF("course", "name", "score")
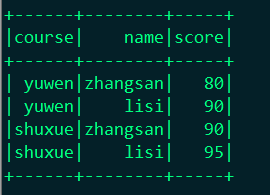
显示:df.show()
val df2 = sc.parallelize(Array(
("yuwen", "zhangsan", 90), ("shuxue", "zhangsan", 100)
)).toDF("course", "name", "score")
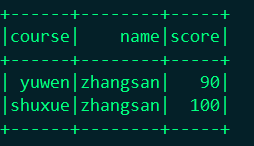
显示:df2.show
关联查询:
val joined = df.join(df2, df("cource") === df2("cource") && df("name") === df2("name"), "left_outer")
结果展示:

这时候问题出现了这个地方出现了三个两两相同的字段,当你在次操作这个字段的时候就出问题了。

解决问题
1.你可以使用的时候指定你要用哪个df里面的字段
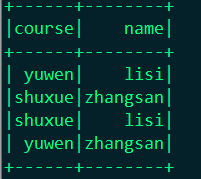
joined.select(df("course"),df("name")).show
结果:
2.你可以删除多余的列,在实际情况中你不可能将两张完全一样的表进行关联,一般就几个字段的名字相同,这样你可以删除你不需要的字段
joined.drop(df2("name"))
结果:

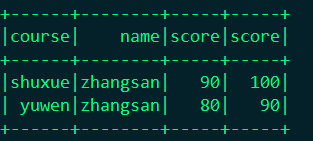
3.就是通过修改JOIN的表达式,完全可以避免这个问题。主要是通过Seq这个对象来实现
df.join(df2, Seq("course", "name")).show()
结果:
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)的更多相关文章
- spark org.apache.spark.ml.linalg.DenseVector cannot be cast to org.apache.spark.ml.linalg.SparseVector
在使用 import org.apache.spark.ml.feature.VectorAssembler 转换特征后,想要放入 import org.apache.spark.mllib.clas ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- Spark之join、leftOuterJoin、rightOuterJoin及fullOuterJoin
Spark的join与mysql的join类似,mysql的join是将表与表之间连接查询,spark中join是将RDD数据集进行连接,Spark主要有join.leftOuterJoin.righ ...
- Apache Spark 2.2.0 中文文档
Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN Geekhoo 关注 2017.09.20 13:55* 字数 2062 阅读 13评论 0喜欢 1 快速入门 使用 ...
- Apache Spark 2.2.0 中文文档 - Spark 编程指南 | ApacheCN
Spark 编程指南 概述 Spark 依赖 初始化 Spark 使用 Shell 弹性分布式数据集 (RDDs) 并行集合 外部 Datasets(数据集) RDD 操作 基础 传递 Functio ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- [错误]Caused by: org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0
今天,在运行Spark SQL代码的时候,遇到了以下错误: Caused by: org.apache.spark.SparkException: Job aborted due to stage f ...
- Apache Spark大数据分析入门(一)
摘要:Apache Spark的出现让普通人也具备了大数据及实时数据分析能力.鉴于此,本文通过动手实战操作演示带领大家快速地入门学习Spark.本文是Apache Spark入门系列教程(共四部分)的 ...
随机推荐
- Angular 组件与模板 - 属性指令
指令概览 在 Angular 中有三种类型的指令: 组件 — 拥有模板的指令 结构型指令 — 通过添加和移除 DOM 元素改变 DOM 布局的指令 属性型指令 — 改变元素.组件或其它指令的外观和行为 ...
- 配置使用TargetFrameworks输出多版本类库
1.类库右键 2.修改配置 修改前: <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <Targe ...
- 分页技巧_改进JSP页面中的公共分页代码_实现分页时可以有自定义的过滤与排序条件
分页技巧__改进JSP页面中的公共分页代码 自定义过滤条件问题 只有一个url地址不一样写了很多行代码 public>>pageView.jspf添加 分页技巧__实现分页时可以有自定义的 ...
- 虚拟机中Lvs配置
参考:http://zh.linuxvirtualserver.org/node/272 环境,三台centos 5.2.基于ipvsadm的负载均衡,采用DR方式,负载均衡的服务是web. 内核版本 ...
- Django学习笔记第十二篇--关于自定义数据库字段数据类型
一.需求背景: django的models模块提供了很多数据字段的数据类型field,但是总有写奇葩需求不能依靠默认字段满足,所以需要自定义数据数据库数据字段类型.所有的自定义field应该在app路 ...
- WEB安全番外第三篇--关于XXE
一.什么是XXE 1.XML实体简介 (1)在一段时间中,XML都是WEB信息传输的主要方法,时至今日XML在WEB中作为前后台之间传递数据的结构,依然发挥着重要的作用.在XML中有一种结构叫做实体: ...
- Android StaggeredGrid 加下拉刷新功能 PullToRefresh
https://github.com/etsy/AndroidStaggeredGrid 用的github上面提供瀑布流,继承于abslistview,回收机制不错,并且提供了OnScrollLis ...
- 逐一取Map值
String[] mKeys = starDetil.getRows().keySet().toArray(new String[starDetil.getRows().size()]); starD ...
- java利用反射机制获取list中的某个字段并以list形式返回
public static<T> List<Object> listToList(Collection<T> list,String fieldName) thro ...
- Ubuntu 16.04 安装 Phpmyadmin 出现的问题及解决
ubuntu 16.04 install phpmyadmin $ apt install phpmyadmin 安装时出现一个错误: An error occurred while installi ...