Python之路——线程池
1 线程基础
1.1 线程状态
线程有5种状态,状态转换的过程如下图所示:

1.2 线程同步——锁
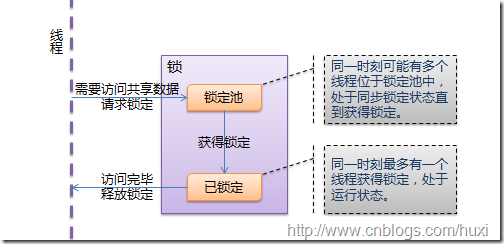
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样,其实Python中是伪多线程)。但是当线程需要共享数据时,可能存在数据不同步的问题。考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态—锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。经过这样的处理,打印列表时要么全部输出0, 要么全部输出1,不会再出现一半0一半1的尴尬场面。
线程与锁的交互如下图所示:
1.3 线程通信(条件变量)
然而还有另外一种尴尬的情况:列表并不是一开始就有的;而是通过线程"create"创建 的。如果"set"或者"print" 在"create"还没有运行的时候就访问列表,将会出现一个异常。使用锁可以解决这个问题,但是"set"和"print"将需要一个无限循环——他们不知道"create"什么时候会运行,让"create"在运行后通知"set"和"print"显然是一个更好的解决方案。于是,引入了条件变量。
条件变量允许线程比如"set"和"print"在条件不满足的时候(列表为None时)等待,等到条件满足的时候(列表已经创建)发出一个通知,告诉"set" 和"print"条件已经有了,你们该起床干活了;然后"set"和"print"才继续运行。
线程与条件变量的交互如下图所示:


1.4 线程运行和阻塞的状态转换
最后看看线程运行和阻塞状态的转换。

阻塞有三种情况:
同步阻塞是指处于竞争锁定的状态,线程请求锁定时将进入这个状态,一旦成功获得锁定又恢复到运行状态;
等待阻塞是指等待其他线程通知的状态,线程获得条件锁定后,调用“等待”将进入这个状态,一旦其他线程发出通知,线程将进入同步阻塞状态,再次竞争条件锁定;
而其他阻塞是指调用time.sleep()、anotherthread.join()或等待IO时的阻塞,这个状态下线程不会释放已获得的锁定。
2 多线程
为充分利用cpu资源,减少资源浪费,Python中也提供了多线程技术,但由于存在GIL的关系,实际上同一时刻只存在一个线程在执行,即Python中不存在真正意义上的多线程,但是多线程技术还是提高了CPU资源的利用率,所以还是很有价值的。
3 线程池
我们知道系统处理任务时,需要为每个请求创建和销毁对象。当有大量并发任务需要处理时,再使用传统的多线程就会造成大量的资源创建销毁导致服务器效率的下降。这时候,线程池就派上用场了。线程池技术为线程创建、销毁的开销问题和系统资源不足问题提供了很好的解决方案。
3.1 优点:
(1)可以控制产生线程的数量。通过预先创建一定数量的工作线程并限制其数量,控制线程对象的内存消耗。
(2)降低系统开销和资源消耗。通过对多个请求重用线程,线程创建、销毁的开销被分摊到了多个请求上。另外通过限制线程数量,降低虚拟机在垃圾回收方面的开销。
(3)提高系统响应速度。线程事先已被创建,请求到达时可直接进行处理,消除了因线程创建所带来的延迟,另外多个线程可并发处理。
“池”的概念使得人们可以定制一定量的资源,然后对这些资源进行复用,而不是频繁的创建和销毁。
3.2 注意事项
虽然线程池是构建多线程应用程序的强大机制,但使用它并不是没有风险的。在使用线程池时需注意线程池大小与性能的关系,注意并发风险、死锁、资源不足和线程泄漏等问题。
1、线程池大小。多线程应用并非线程越多越好,需要根据系统运行的软硬件环境以及应用本身的特点决定线程池的大小。一般来说,如果代码结构合理的话,线程数目与CPU 数量相适合即可。如果线程运行时可能出现阻塞现象,可相应增加池的大小;如有必要可采用自适应算法来动态调整线程池的大小,以提高CPU 的有效利用率和系统的整体性能。
2、并发错误。多线程应用要特别注意并发错误,要从逻辑上保证程序的正确性,注意避免死锁现象的发生。
3、线程泄漏。这是线程池应用中一个严重的问题,当任务执行完毕而线程没能返回池中就会发生线程泄漏现象。
3.3 线程池设计的关键点
1、取任务数与线程数的最小值来决定开启线程的数量,即min(任务数,线程数);
2、当前线程池中线程的状态,即正在运行的线程数量和正在等待的线程数量;
3、关闭线程。
#!/usr/bin/env python
#-*- coding:utf-8 -*- import Queue
import threading
import time '''
要点:
1、利用Queue队列特性,将创建的线程对象放入队列中;
2、当执行任务时,从queue队列中取线程执行任务;
3、当任务执行完毕后,线程放回线程池
''' #线程池类
class ThreadPool(object):
def __init__(self,max_thread=20): #默认最大线程数为20
self.queue = Queue.Queue(max_thread) #创建队列,大小为max_thread
#把线程对象(线程类名)加入到队列中,此时并没有创建线程对象,只占用很小内存
for i in xrange(max_thread):
self.queue.put(threading.Thread) #注意此处是类名,如果这里self.queue.put(threading.Thread())(即把创建的对象放入队列中),那么每次都要在内存中开辟空间,这样内存浪费很大 def get_thread(self):#从队列里获取线程
return self.queue.get() def add_thread(self):#在队列里添加线程
self.queue.put(threading.Thread) #注意此处是类名 pool = ThreadPool(10) #创建大小为10的线程池 #任务函数
def func(arg,p):
print arg
time.sleep(2)
p.add_thread() #当前线程执行完,在队列里增加一个线程 for i in xrange(300):
#获取队列中的线程对象(此时线程对象还没创建),默认queue.get(),如果队列里没有线程就会阻塞等待。
thread = pool.get_thread()
t = thread(target=func,args=(i,pool)) #此时才真正创建线程对象,并传递参数
t.start() #开启线程 '''
for i in xrange(300):
thread = pool.get_thread()
t = thread(target=func,args=(i,pool))
t.start()
在threading.Thread的构造函数中:self.__args = args self.__target = target #当然也可以通过下面方法赋值,但是不推荐(对于私有字段,一般建议在构造函数中传参赋值)
for i in xrange(300):
ret = pool.get_thread()
ret._Thread__target = func
ret._Thread__args = (i,pool)
ret.start()
'''
简单线程池
3.4 复杂线程池预备知识
#!/usr/bin/env python
#-*- coding:utf-8 -*- import Queue obj = object() #先创建一个object对象obj
q = Queue.Queue() #创建队列 #把obj对象放入队列,注意此处与上述例子中的区别,上例是每次都创建对象,那么每个对象都会占用内存;
#而此处是先创建对象,再把此对象加入队列,即对象只创建了1次,而队列中加入了10次,那么对象只会占用一份内存
for i in range(10):
q.put(obj) for i in range(10):
print id(q.get()) #实验结果是此处id完全相同
预备知识1-占用内存优化
#!/usr/bin/env python
#-*- coding:utf-8 -*- import contextlib
import threading
import time
import random doing = [] #线程列表 #打印正在运行的线程个数函数
def num(l2):
while True:
print len(l2)
time.sleep(1) #单独创建一个线程,用于打印当前正在运行的线程数量
t = threading.Thread(target=num,args=(doing,))
t.start() #管理上下文的装饰器
@contextlib.contextmanager
def show(l1,item):
l1.append(item) #把正在执行的当前线程加入列表
yield #运行到此处,程序就会跳出当前函数,去执行with关键字中的内容,执行完后在进入当前函数执行
l1.remove(item) #当前线程执行完成后,则从列表中移除 #任务函数
def task(i):
flag = threading.current_thread()
with show(doing,flag): #with管理上下文,进行切换
print len(doing)
time.sleep(random.randint(1,4)) #等待 for i in range(20): #创建20个线程
temp = threading.Thread(target=task,args=(i,))
temp.start()
预备知识2-with上下文管理
更多with上下文管理知识请参考:
http://www.cnblogs.com/alan-babyblog/p/5153343.html
http://www.cnblogs.com/alan-babyblog/p/5153386.html
3.5 twisted源码中经典线程池的实现
#!/usr/bin/env python
#-*- coding:utf-8 -*- from Queue import Queue
import contextlib
import threading WorkerStop = object() class ThreadPool:
workers = 0
threadFactory = threading.Thread #类名
currentThread = staticmethod(threading.currentThread) #静态方法 def __init__(self, maxthreads=20, name=None):
self.q = Queue(0) #创建队列,参数0表示队列大小不限,队列用于存放任务
self.max = maxthreads #定义最大线程数
self.name = name
self.waiters = [] #存放等待线程的列表
self.working = [] #存放工作线程的列表 def start(self):
needSize = self.q.qsize() #获取任务所需的线程数
while self.workers < min(self.max, needSize): #wokers初始值为0
self.startAWorker() #调用开启线程的方法 def startAWorker(self):
self.workers += 1 #workers自增1
newThread = self.threadFactory(target=self._worker, name='test') #创建1个线程并去执行_worker方法
newThread.start() def callInThread(self, func, *args, **kw):
self.callInThreadWithCallback(None, func, *args, **kw) def callInThreadWithCallback(self, onResult, func, *args, **kw):
o = (func, args, kw, onResult) #把参数组合成元组
self.q.put(o) #把任务加入队列 #上下文管理装饰器
@contextlib.contextmanager
def _workerState(self, stateList, workerThread):
stateList.append(workerThread) #把当前执行线程加入线程状态类表stateList
try:
yield
finally:
stateList.remove(workerThread) #执行完后移除 def _worker(self):
ct = self.currentThread() #获取当前线程id
o = self.q.get() #队列中获取执行任务 while o is not WorkerStop: #当获取的o不是workstop信号时,执行while循环
with self._workerState(self.working, ct): #上下文切换
function, args, kwargs, onResult = o #元组分别赋值给变量
del o #删除元组o
try:
result = function(*args, **kwargs)
success = True
except:
success = False
if onResult is None:
pass
else:
pass del function, args, kwargs if onResult is not None:
try:
onResult(success, result)
except:
#context.call(ctx, log.err)
pass del onResult, result with self._workerState(self.waiters, ct):
o = self.q.get() #获取任务 def stop(self): #关闭线程
while self.workers: #循环workers
self.q.put(WorkerStop) #在队列中增加一个信号~
self.workers -= 1 #workers值-1,直到所有线程关闭 def show(arg):
import time
time.sleep(1)
print arg pool = ThreadPool(10) #创建500个任务,队列里添加500个任务
#每个任务都是一个元组(方法名,动态参数,动态参数,默认为NoNe)
for i in range(100):
pool.callInThread(show, i) pool.start() #开启执行任务 pool.stop() #执行关闭线程方法
twisted中经典线程池的实现-部分代码
参考资料:
http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
http://www.cnblogs.com/wupeiqi/articles/4839959.html
Python之路——线程池的更多相关文章
- python day 20: 线程池与协程,多进程TCP服务器
目录 python day 20: 线程池与协程 2. 线程 3. 进程 4. 协程:gevent模块,又叫微线程 5. 扩展 6. 自定义线程池 7. 实现多进程TCP服务器 8. 实现多线程TCP ...
- 『Python』 ThreadPool 线程池模板
Python 的 简单多线程实现 用 dummy 模块 一句话就可以搞定,但需要对线程,队列做进一步的操作,最好自己写个线程池类来实现. Code: # coding:utf-8 # version: ...
- Python 多线程和线程池
一,前言 进程:是程序,资源集合,进程控制块组成,是最小的资源单位 特点:就对Python而言,可以实现真正的并行效果 缺点:进程切换很容易消耗cpu资源,进程之间的通信相对线程来说比较麻烦 线程:是 ...
- python爬虫之线程池和进程池
一.需求 最近准备爬取某电商网站的数据,先不考虑代理.分布式,先说效率问题(当然你要是请求的太快就会被封掉,亲测,400个请求过去,服务器直接拒绝连接,心碎),步入正题.一般情况下小白的我们第一个想到 ...
- python小demo-01: 线程池+多进程实现cpu密集型操作
起因: 公司有一个小项目,大概逻辑如下: 服务器A会不断向队列中push消息,消息主要内容是视频的地址,服务器B则需要不断从队列中pop消息,然后将该视频进行剪辑最终将剪辑后的视频保存到云服务器.个人 ...
- 【Python】多线程-线程池使用
1.学习目标 线程池使用 2.编程思路 2.1 代码原理 线程池是预先创建线程的一种技术.线程池在还没有任务到来之前,创建一定数量的线程,放入空闲队列中.这些线程都是处于睡眠状态,即均为启动,不消耗 ...
- python之路----线程
线程概念的引入背景 进程 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本:进程 ...
- python爬虫14 | 就这么说吧,如果你不懂python多线程和线程池,那就去河边摸鱼!
你知道吗? 在我的心里 你是多么的重要 就像 恩 请允许我来一段 freestyle 你们准备好了妹油 你看 这个碗 它又大又圆 就像 这条面 它又长又宽 你们 在这里 看文章 觉得 很开心 就像 我 ...
- Python爬虫之线程池
详情点我跳转 关注公众号"轻松学编程"了解更多. 一.为什么要使用线程池? 对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控,例如,整站爬虫,假设初 ...
随机推荐
- Object Slicing in C++
In C++, a derived class object can be assigned to base class, but the other way is not possible. cla ...
- 说说M451例程之PWM
/**************************************************************************//** * @file main.c * @ve ...
- 【BZOJ3425】Poi2013 Polarization 猜结论+DP
[BZOJ3425]Poi2013 Polarization Description 给定一棵树,可以对每条边定向成一个有向图,这张有向图的可达点对数为树上有路径从u到达v的点对(u,v)个数.求最小 ...
- Thymeleaf模板如何获取springMVC返回的model值
Thymeleaf模板如何获取springMVC返回的model值 后台的实现: @RequestMapping("/hello") public String hello(Mod ...
- LeetCode 笔记系列一 Median of Two Sorted Arrays
题目:There are two sorted arrays A and B of size m and n respectively. Find the median of the two sort ...
- MySQL按照汉字的拼音排序、按照首字母分类
项目中有时候需要按照汉字的拼音排序,比如联系人列表.矿物分类等,有的还需要按拼音字母从A到Z分类显示. 如果存储汉字的字段编码使用的是GBK字符集,因为GBK内码编码时本身就采用了拼音排序的方法(常用 ...
- ubuntu中vi编辑器键盘错乱的问题
Ubuntu安装完成后vi编辑器键盘不能正常使用,使用下面方法解决: 编辑文件/etc/vim/vimrc.tiny,将“compatible”改成“nocompatible”非兼容模式: 并添加一句 ...
- var ie = !-[1,], [^\x00-\xff]
var ie = !-[1,]: 这句代码在IE9之前曾被称为世界上最短的IE判定代码.代码虽短但确包含了不少javascript基础知识在里面.在这个例子中代码执行时会先调用数组的toString( ...
- 《Django By Example》第十二章(终章) 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第十二章,全书最后一章,终于到这章 ...
- CLR via 笔记 5.3 值类型的装箱和拆箱
1.装箱 为了将一个值类型转换成一个引用类型,要使用一个名为装箱(Boxing)的机制. 1.在托管堆中分配好内存.分配的内存量是值类型的各个字段需要的内存量加上托管堆的所有对象都有的两个额外成员(类 ...