【网络优化】Batch Normalization(inception V2) 论文解析(转)
前言
懒癌翻了,这篇不想写overview了,公式也比较多,今天有(zhao)点(jie)累(kou),不想一点点写latex啦,读论文的时候感觉文章不错,虽然看似很多数学公式,其实都是比较基础的公式,文章也比较细,从网上找了两篇较好的讲解,引用连接在每篇文章前面。
文章1
https://www.cnblogs.com/guoyaohua/p/8724433.html#undefined
Batch Normalization作为最近一年来DL的重要成果,已经广泛被证明其有效性和重要性。虽然有些细节处理还解释不清其理论原因,但是实践证明好用才是真的好,别忘了DL从Hinton对深层网络做Pre-Train开始就是一个经验领先于理论分析的偏经验的一门学问。本文是对论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》的导读。
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
接下来一步一步的理解什么是BN。
为什么深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢?这是个在DL领域很接近本质的好问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network,BN本质上也是解释并从某个不同的角度来解决这个问题的。
一、“Internal Covariate Shift”问题
从论文名字可以看出,BN是用来解决“Internal Covariate Shift”问题的,那么首先得理解什么是“Internal Covariate Shift”?
论文首先说明Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;(为什么要说这些?因为BatchNorm是基于Mini-Batch SGD的,所以先夸下Mini-Batch SGD,当然也是大实话);然后吐槽下SGD训练的缺点:超参数调起来很麻烦。(作者隐含意思是用BN就能解决很多SGD的缺点)
接着引入covariate shift的概念:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设,网络模型很难稳定的学规律,这不得引入迁移学习才能搞定吗,我们的ML系统还得去学习怎么迎合这种分布变化啊。对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
二、BatchNorm的本质思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
上面说得还是显得抽象,下面更形象地表达下这种调整到底代表什么含义。

图1 几个正态分布
假设某个隐层神经元原先的激活输入x取值符合正态分布,正态分布均值是-2,方差是0.5,对应上图中最左端的浅蓝色曲线,通过BN后转换为均值为0,方差是1的正态分布(对应上图中的深蓝色图形),意味着什么,意味着输入x的取值正态分布整体右移2(均值的变化),图形曲线更平缓了(方差增大的变化)。这个图的意思是,BN其实就是把每个隐层神经元的激活输入分布从偏离均值为0方差为1的正态分布通过平移均值压缩或者扩大曲线尖锐程度,调整为均值为0方差为1的正态分布。
那么把激活输入x调整到这个正态分布有什么用?首先我们看下均值为0,方差为1的标准正态分布代表什么含义:

图2 均值为0方差为1的标准正态分布图
这意味着在一个标准差范围内,也就是说64%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,也就是说95%的概率x其值落在了[-2,2]的范围内。那么这又意味着什么?我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,那么看下sigmoid(x)其图形:

图3. Sigmoid(x)
及sigmoid(x)的导数为:G’=f(x)(1-f(x)),因为f(x)=sigmoid(x)在0到1之间,所以G’在0到0.25之间,其对应的图如下:

图4 Sigmoid(x)导数图
假设没有经过BN调整前x的原先正态分布均值是-6,方差是1,那么意味着95%的值落在了[-8,-4]之间,那么对应的Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢,为什么是梯度饱和区?请看下sigmoid(x)如果取值接近0或者接近于1的时候对应导数函数取值,接近于0,意味着梯度变化很小甚至消失。而假设经过BN后,均值是0,方差是1,那么意味着95%的x值落在了[-2,2]区间内,很明显这一段是sigmoid(x)函数接近于线性变换的区域,意味着x的小变化会导致非线性函数值较大的变化,也即是梯度变化较大,对应导数函数图中明显大于0的区域,就是梯度非饱和区。
从上面几个图应该看出来BN在干什么了吧?其实就是把隐层神经元激活输入x=WU+B从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的正态分布,即原始正态分布中心左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图形。什么意思?就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scalex+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。当然,这是我的理解,论文作者并未明确这样说。但是很明显这里的scale和shift操作是会有争议的,因为按照论文作者论文里写的理想状态,就会又通过scale和shift操作把变换后的x调整回未变换的状态,那不是饶了一圈又绕回去原始的“Internal Covariate Shift”问题里去了吗,感觉论文作者并未能够清楚地解释scale和shift操作的理论原因。
三、训练阶段如何做BatchNorm
上面是对BN的抽象分析和解释,具体在Mini-Batch SGD下做BN怎么做?其实论文里面这块写得很清楚也容易理解。为了保证这篇文章完整性,这里简单说明下。
假设对于一个深层神经网络来说,其中两层结构如下:

图5 DNN其中两层
要对每个隐层神经元的激活值做BN,可以想象成每个隐层又加上了一层BN操作层,它位于X=WU+B激活值获得之后,非线性函数变换之前,其图示如下:

图6. BN操作
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:

要注意,这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的线性激活x=WU+B,这里的U才是t-1层神经元的输出。变换的意思是:某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。
上文说过经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:

BN其具体操作流程,如论文中描述的一样:

过程非常清楚,就是上述公式的流程化描述,这里不解释了,直接应该能看懂。
四、BatchNorm的推理(Inference)过程
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例,那么这时候怎么对输入做BN呢?因为很明显一个实例是没法算实例集合求出的均值和方差的。这可如何是好?
既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:

有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行BN采取如下方式:

这个公式其实和训练时

是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:


都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
五、BatchNorm的好处
BatchNorm为什么NB呢,关键还是效果好。①不仅仅极大提升了训练速度,收敛过程大大加快;②还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;③另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
文章2
https://blog.csdn.net/u012816943/article/details/51691868
论文题目:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
首先看看博客http://blog.csdn.net/happynear/article/details/44238541中最开始介绍的:
为什么中心化,方差归一化等,可以加快收敛?
补充一点:输入x集中在0周围,sigmoid更可能在其未饱和区域,梯度相对更大一些,收敛更快。
Abstract
1.深层网络训练时,由于模型参数在不断修改,所以各层的输入的概率分布在不断变化,这使得我们必须使用较小的学习率及较好的权重初值,导致训练很慢,同时也导致使用saturating nonlinearities 激活函数(如sigmoid,正负两边都会饱和)时训练很困难。
这种现象加 internal covariate shift ,解决办法是:对每层的输入进行归一化。
本文方法特点是 :making normalization a part of the model
architecture and performing the normalization for each training
mini-batch
Batch Normalization 让我们可以使用更大的学习率,初值可以更随意。它起到了正则项的作用,在某些情况下,有它就不需要使用Dropout了。
在Imagenet上, achieves the same accuracy with 14 times fewertraining steps
Introduction
1. SGD:
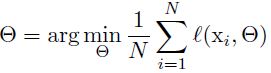
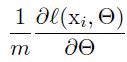
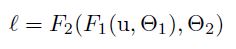
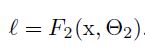
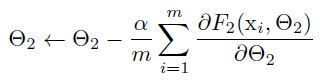
Towards Reducing Internal Covariate Shift
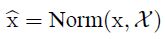
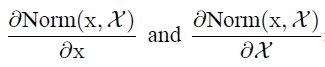
Normalization via Mini-Batch Statistics
1.有两个方面简化计算:
a.把 x 向量中每个元素当成独立随机变量单独进行规范化,向量中各变量独立了,也没有什么协方差矩阵了。这种规范化在各变量相关的情况下依然能加速收敛,(LeCun et al., 1998b),此外,如果看成向量中变量的联合概率,需要计算协方差矩阵,如果变量个数大于minibatch中样本数,协方差矩阵不可逆!!
b.在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. Algorithm 1.
simply normalizing each input of a layer may change what the layer can represent.normalizing the inputs of a sigmoid would constrain them to the linear regime of the nonlinearity
为了解决这个问题,we make sure that the transformation inserted in the network can represent the identity transform.也就是用用可以学习的 γ 和 β 去拟合出与原先等价的变换。

采用 normalize via mini-batch statistics ,the statistics used for normalization can fully participate in the gradient backpropagation
Batch Normalizing Transform:

只要minibatch中的样本采样与同一分布,规范化后的输入 x 期望为0,方差为1,把规范后的 x 进行线性变换得到 y 作为后续层的输入,可以发现 后续层的输入具有固定的均值和方差的。尽管 规范化后的 x 的联合分布在训练过程中会改变(源于第一个简化,本文的规范化是把 x 向量中各个变量当作独立的,单独规范化的,所以他们的联合分布并不稳定,只是单独是稳定的),但还是可以使训练加速。
2.优化中也需要对 BN 变换的两个参数进行优化,链式法则求导就可以了:

BN 变换是可微的,通过BN变换,可以减弱输入分布的 internal covariate shift ,并且学习到这个线性变换让 BN变换 与网络本来的变换 等价,preserves the network capacity
Training and Inference with Batch-Normalized Networks
1.使用BN,把网络中各层输入 x 变为 BN(x)即可。可以使用SGD及其各种变种训练。
2.训练时候在minibatch内规范化非常高效,但是推断时就不需要而且不应该这样了。推断是我们希望输出只取决于输入,所以规范化中的期望、方差用全部数据计算:
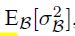
就是各minibatch的方差求平均,minibatch数量为m。
注意:推断时,均值和方差是固定的,那么规范化这步线性变换可以和 γ、β 这步线性变换 合成 一个线性变换。训练BN网络步骤如下:

Batch-Normalized Convolutional Networks
1. BN 可以用于任意层的 activations,但是把 BN 加在 W u +b 之后,非线性激活函数之前更好!
因为前层的 activations (这层的输入 u)是非线性输出的,其分布很可能在训练中变化;而 W u +b 更可能有 a symmetric, non-sparse distribution, that is “more Gaussian”
(Hyv¨arinen & Oja, 2000); 规范化它更有可能得到稳定的 activations 分布。
2. 注意 b 可以不管,因为减均值时 b 会被消掉,b 的作用其实被 β 代替了,所以:
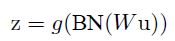
BN是对 x =W u 的每一维单独规范化
3.对卷积层,规范化也该保持卷积特性,即 相同feature map,不同 location
的元素 用相同方式规范化:
a mini-batch of size m and feature maps of size p × q, m*p*q个元素一起规范化!每个 feature map 有一对 γ β。
Batch Normalization enables higher learning rates
1.太大的学习率可能导致 梯度爆炸或消失以及卡在局部极值,BN可以防止参数小变换被逐层放大,通过修改 γ、β可以优化 activations的变化。
一般来说,大学习率增加参数的scale,在BP中放大了梯度,导致模型爆炸。然而使用了 BN,每层的BP不受其参数影响:
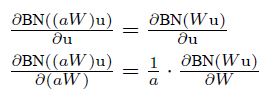
The scale does not affect the layer Jacobian nor, consequently, the gradient propagation.
而且:大权重会导致更小的梯度,所以BN可以稳定参数的增长。
2.BN还可以使 layer Jacobians 的奇异值接近 1 .这更利于训练 (Saxe et al.,2013).
论文中有在高斯、独立且变换为线性等条件下,可以推出来,但是说实话假设有点太苛刻,有点强行解释的味道,论文也提出更普适的结论需后续研究。
Batch Normalization regularizes the model
1.使用BN后,训练时对于单个样本与整个minibatch综合考虑了,training network no longer producing deterministic values for a given training example
这有利于提升网络的泛化能力,可以代替 Dropout
Experiments
Activations over time
在mnist上用3个隐层,每层100个的神经元的网络进行实验,初值为高斯,sigmoid函数,迭代50000次,minibatch为60个样本,损失为交叉熵。
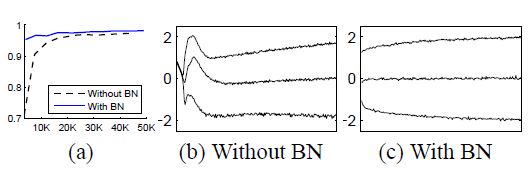
(a)可以看到,加BN测试精度更高,而且最开始就达到了较高的精度;
(b,c)可以明显看到加BN后分布更加稳定。图中三条线为{15,50,85}分位数。
后面的实验就看论文了。
【网络优化】Batch Normalization(inception V2) 论文解析(转)的更多相关文章
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- 激活函数,Batch Normalization和Dropout
神经网络中还有一些激活函数,池化函数,正则化和归一化函数等.需要详细看看,啃一啃吧.. 1. 激活函数 1.1 激活函数作用 在生物的神经传导中,神经元接受多个神经的输入电位,当电位超过一定值时,该神 ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- YOLO系列:YOLO v2深度解析 v1 vs v2
概述 第一,在保持原有速度的优势之下,精度上得以提升.VOC 2007数据集测试,67FPS下mAP达到76.8%,40FPS下mAP达到78.6%,可以与Faster R-CNN和SSD一战 第二, ...
随机推荐
- Convolution Matrix
w褶积矩阵.二值化旧图经核矩阵得到新图. https://docs.gimp.org/en/plug-in-convmatrix.html 8.2. Convolution Matrix 8.2.1. ...
- Spark源码分析 – SparkEnv
SparkEnv在两个地方会被创建, 由于SparkEnv中包含了很多重要的模块, 比如BlockManager, 所以SparkEnv很重要 Driver端, 在SparkContext初始化的时候 ...
- Incorrect string value: '\xF0\x9F\x98\x84\xF0\x9F 表情插入mysql 报错
导致报错的问题是 emoji表情是4位 mysql 5.5.3版本以下数据库(utf8格式为3位),不支持.需要更新mysql5.5.3及以上的版本数据库并设置默认或者表或者字段的格式为 utf8mb ...
- Ubutun使用记录——语系错误(转)
add by zhj: 对原文有修改,原文是在创建用户时出现的问题,而我是在使用psql时出现的, 但问题是相同的. 原文:http://www.douban.com/note/362250557/ ...
- Hadoop的Combiner
在很多MapReduce应用的场景中,假设能在向reducer分发mapper结果之前做一下"本地化Reduce".一wordcount为样例,假设作业处理中的文件单词中" ...
- (0.2.4)Mysql安装——yum源安装
转自:https://www.cnblogs.com/jimboi/p/6405560.html Centos6.8通过yum安装mysql5.7 1.下载好对应版本的yum源文件 2.安装用来配置m ...
- 008-Shell 流程控制
一.if else 1.1.if if 语句语法格式: if condition then command1 command2 ... commandN fi 写成一行(适用于终端命令提示符): ]; ...
- JDK动态代理实现源码分析
JDK动态代理实现方式 在Spring框架中经典的AOP就是通过动态代理来实现的,Spring分别采用了JDK的动态代理和Cglib动态代理,本文就来分析一下JDK是如何实现动态代理的. 在分析源码之 ...
- java 多线程 day09 线程池
import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.c ...
- mysql数据库从删库到跑路之mysq索引
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...