04_Storm编程上手_WordCount集群模式运行
1. 要解决的问题:代码打包
前一篇的代码,在IDEA中通过maven工程创建,通过IDEA完成代码打包
1)File -> Project Structure
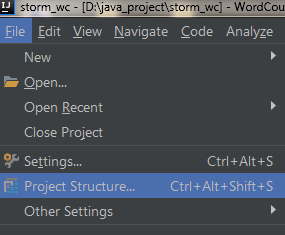
2) 选择Artifacts, 并点击加号进行新建

3)选择JAR,并根据module依赖关系进行
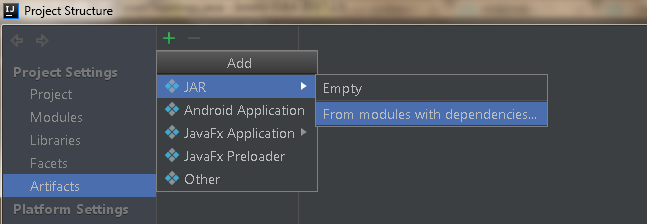
4)选择 主类,并设置Manifest文件创建在target\classes文件夹下(manifest文件主要是说明哪一个class是主类,class在哪些第三方依赖包内)
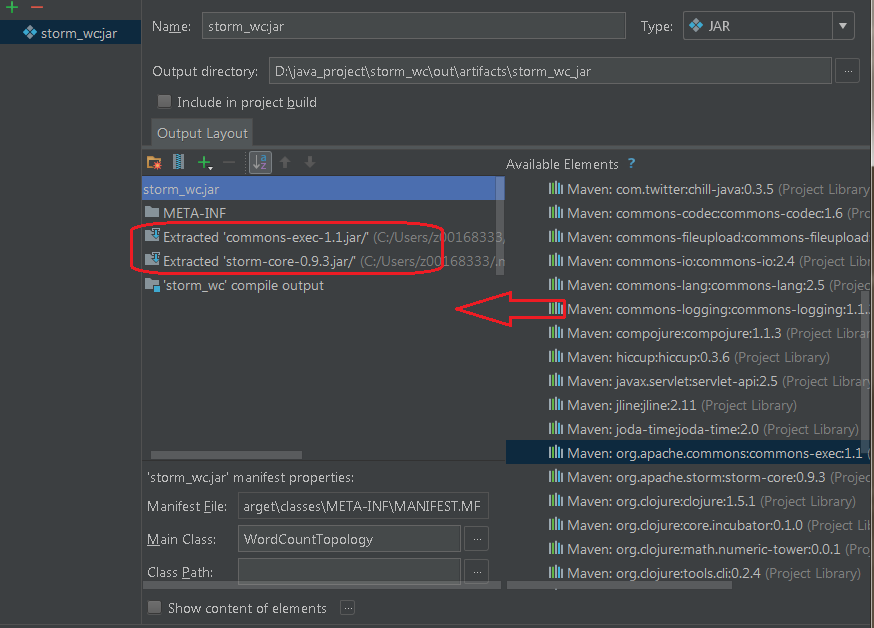
5) 根据需要,将必要的第三方依赖包加入(由于是要上传到集群,而storm相关的class文件,集群中已经具备,因此并不不要额外添加依赖包),下图演示的是需要将第三方依赖包加入的配置结果
6) 选择Build->Build Artifacts
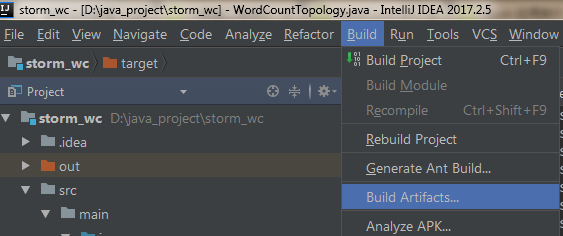
在弹出的小窗口中,确认选择Build

7)Build完成后,IDEA下方的Event log会给出完成提示
8)项目所在目录,此时会出现1个out目录

进入该目录,并一路向下,就会看到最终打包完成的JAR包

2. 打包代码上传集群
1)在主节点上创建1个目录,放置打包后的JAR文件
以我的为例,JAR文件将放置在/usr/local/src/package目录下,通过winscp或者其他FTP工具将打包好的JAR文件放入即可
2)在主节点通过storm jar命令提交拓扑任务
WordCountTopology是代码主类,其中含有main函数并在函数中定义了Topology, WordCount是输入参数,用于给Topology任务取名

3)等待终端提交任务,通过如下的信息提示可以确认Topology任务已经成功提交

4)通过storm UI查看Topology任务运行情况(http://master:8080)
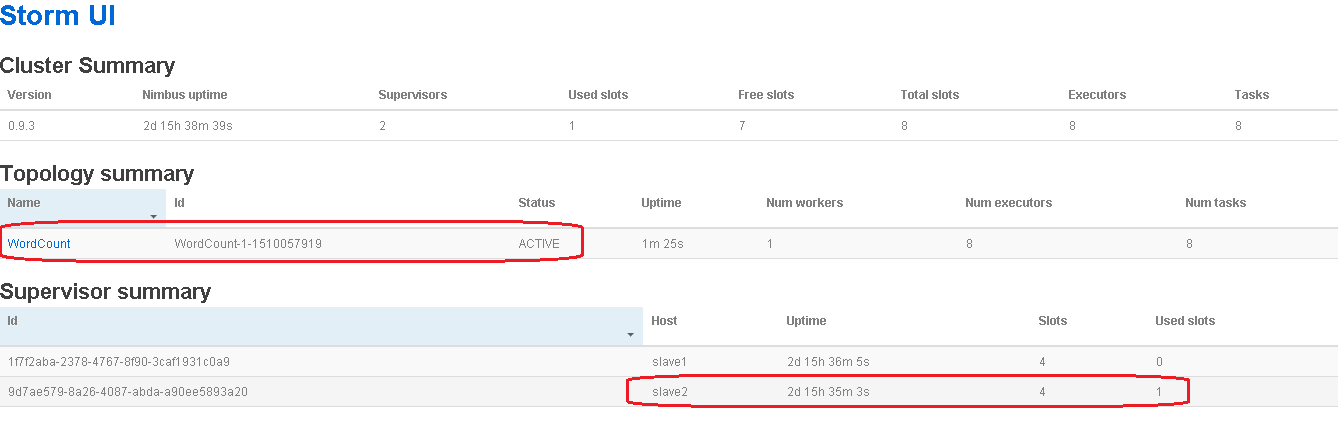
Topology可视化查看各个组件

5)从Topology任务的概况可以看到只有1个worker进程,位于slave2,通过slave2机器上storm安装目录下logs目录中的worker进程日志,可以看到实时输出
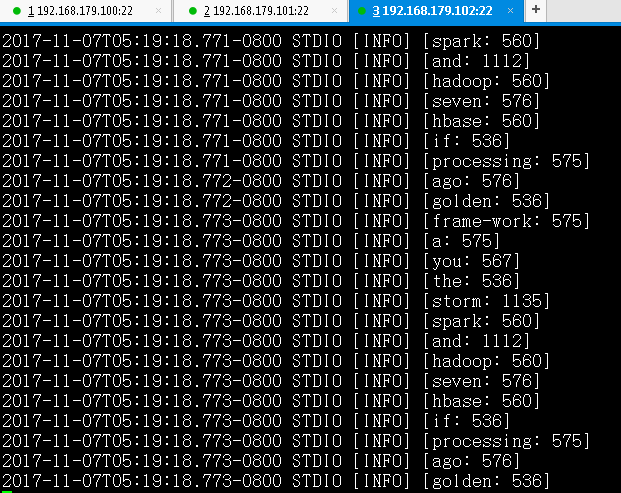
注意:putBolt类中最终输出结果,是通过System.out.println()打印结果到终端,在集群行运行时该输出会重定向到worker进程日志

通过 tail -f worker-6703.log 来实时观察Topology任务的实时输出
04_Storm编程上手_WordCount集群模式运行的更多相关文章
- 【原】简述使用spark集群模式运行程序
本文前提是已经正确安装好scala,sbt以及spark了 简述将程序挂载到集群上运行的步骤: 1.构建sbt标准的项目工程结构: 其中: ~/build.sbt文件用来配置项目的基本信息(项目名 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Centos7安装Nacos单机模式以及集群模式(包含nignx安装以及实现集群)的相关配置
Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现.服务配置.服务元数据及流量管理. Nacos支持三种部署模式 单机模式 - 用于测试 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
随机推荐
- EasyUI 的常见标签
1. Resizable 属性 原理: 页面加载完毕后,EasyUI主文件会扫描页面上的每个标签,判断这些标签的class值是否以"easyui-"开头, 如果是,则拿到之后的部分 ...
- Java 之NIO
1. NIO 简介 Java NIO(New IO)是从1.4版本开始引入的一个新的IO API,可以替代标准的Java IO API; NIO 与原来的IO有同样的作用和目的,但是使用的方式完全不同 ...
- react setstate
1.prevstate参数 https://segmentfault.com/q/1010000008177874 2.不是实时渲染 http://bbs.reactnative.cn/topic/3 ...
- shell_03
函数: fanction print_welcome(){ echo welcome now time is `date` } print_welcome 函数调用 print _welcome 00 ...
- Pycharm建立web2py项目并简单连接MySQL数据库
引言 web2py是一种免费的,开源的web开发框架,用于敏捷地开发安全的,数据库驱动的web应用:web2p采用Python语言编写,并且可以使用Python编程.web2py是一个完整的堆栈框架, ...
- python web框架 django工程的创建
安装 django pip3 install django pip install django 安装完后出现这两个文件 django-admin 用来创建文件夹 在script目录 执行这个命令 d ...
- 006-Shell printf 命令
一.概述 printf 命令模仿 C 程序库(library)里的 printf() 程序. printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好. pr ...
- django高级之爬虫基础
目录: 爬虫原理 requests模块 beautifulsoup模块 爬虫自动登陆示例 一.爬虫原理 Python非常适合用来开发网页爬虫,理由如下:1.抓取网页本身的接口相比与其他静态编程语言,如 ...
- R中遇到的部分问题
在Rstdio使用的是3.5.1的64位R版本中遇到问题:The Perl script 'WriteXLS.pl' failed to run successfully. 首先使用 Sys.whic ...
- Delphi锁定鼠标 模拟左右键 静止一会自动隐藏鼠标
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...