MapReduce-实践2
进阶实践4: mapper,reducer输出数据压缩
框架提供的压缩能力
|
能否指定压缩 |
能否指定压缩方式 |
作用 |
|
|
Mapper输出 |
Yes |
Yes |
减少shuffle网络传输的数据量 |
|
Reducer输出 |
Yes |
yes |
减少占用的HDFS容量 |
重点是修改run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/05_mr_compression_input/The_Man_of_Property.txt"
OUTPUT_PATH="/05_mr_compression_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Compress output of map and reduce $HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func WLDIR" \
-reducer "python red.py reduer_func" \
-jobconf "mapred.reduce.tasks=5" \ # 最终结果可以看到5个压缩文件
-jobconf "mapred.compress.map.output=true" \
-jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ # map输出结果进行压缩 -jobconf "mapred.output.compress=true" \
-jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ # reduce输出结果进行压缩 -cacheArchive "hdfs://master:9000/w.tar.gz#WLDIR" \ # 将HDFS上已有的压缩文件分发给Task
-file ./map.py \ # 分发本地的map程序到计算节点
-file ./red.py # 分发本地的reduce程序到计算节点
-D 方式指定
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/05_mr_compression_input/The_Man_of_Property.txt"
OUTPUT_PATH="/05_mr_compression_output" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Compress output of map and reduce $HADOOP_CMD jar $STREAM_JAR_PATH \
-D mapred.reduce.tasks= \ #指定多个reduce,看输出结果是否为5个压缩文件
-D mapred.compress.map.output=true \
-D mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec \
-D mapred.output.compress=true \
-D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec \ -input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper “python map.py mapper_func WLDIR” \
-reducer “python red.py reducer_func” \
-cacheArchive “hdfs://master:9000/w.tar.gz#WLDIR” \ -file ./map.py \
-file ./red.py
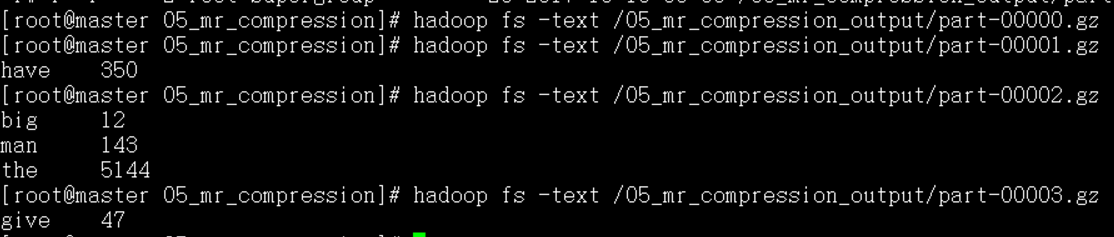
查看job运行完成后的reduce结果

对于输出的5个压缩文件,通过hadoop fs –text 可以查看gz压缩文件中的内容
MR进阶实践5: 通过输入压缩文件,控制map个数
对于压缩文件,Inputformat将不进行split, 每个压缩文件对应1个map。因此将实践4输出的压缩文件,当做Map的输入文件,就可以验证map个数是否等于输入压缩文件个数
注意:mapreducer的输入数据源可以是一个目录下的多个文件
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_PATH="/05_mr_compression_output" # 上一个task的输出目录,所有文件都作为数据源,包括5个压缩文件,log文件,SUCCESS文
# 件夹, 由于log和SUCCESS是上一个文件的历史记录信息,会被框架自动过滤,因此只会启动处理压缩文件的5个
# map OUTPUT_PATH="/output cat"
#$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# To verify map number by input compressed files $HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH\
-mapper "cat" \ # 不做任何处理,将输入数据直接输出
-jobconf "mapred.reduce.tasks=0" # 不需要任何reducer操作
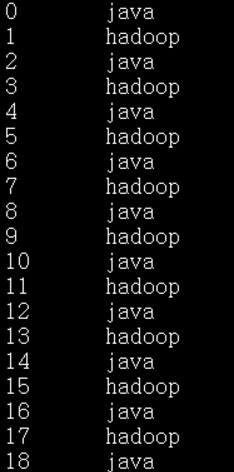
MR进阶实践6: 输入多个文件,单Reducer排序
本质:全局排序
要点:需要注意的是mapper后的排序以及reducer前的归并排序,都是对key进行字符串排序,因此会出现1, 10,110,2这样的排序结果,因此要在mapper和reducer中进行一定处理,才能得到类似数字的排序结果
|
原始数据 |
Mapper处理后数据 |
排序后Reducer前数据 |
Reducer后数据 |
|
1 |
1001 |
1001 |
1 |
|
2 |
1002 |
1002 |
2 |
|
10 |
1010 |
1003 |
3 |
|
20 |
1020 |
1010 |
10 |
|
3 |
1003 |
1020 |
20 |
Mapper: 对一行的key,value, 进行加1000操作,然后再将key转为字符串
Reducer: 对一行的key,value, 进行int(key)-1000操作,然后在将key转为字符串
# /a.txt
hadoop
hadoop
hadoop
hadoop
…………………………..
hadoop # /b.txt
java
java
java
java
…………………………..
java
run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt"
INPUT_FILE_PATH_B="/b.txt" # 2个数据源全部读取, inpuformat进行split
OUTPUT_SORT_PATH="/output_allsort_01"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH # 单Reducer实现全局排序
$HADOOP_CMD jar $STREAM_JAR_PATH \
-D mapred.reduce.tasks=1 \ # 单个recuder,利用框架自动排序的能力,完成全局排序
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B \ # 指定多个输入路径
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py
map_sort.py
#!/usr/local/bin/python
import sys
base_count = 1000 for line in sys.stdin:
key,val = line.strip().split('\t')
new_key = base_count + int(key)
print "%s\t%s" % (str(new_key), val)
reduce_sort.py
#!/usr/local/bin/python
import sys
base_value = 1000 for line in sys.stdin:
key, val = line.strip().split('\t')
print str(int(key)-1000) + "\t" + val
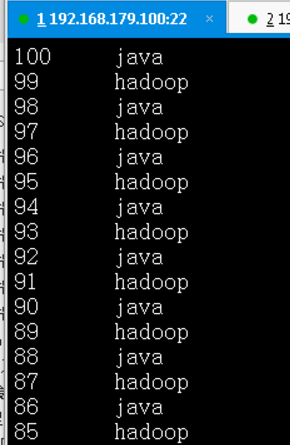
MR进阶实践7: 输入多个文件,全局逆向排序(单reducer)
本质:全局排序
分析:输入文件为多个,并且每行为key,value形式,由于MapReduce框架会自动根据key (字符串形式) 进行排序;如果只有1个Reducer,则Reducer的输入此时已经有序,直接输出即可
要点:需要注意的是mapper后的排序以及reducer前的归并排序,都是对key进行字符串排序,因此会出现1, 10,110,2这样的排序结果,因此要在mapper和reducer中进行一定处理,才能得到类似数字的排序结果
|
原始数据 |
Mapper处理后数据 |
排序后Reducer前数据 |
Reducer后数据 |
|
1 |
9998 |
9979 |
20 |
|
2 |
9997 |
9989 |
10 |
|
10 |
9989 |
9996 |
3 |
|
20 |
9979 |
9997 |
2 |
|
3 |
9996 |
9998 |
1 |
Mapper: 对一行的key,value, 进行9999-key操作,然后再将key转为字符串
Reducer: 对一行的key,value, 进行9999-int(key)操作,然后在将key转为字符串
输入数据源
# /a.txt
hadoop
hadoop
hadoop
hadoop
…………………………..
hadoop
# /b.txt
java
java
java
java
…………………………..
java
run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt"
INPUT_FILE_PATH_B="/b.txt" # 2个数据源全部读取, inpuformat进行split
OUTPUT_SORT_PATH="/output_allsort_01"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH # 单Reducer实现全局排序 $HADOOP_CMD jar $STREAM_JAR_PATH \
-D mapred.reduce.tasks= \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B \ # 指定多个输入路径 ,分隔
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py
map_sort.py
#!/usr/local/bin/python
import sys
base_count = 9999 for line in sys.stdin:
key,val = line.strip().split('\t')
new_key = base_count - int(key)
print "%s\t%s" % (str(new_key), val)
reduce_sort.py
#!/usr/local/bin/python
import sys
base_value = 9999 for line in sys.stdin:
key, val = line.strip().split('\t')
print str(9999-int(key)) + "\t" + val
MR进阶实践8: 输入多个文件,全局排序(多reducer)
本质:全局排序
分析: 单个Reducer的隐患,也算是比较明显;Reducer的负载首先会很重,如果出现问题,整个Job都要重新来过,多Reducer可以做到负载分担,但是需要保证原本1个Reducer的输入,被划分到多个Reducer后,输出结果还是有序的
|
|
|
|
|
Key: 0~50 Key: 51~100 |
Key: 0~50 |
Reducer1 |
|
Key:51~100 |
Reducer2 |
要做到这样,我们就需要手工再构建一列“key”, 专门用于做partition阶段的分桶, 由它来保证实现上面的划分
|
|
Key-new, key, value |
|
|
Key: 0~50 Key: 51~100 |
0 0~50 val |
Reducer1 |
|
1 51~100 val |
Reducer 2 |
其次在进行mapper端和reducer端排序的时候,要基于新key和原始key, 总共2列key来排序,从而实现同一reducer内部的原始key也是排序的,这样reducer端的代码只要将新增的key丢弃即可
run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt"
INPUT_FILE_PATH_B="/b.txt"
OUTPUT_SORT_PATH="/07_output_allsortNreducer"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH # add in new column for partition, use 2 column as key for sort
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py \
-jobconf mapred.reduce.tasks=2 \ # 多个reducer,进行全局排序
-jobconf stream.map.output.field.separator=' ' \
-jobconf stream.num.map.output.key.fields= \ #key有2列,新增+变换
-jobconf num.key.fields.for.partition= \ #只用key的第一列来分桶
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner #指定能基于key的某些列进行分桶的特定partitioner
map_sort.py
#!/usr/local/bin/python
import sys
base_count = 1000 for line in sys.stdin:
key,val = line.strip().split('\t')
key = base_count + int(key) partition_id = 1
if key <= (1100+1000)/2:
partition_id = 0 # 0~50,pid=0; 51~100, pid=1
print "%s\t%s\t%s" % (str(partition_id), str(key), val)
reduce_sort.py
#!/usr/local/bin/python
import sys
base_value = 1000 for line in sys.stdin:
partition_id, key, val = line.strip().split('\t')
print str(int(key)-1000) + "\t" + val #直接丢弃手工添加的partition_id
运行结果:
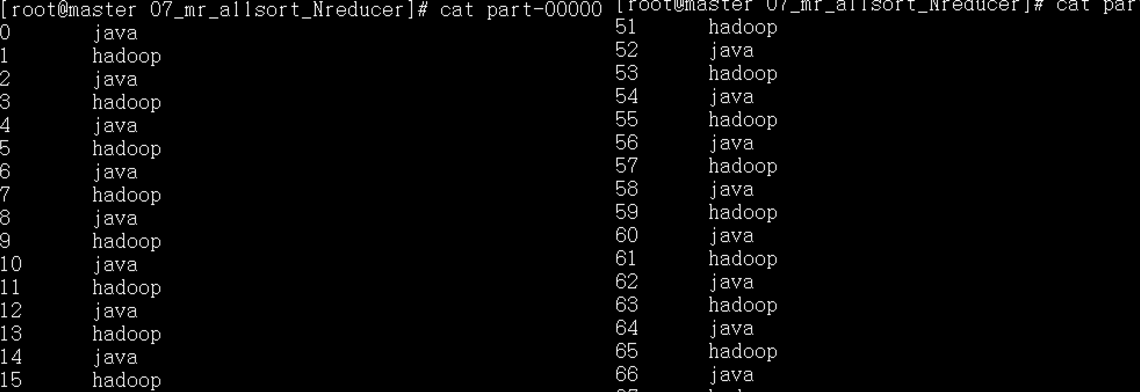
MR进阶实践8: 多表Join
run.sh 拆分为3个mapreduce任务
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt" #job1的数据源
INPUT_FILE_PATH_B="/b.txt" #job2的数据源
OUTPUT_A_PATH="/output_a"
OUTPUT_B_PATH="/output_b"
OUTPUT_JOIN_PATH="/output_join" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_A_PATH $OUTPUT_B_PATH $OUTPUT_JOIN_PATH
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_JOIN_PATH # MapReduce Job1: 表1添加flag=, (key, , value)
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A \
-output $OUTPUT_A_PATH \
-mapper "python map_a.py" \
-file ./map_a.py # MapReduce Job2: 表2添加flag=, (key, , value)
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_B \
-output $OUTPUT_B_PATH \
-mapper "python map_b.py" \
-file ./map_b.py # MapReduce Job3: cat做mapper, 每2条记录组成1个完整记录
# (key,,value) (key,, value)
# 使用第1列做分桶,使用1,2列做排序,通过reducer将两条记录合并 $HADOOP_CMD jar $STREAM_JAR_PATH \
-input $OUTPUT_A_PATH,$OUTPUT_B_PATH\
-output $OUTPUT_JOIN_PATH \
-mapper "cat" \
-reducer "python red_join.py" \
-file ./red_join.py \
-jobconf stream.num.map.output.key.fields= \ #2列做key
-jobconf num.key.fields.for.partition= \ #1列做分桶
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
第一个作业的map_a.py, 添加flag=1
#!/usr/local/bin/python
import sys for line in sys.stdin:
key,value = line.strip().split('\t')
print "%s\t\t%s" % (key, value)
第二个作业的map_b.py, 添加flag=2
#!/usr/local/bin/python
import sys
for line in sys.stdin:
key,value = line.strip().split('\t')
print "%s\t\t%s" % (key, value)
第3个mapreduce作业,将cat作为输入,因此mapper的输入是两张表记录的总和,并且同一个员工的两条记录在一起,并且来自表1的记录在前,来自表2的记录在后
|
Key1, 1, value1 |
|
Key1, 2, value2 |
|
Key2, 1, value1 |
|
Key2, 2 , value2 |
|
* partition基于第1列分桶,同一用户的记录就会由1个reducer处理 |
|
*key有2列,因此会基于2列key进行排序,保证表1的记录在前 |
第三个作业的reduce_join.py, 合并数据,丢弃添加的flag
#!/usr/local/bin/python
import sys
cur_key = None
tem_val = ‘’ for line in sys.stdin:
key,flag, value = line.strip().split('\t')
flag = int(flag) #要做转换,否则没有任何输出 if cur_key == None and flag==1:
cur_key = key
tem_val = value
elif cur_key == key and flag==2:
print ‘%s\t%s\t%s’ %(cur_key, tem_val, value)
cur_key = None
tem_val = ‘’
最后将运行结果通过hadoop fs -get下载到本地,就可以看到两张表已经完成join操作
MapReduce-实践2的更多相关文章
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- 化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- [转] Hadoop MapReduce开发最佳实践(上篇)
前言 本文是Hadoop最佳实践系列第二篇,上一篇为<Hadoop管理员的十个最佳实践>. MapRuduce开发对于大多数程序员都会觉得略显复杂,运行一个WordCount(Hadoop ...
- Mapreduce简要原理与实践
探索Mapreduce简要原理与实践 目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapred ...
随机推荐
- python基础-第四篇-4.1内置函数
lambda表达式 lambda表达式是对简单函数的精简化表达 语法结构:函数名 = lambda:运算表达式 def f1(a): a = a + 1 return a ret = f1(1) pr ...
- HTTP和HTTPS的请求和响应
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法.HTTPS(Hypertext Transfer Protocol ove ...
- Python3 格式化输出 %s & %d 等
1.打印字符串 print("My name is %s" %("Alfred.Xue")) #输出效果:My name is Alfred.Xue 2.打印整 ...
- Apache Lucene初探
讲解之前,先来分享一些资料 首先,学习任何一门新的亦或是旧的开源技术,百度其中一二是最简单的办法,先了解其中的大概,思想等等.这里就贡献一个讲解很到位的ppt 这是Lucene4.0的官网文档:htt ...
- quick-cocos2d-x + Lua 开发
quick-cocos2d-x + Lua 开发 quick-cocos2d-x + Lua 开发 首页在Eclipse中搭建quick-cocos2d-x的lua开发环境. 1. 首先需要 ...
- dev-server.js详解
转载自:https://www.cnblogs.com/ye-hcj/p/7091706.html dev-server.js详解 require('./check-versions')() var ...
- 安卓 和 IOS 的icon 尺寸
安卓 36*36 48*48 72*72 96*96 IOS Icon.png – 57×57 iPhone (ios5/6) Icon@2x.png – 114×114 iPhone Retina ...
- Java 对比Hashtable、Hashmap、Treemap有什么不同?
①基本理解 Hashtable.Hashmap.Treemap都是最常见的一些Map实现,是以键值对的形式存储和操作数据的容器类型. Hashtable是Java类库提供的一个哈希实现,本身是同步的, ...
- JAVA垃圾回收机
垃圾回收基本算法 串型回收和并行回收 串行回收始终在一个CPU上执行回收操作.并行回收则将回收任务分为好几步,每步使用不同的CPU执行,这样加快了执行速度,有点像流水线作业. 并发执行和暂停应用程序 ...
- Hexo博客部署codingNet静态资源无法加载
用Hexo搭建的个人博客,部署到github的pages的话,好像百度搜索不到.所以在国内的codingNet的pages服务也一起部署一下,这样方便国内国外搜索引擎收录进来.具体部署教程我是参考这里 ...