NNCRF之NNSegmentation, NNPostagging, NNNameEntity
这里主要介绍NNSegmentation
介绍:
NNSegmentation是一个基于LibN3L的利用神经网络来进行分词的工具。
他可以通过不同的模型(NN, RNN, GatedNN, LSTM and GRNN)) 以及不同的方法(Softmax, CRF Max-Margin, CRF Maximum Likelihood)组合来训练。
它还提供稀疏特征与模型相结合的能力。
SparseCRFMMLabeler仅仅考虑稀疏的特征 实现起来像CRF条件随机场模型
LSTMCRFMMLabeler 仅仅用neural embeddings作为输入并且利用CRF Maximum Likelihood来训练
SparseLSTMCRFMMLabeler支持sparse features和neural embeddings作为输入,并且利用CRF Maximum Likelihood来训练
首先去https://github.com/zhangmeishan
找到:NNSegmentation, NNPostagging, NNNameEntity下载
这里需要用到LibN3L mahadow OpenBLAS并且把它们与NNSegmentation, NNPostagging, NNNameEntity放在同一级的目录下
先阅读NNSegmention下的README.md
然后进入到example的文件夹里找到run.sh
我觉得老师在NNSegmention放的exaple特别好~
因为你只要读readme.txt和run.sh就都能懂了。而且连语料都放好了都在example下的pku目录里,言归正传
1.如何运行:
首先敲入cmake .
然后敲入make形成可执行文件(关于make与cmake的区别可以看这里:http://blog.sina.com.cn/s/blog_74a459380102uxlz.html)
然后进去到example目录下去 敲入:sh run.sh

2.查看输出结果、
这时候在pku.sample里生成我所选中的这三个文件,每一个文件记录着这三个模型分别在测试集和开发集上的表现。还有那三个文件夹,每个文件夹里会有pku.dev.featsOUTnodrop 和 pku.test.featsOUTnodrop,这里分别记录着在目前测试集和开发集最好的标记结果。

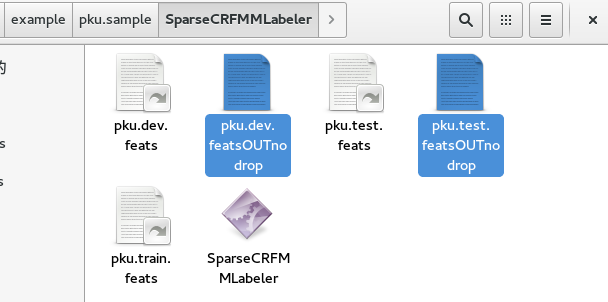
你也可以查看这里的内容。

最后可以看到类似于这样的结果:
Recall:P=43285/46549=0.92988, Accuracy:P=43285/46435=0.932163, Fmeasure:0.93102
召回率,精确率,以及F-measure也称F-score(我在zpar里提到过,大家也可以在这里看:http://baike.baidu.com/link?url=e0QzM2lTDGEXTzF3Y5KLlpo7h4U-5HLL8ukL-qPqSAiitXEyfJml_apQqSzxo6btsdIG6BZXfZuOO6b31Con_K)
3.特征模版Feature Template
举个例子:
`共同 创造 美好 的 新 世纪 —— 二○○一年 新年 贺词`, 抽取特征 "美"
`美 [T1]造美 [T2]创造美 [S]C-2=创 [S]C-1=造 [S]C0=美 [S]C1=好 [S]C2=的 [S]C-2C-1=创造 [S]C-1C0=造美 [S]C0C1=美好 [S]C1C2=好的 [S]C-1C1=造好 [S]C0C2=美的 [S]RC0C-2=0 [S]RC0C-1=0 [S]C-1C0C1=造美好 [S]TC-1=4 [S]TC-11==444 [S]TC-22==44444 b-seg`红色标记证明 :
“美“是“美“是“美好”的第一个词
- 当前特征的下标为0,前一个是-1,后一个是(+)1,(-2 ,2也是这样)
- C0代表当前的特征“美“,C1是前一个特征“造”
- Ci前面的[S]只是说明它是sparse的
- RC0C1是relationship C0 C1 相等就是1 不相等就是0 RCOC1 “美“和“造“当然不是一个特征了所以就是0
- T1代表当前特征和前一个特征连起来组成的特征
- T2代表当前特征和前两个连起来组成的特征
- [S]TC-1=4 [S]TC-11==444 [S]TC-22==44444这个又是什么意思呢?
- there are five types. 0: Punctuation, 1: Alphabet, 2:Date, 3: Number, 4: others
- 我认为是这样:
- TC-1是前一个特征的类型标记
- TC-11是前一个特征(-1),当前特征(0),后一个特征(1)的类型标记组合(所以是三个数444)
- TC-22也是这样44444 所以是5个数
- 我觉得这个例子并不是很好,因为都是others
- b-seg m-seg e-seg s-seg 分别是第一个字 中间的字 末尾的字 一个单独的字 (哈尔滨 的 天气: 哈b-seg 尔m-seg 滨e-seg 的s-seg 天b-seg 气e-seg)
可以再分析下,下面这个例子 一九九八年 新年 讲话
年 [T1]新年 [T2]年新年 [S]C-2=年 [S]C-1=新 [S]C0=年 [S]C1=讲 [S]C2=话 [S]C-2C-1=年新 [S]C-1C0=新年 [S]C0C1=年讲 [S]C1C2=讲话 [S]C-1C1=新讲 [S]C0C2=年话 [S]RC0C-2=1 [S]RC0C-1=0 [S]C-1C0C1=新年讲 [S]TC-1=4 [S]TC-11==424 [S]TC-22==24244 e-seg
红色标记证明 :年是“一九九八年”的最后一个词
以下是英文版的。。。
+ character unigram, Ci\_i ( -2=<i<=2 ).
+ character bigram, C\_{i-1}C\_i ( -2=<i<2 ), C-1C1, C0C2
+ whether two characters are equal, RC0C-2 and RC0C-1
+ character trigram, C-1C0C1
+ type(C0), there are five types. 0: Punctuation, 1: Alphabet, 2:Date, 3: Number, 4: others
+ type(C-1C0C1)
+ type(C-2C-1C0C1C2)For example, considering this sentence
`共同 创造 美好 的 新 世纪 —— 二○○一年 新年 贺词`, the extracted features for the fifth character "美" is
`美 [T1]造美 [T2]创造美 [S]C-2=创 [S]C-1=造 [S]C0=美 [S]C1=好 [S]C2=的 [S]C-2C-1=创造 [S]C-1C0=造美 [S]C0C1=美好 [S]C1C2=好的 [S]C-1C1=造好 [S]C0C2=美的 [S]RC0C-2=0 [S]RC0C-1=0 [S]C-1C0C1=造美好 [S]TC-1=4 [S]TC-11==444 [S]TC-22==44444 b-seg`
where
* 美 is the current character. You should use "-word" to specify the character unigram embeddings.
* [T1] and [T2]. Things started with "[T" are additional targets which need to be embedded. Here we use character bigram embeddings and character trigram embeddings. You should use "-tag" to specify these embeddings and use comma as a delimiter between embedding file paths.
For example, "-tag t2.vec,t3.vec".
* [S]. Things startd with [S] are sparse features.
* b-seg is the tag for current character. Tags must be augmented with '-seg' postfix to indicate this is a segmentation task but not a classification application.
后记:
感觉那些模型TNN, RNN, GatedNN, LSTM and GRNN,都也只是听说过,都不知道具体的是什么。。。。
要努力学这些基础知识啊~~~
NNCRF之NNSegmentation, NNPostagging, NNNameEntity的更多相关文章
- 我的nlp之路(1)
1/8日任务 基础篇: 如何使用远程连接从windows或者linux连到服务器进行操作(切换用户,传递文件) (严禁使用root账户) Linux基本bash命令 a) 查看文件大小, ...
- redis scan命令使用
以前的项目中有用到redis的keys命令来获取某些key,知道看了这篇文章 https://mp.weixin.qq.com/s/SGOyGGfA6GOzxwD5S91hLw.安全起见,这次打算 ...
随机推荐
- d3.js 之增加感染力:使用转场效果
转场/transition 图形比数据有感染力,动起来的图形比静态的图形更有感染力. 转场是一种过渡,提供两个稳定状态间的一种动态渐进的变化.转场的概念来源于电影. 电影中存在不同场景之间的切换,比如 ...
- 吉哥系列故事——完美队形II---hdu4513(最长回文子串manacher)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4513 题意比最长回文串就多了一个前面的人要比后面的人低这个条件,所以在p[i]++的时候判断一下s[i ...
- Python在向CSV文件写中文时乱码的处理办法
前言 python2最大的坑在于中文编码问题,遇到中文报错首先加u,再各种encode.decode.当list.tuple.dict里面有中文时,打印出来的是Unicode编码,这个是无解的.对中文 ...
- Pandas -- SettingwithCopyWarning 原理和解决方案(转)
本文对产生 SettingwithCopyWarning 的原因以及解决方案,做了详细解说. 详见: https://www.jianshu.com/p/72274ccb647a
- linux系统centOS在虚拟机下的自定义安装
一 前戏 1.1在官网找到合适的版本,镜像文件 1.2安装VMware FF590-2DX83-M81LZ-XDM7E-MKUT4 CG54H-D8D0H-H8DHY-C6X7X-N2KG6 ZC3 ...
- 007-mac快捷键
锁屏:Ctrl + Command + Q touch-bar:方法:“系统偏好设置”>“键盘”>“自定Control Strip…”,将“锁定屏幕”图标拖拽到Touch Bar上即可.] ...
- HTML5中Video和Audio
相关属性 src属性 该属性指定媒体数据的URL地址. autoplay属性 在该属性中指定是否在页面加载后自动播放,使用方法: <video src="test.mov" ...
- ORM中的related_name
ORM 的反向查找(related_name) 先定义两个模型,一个是A,一个是B,是一对多的类型. class A(models.Model): name= models.CharField('名称 ...
- PKU 1226 Substrings(字符串匹配+暴搜KMP模板)
原题大意:原题链接 给出n个字符串,找出一个最长的串s,使s或者s的反转字符串(只要其中一个符合就行)同时满足是这n个串的子串. 对于样例,第一组ABCD BCDFF BRCD最长的串就是CD; ...
- http超文本传输协议,get与post区别
一:什么是http? http:超文本传输协议(HTTP,HyperText Transfer Protocol),是一个客户端和服务器端传输的标准,是应用层通信协议.客户端是中端用户,服务器端是网站 ...