大数据(10) - HBase的安装与使用
HBaes介绍
HBase是什么?
- 数据库
- 非关系型数据库(Not-Only-SQL) NoSQL
- 强依赖于HDFS(基于HDFS)
- 按照BigTable论文思想开发而来
- 面向列来存储
- 可以用来存储:“结构化”数据,以及“非结构化”数据
- 一个另新手程序员不爽的地方:
- HBase在查询数据的时候,只能全表扫描(最少要按照某一个区间(行键范围)扫描)。
1、HBase的起源
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
-- 2006年Google发表BigTable白皮书。
-- 2006年开始开发HBase。
-- 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目。
-- 2010年HBase成为Apache顶级项目。
-- 现在很多公司二次开发出了很多发行版本,你也开始使用了。
2、HBase的角色
2.1、HMaster
功能:
1) 监控RegionServer
2) 处理RegionServer故障转移
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
2.2、RegionServer
功能:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog
5) 执行压缩
6) 负责处理Region分片
组件:
1) Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5) Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
1.3、HBase的架构
HBase一种是作为存储的分布式文件系统,另一种是作为数据处理模型的MR框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在HDFS直接存储的文件往往不具有结构化,所以催生出了HBase在HDFS上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
架构图如下图所示:
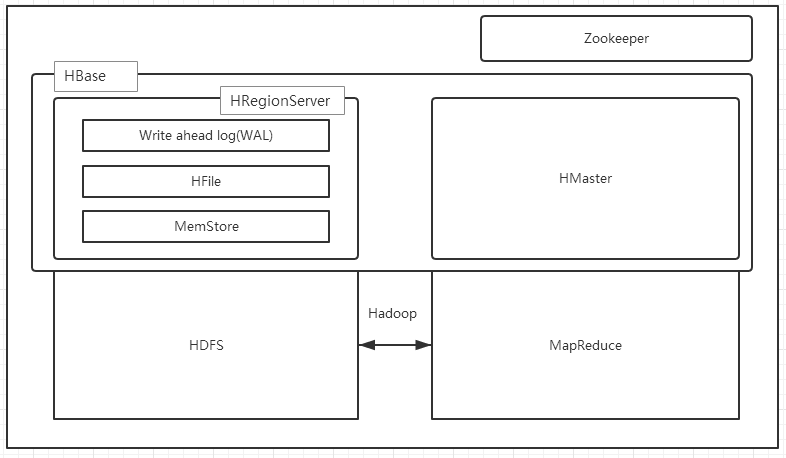
HBase内置有Zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致,请参考如下架构图:

HBase部署与使用
前期准备
- 安装部署Zookeeper
- 安装部署Hadoop
- 设置时间同步
校正时间:
sudo ntpdate pool.ntp.org 同步时间:
sudo ntpdate linux01
安装HBase
1.解压HBase
$ tar -zxf ~/softwares/installtions/hbase-1.2.6-bin.tar.gz -C ~/modules/
2.修改配置文件
修改hbase-env.sh: export JAVA_HOME=/home/admin/modules/jdk1.8.0_131 export HBASE_MANAGES_ZK=false # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
修改hbase-site.xml <configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux01:8020/hbase</value>
</property> <property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>linux01:2181,linux02:2181,linux03:2181</value>
</property> <property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/admin/modules/zookeeper-3.4.5/zkData</value>
</property>
</configuration>
修改regionservers: linux01
linux02
linux03
3.拷贝HBase所需依赖的Jar包
因为Hbase依赖Hadoop和zookeeper,所以hbase需要持有如上两个框架的jar包
删除HBase当前版本自带的Hadoop 的jar包和zookeeper的jar包 cd /home/admin/modules/hbase-1.2.6/lib
rm -rf hadoop-*
rm -rf zookeeper-3.4.6.jar 查找hadoop的jar包方法,例如将找到的jar包放到hadoop-2.7.2-hbase-jar/文件夹中
cd /home/admin/modules/hadoop-2.7.2/share/hadoop
find ./ -name *.jar 导入我们目前部署的Hadoop版本的jar包,以及zookeeper的jar包
cp hadoop-2.7.2-hbase-jar/* ~/modules/hbase-1.2.6/lib/
4.将Hadoop的core-site.xml和hdfs-site.xml这两个文件软链接到hbase的conf目录下
$ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/core-site.xml ~/modules/hbase-1.2.6/conf/core-site.xml
$ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/hdfs-site.xml ~/modules/hbase-1.2.6/conf/hdfs-site.xml
5.分发配置好的HBase安装包到其他两台机器
$ scp -r /home/admin/modules/hbase-1.2.6/ linux02:/home/admin/modules/
$ scp -r /home/admin/modules/hbase-1.2.6/ linux03:/home/admin/modules/
6.启动HBase集群
$ bin/start-hbase.sh
hbase-1.3.1,默认端口号解释
- 16000:master的默认通信地址
- 16010:master的web页面地址
- 16020:regionserver默认通信地址
- 16030:regionserver的web页面地址
hbase的简单使用
启动hbase控制台操作终端(退格:Ctrl + Backspace)
$ bin/hbase shell 创建表
hbase> create '表名','列族名'
例如: create 'student','info' 存放数据
hbase> put '表名','RowKey','列族名:列名','值'
例如:put 'student', '1001', 'info:name', 'Nick' 查看数据
hbase> scan 'student'
hbase> scan 'student',{STARTROW => '1001', STOPROW => '1003'}
(上面的操作,区间为:前闭后开)
hbase> get 'student','1001'
hbase> get 'student','1001','info'
hbase> get 'student','1001','info:name' 查看表结构
hbase> describe 'student' 删除表
先卸载表:disable 'student'
再删除:drop 'student'
HBase与Hive的集成
hive
(1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
集成方式
兼容性问题
目前使用的HBase版本:apache hbase 1.2.6
目前使用的hive版本:apache hive 1.2.2
坑:遇到报错 Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.hadoop.hbase.HTableDescriptor.addFamily(Lorg/apache/hadoop/hbase/HColumnDescriptor;)V
由于版本不兼容的问题,必须自己编译hive-hbase-handler-1.2.2.jar包(点击下载),把原来/home/admin/modules/apache-hive-1.2.2-bin/lib下的同名文件替换掉即可,如果不会编译,请下载cdh相关版本,它就是帮你处理兼容问题的。
1.环境准备
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
$ export HBASE_HOME=/home/admin/modules/hbase-1.2.6 $ export HIVE_HOME=/home/admin/modules/apache-hive-1.2.2-bin
2.添加jar包的软链接
cd /home/admin/modules/apache-hive-1.2.2-bin/lib ln -s $HBASE_HOME/lib/hbase-common-1.2.6.jar $HIVE_HOME/lib/hbase-common-1.2.6.jar
ln -s $HBASE_HOME/lib/hbase-server-1.2.6.jar $HIVE_HOME/lib/hbase-server-1.2.6.jar
ln -s $HBASE_HOME/lib/hbase-client-1.2.6.jar $HIVE_HOME/lib/hbase-client-1.2.6.jar
ln -s $HBASE_HOME/lib/hbase-protocol-1.2.6.jar $HIVE_HOME/lib/hbase-protocol-1.2.6.jar
ln -s $HBASE_HOME/lib/hbase-it-1.2.6.jar $HIVE_HOME/lib/hbase-it-1.2.6.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.2.6.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.2.6.jar
3.hive-site.xml中修改zookeeper的属性
cd /home/admin/modules/apache-hive-1.2.2-bin/lib <property>
<name>hive.zookeeper.quorum</name>
<value>linux01,linux02,linux03</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
4.导入测试
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
分步实现:
(1) 在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
(2) 在Hive中创建临时中间表,用于load文件中的数据
注意:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
(3) 向Hive中间表中load数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
(4) 通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
hive> select * from hive_hbase_emp_table; hbase> scan ‘hbase_emp_table’
大数据(10) - HBase的安装与使用的更多相关文章
- 大数据之HBase
大数据之HBase数据插入优化之多线程并行插入实测案例 一.引言: 上篇文章提起关于HBase插入性能优化设计到的五个参数,从参数配置的角度给大家提供了一个性能测试环境的实验代码.根据网友的反馈,基于 ...
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据开发--Hbase协处理器案例
大数据开发--Hbase协处理器案例 1. 需求描述 在社交网站,社交APP上会存储有大量的用户数据以及用户之间的关系数据,比如A用户的好友列表会展示出他所有的好友,现有一张Hbase表,存储就是当前 ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- 大数据(13) - Spark的安装部署与简单使用
一 .Spark概述 官网:http://spark.apache.org 1. 什么是spark Spark是一种快速.通用.可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校 ...
- 大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具) 1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. 2) Flume基于流式架构 ...
- 大数据学习——Hbase
1. Hbase基础 1.1 hbase数据库介绍 1.简介 hbase是bigtable的开源java版本.是建立在hdfs之上,提供高可靠性.高性能.列存储.可伸缩.实时读写nosql的数据库系统 ...
随机推荐
- JS及JQuery对Html内容编码,Html转义
1利用jquery /** JQuery Html Encoding.Decoding * 原理是利用JQuery自带的html()和text()函数可以转义Html字符 * 虚拟一个Div通过赋值和 ...
- Discuz常见小问题-如何发布站点公告
运营-站点公告,可以管理或添加新的公告 如果要添加要把这个终止时间设置的远一点,不然一个月之后就自动消失了 完成之后可以在首页,帖子的常规地方看到这些公告
- hdu 3065 AC自动机模版题
题意:输出每个模式串出现的次数,查询的时候呢使用一个数组进行记录就好. 同上题一样的关键点,其他没什么难度了. #include <cstdio> #include <cstring ...
- 反射方式,获取出集合ArrayList类的class文件对象
/* * 定义集合类,泛型String * 要求向集合中添加Integer类型 * * 反射方式,获取出集合ArrayList类的class文件对象 * 通过class文件对象,调用add方法 * * ...
- 安卓平台下ARM Mali OpenCL编程-GPU信息检测(转)
对于ARM Mali GPU,目前是支持OpenCL1.1,所以我们可以利用OpenCL来加速我们的计算. 一直以来,对于Mali GPU的OpenCL编程,一直没有环境来测试.好不容易弄到一个华为M ...
- 在Form中调用请求并直接打印结果
请求打印,一般都是需要提交请求,然后在请求界面查看输出,将打印内容显示在浏览器上 现可在通过调用请求后直接打印到浏览器上, 实现步骤如下: ---设置请求打印模板 l_req_bool ...
- JDBC 关于大文本数据
大文本数据Clob,在不同的数据库中类型名不一致,有的是text格式,有的是clob,还有其他一些格式 package test; import java.io.BufferedReader; i ...
- Python3 isprintable() 方法
描述 判断字符串中所有字符是否都是可打印字符(in repr())或字符串为空. Unicode字符集中“Other” “Separator”类别的字符为不可打印的字符(但不包括ASCII码中的空格( ...
- Mysql 字符串函数 详解
字符串函数是最常用的一种函数了,如果大家编写过程序的话,不妨回过头去看看自己使用过的函数,可能会惊讶地发现字符串处理的相关函数占已使用过的函数很大一部分.MySQL中字符串函数也是最丰富的一类函数,表 ...
- java中long型时间戳的计算
计算时间的时候碰到的问题: Date d = new Date(); long currtime = d.getTime(); //获取当前时间 long starttime = currtime - ...