偏最小二乘回归(PLSR)- 2 标准算法(NIPALS)
1 NIPALS 算法
Step1:对原始数据X和Y进行中心化,得到X0和Y0。从Y0中选择一列作为u1,一般选择方差最大的那一列。
注:这是为了后面计算方便,如计算协方差时,对于标准化后的数据,其样本协方差为cov(X,Y)=XTY/(n-1)。
Step2:迭代求解X与Y的变换权重(w1,c1)、因子(u1,t1),直到收敛
step 2.1:利用Y的信息U1,求X的变换权重w1(w1实现有X0到因子t1的变换,t1=X0*w1)及因子t1。从而将X0的信息用t1来近似表达。
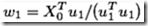 (2.1)
(2.1)
 (2.2)
(2.2)
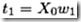 (2.3)
(2.3)
Step2.2:利用X的信息t1,求Y的变换权重c1(c1实现有Y0到因子u1的变换,u1=Y0*c1),并更新因子u1。从而将Y0的信息用t1来近似表达。
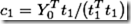 (2.4)
(2.4)
 (2.5)
(2.5)
(2.6)
Step2.5:判断是否已找到合理解
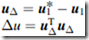 (2.7)
(2.7)
若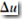 <阈值(如
<阈值(如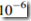 )则继续下面步骤;否则,取
)则继续下面步骤;否则,取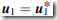 ,返回step2.1。
,返回step2.1。
注:
1)以上过程的意义及其收敛性的直观分析
a)公式2.1,实际上求解了由Y的因子u1到X的回归模型的系数
,公式2.2与2.3将X映射为第一个因子t1。
b)同理,公式2.4,实际上求解了由X的因子t1到Y的回归模型的系数,公式2.5与2.6将X映射为第一个因子t1。
c)这里交替建立X与Y直接回归关系的方式,通常会很快收敛。
2)w1与c1的其他求法。[2,3]中已经证明以上求解过程收敛后找到的解w1与c1可以利用矩阵分析方法找到
a)特征值分解方法(Eigen Value Decomposition):w1是
的最大特征值的单位特征向量,c1是
的最大特征值的单位特征向量,
b)SVD分解法(singular vector decomposition):w1和c1分别于对X0TY0进行SVD分解获得的第一对左奇异向量(left singular vector)和右奇异向量的单位
向量。
Step3:求X与Y的残差矩阵
step 3.1:求X的载荷(X-loading)p1(p1反映X0与因子t1的直接关系,
)
注:前面求得X的变换权重w1是由X0到t1的关系,此处的p1是由t1到X0的关系。而且,由于后续的Wi(i>1)是根据Xi的残差求得的,因此它无法反映T到X0的关系。所以,才要求出P以直接反映T到X0的关系)
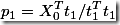 (2.8)
(2.8)
p1求解公式的推导如下
a)前面已求出t1,现在希望用t1来表达X0,建立回归模型
b)模型不能表达的信息即为X0的残差矩阵X1。
c)上式的关键是求p1,其求解公式推导过程:对
转置得
,两边右乘t1有
,从而有
注:p1代表因子t1在X上的载荷(loadings),它反映了原始变量X与第一个因子向量t1间的关系。
step 3.2:求X0的残差X1。此残差表达了u1所不能反映的X0中的信息。
(2,9)
step 3.3:求Y的载荷(Y-loading)q1(q1反映Y0与因子U1的关系,
)
(2.10)
step 3.4:建立X因子t1与Y因子u1间的回归模型
,用t1预测u1的信息。
(2.11)
step 3.5:求Y0的残差Y1。此残差表达了X因子t1所不能预测的Y0中的信息
(2.12)
注:这里利用
,建立t1与Y间的关系。
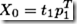
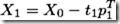
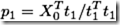
Step4:利用X1与Y1,重复上面步骤,求解下一批PLS参数(因子、转换权重、载荷、回归系数等)。
在这个算法中,当一个因子计算出来后,进一步计算出X(及Y)的残差。下一个因子是从当前残差矩阵计算出来,因此PLS模型参数(因子scores,loadings, weights)与最初的X0无关,而是与残差有关。
2 NIPALS-PLS 参数的理解
1)变换权向量w

在第二轮及以后的计算过程中,权向量wa将残差Xa-1变换为因子得分ta,而不是对原始预处理后的数据X0直接进行变换,这阻碍了对于因子的有效解释。实际上,权向量在PLS回归模型中的解释中用处不大。
2)构建X0到T直接联系的权向量R
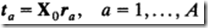 ,
,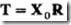
PLS算法执行完成后,我们得到所有的因子t,那么我们就可以直接建立原始数据X0与其之间的转换权重矩阵R。其实R就是由X0到T的回归系数,其计算公式为
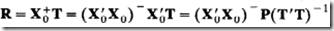
3 NIPALS-PLS 的预测过程
当完成PLS模型构建后,我们得到的PLS模型参数包括:
1)转换权重:W(X-weights),C(Y-wights)
2)因子得分:T(X-factor scores),U(Y-factor scores)
3)载荷:P(X-loadings),Q(Y-loadings)
当来了一条新数据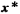 ,其预测计算过程如下
,其预测计算过程如下
1)预处理:
。注:预处理方法与建模时保持一致,这里公式采用中心化处理方法。
2)依次求出求
的各因子和残差
3)计算预测值
上面是由T到Y预测值的回归方程,而不是由X0到Y预测值的回归方程。如果在PLS建模过程中获得第2节中介绍的可将X0直接转换为T的权重R,那么就能获得一个针对X0的更直接的回归公式。
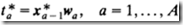
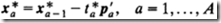
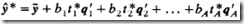
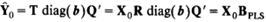 ,回归系数
,回归系数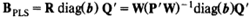
参考文献
[1] S. de Jong. SIMPLS: an alternative approach to partial least squares regression. Chemometrics and Intelligent Laboratory Systems, 18:251–263, 1993.
[2] R. Manne. Analysis of Two Partial-Least-Squares Algorithms for Multivariate Calibration. Chemometrics and Intelligent Laboratory Systems, 2:187–197, 1987.
[3] A. H¨oskuldsson. PLS Regression Methods. Journal of Chemometrics, 2:211–228,1988.
[4]
偏最小二乘回归(PLSR)- 2 标准算法(NIPALS)的更多相关文章
- 【建模应用】PLS偏最小二乘回归原理与应用
@author:Andrew.Du 声明:本文为原创,转载请注明出处:http://www.cnblogs.com/duye/p/9031511.html,谢谢. 一.前言 1.目的: 我写这篇文章的 ...
- 偏最小二乘回归(PLSR)- 1 概览
1. 概览 偏最小二乘算法,因其仅仅利用数据X和Y中部分信息(partial information)来建模,所以得此名字.其总体处理框架体现在下面两图中. 建议先看第2部分,对pls算法有初步了解后 ...
- 【数学建模】偏最小二乘回归分析(PLSR)
PLSR的基本原理与推导,我在这篇博客中有讲过. 0.偏最小二乘回归集成了多元线性回归.主成分分析和典型相关分析的优点,在建模中是一个更好的选择,并且MATLAB提供了完整的实现,应用时主要的问题是: ...
- [置顶] 局部加权回归、最小二乘的概率解释、逻辑斯蒂回归、感知器算法——斯坦福ML公开课笔记3
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9113681 最近在看Ng的机器学习公开课,Ng的讲法循循善诱,感觉提高了不少 ...
- [matlab] 21.灰色预测、线性回归分析模型与最小二乘回归 (转载)
灰色预测的主要特点是只需要4个数据,就能解决历史数据少,序列的完整性以及可靠性低的问题,能将无规律的原始数据进行生成得到规律性较强的生成序列,易于检验 但缺点是只适合中短期的预测,且只适合指数级增长的 ...
- logistic回归梯度上升优化算法
# Author Qian Chenglong from numpy import * from numpy.ma import arange def loadDataSet(): dataMat = ...
- 用C结构体来实现面向对象编程,ti xDAIS标准算法就这么搞的(1)
用C结构体来实现面向对象编程,ti xDAIS标准算法就这么搞的. 测试代码如下: #include <stdio.h> #include <stdlib.h> #includ ...
- 第 1 章 第 1 题 高级语言的排序问题 C++标准算法实现
问题分析 依题意,所需程序不用过多考虑效率且暗示使用库,自然想到用高级语言实现(个人选择C++).可用顺序容器暂存数据,用标准算法解决排序问题. 代码实现 #include <iostream& ...
- 【计算机视觉】黄金标准算法Gold Standard algorithm
前言 最近有关于3DMM的内容,博主也只是看了个大概,并没有深入了解算法的实现原理和过程.昨天实习生问关于黄金标准算法的推导,博主也就参考一些资料熟悉了这个算法的实现过程.不太了解使用这个算法的前因后 ...
随机推荐
- jsp和servlet有哪些相同点和不同点,它们之间的联系是什么?
1.jsp经编译后就变成了servlet(jsp本质就是servlet,jvm只能识别java的类,不能识别jsp代码,web容器将jsp的代码编译成jvm能够识别的java类) 2.jsp更擅长表现 ...
- DP练习 最长上升子序列nlogn解法
openjudge 百练 2757:最长上升子序列 总时间限制: 2000ms 内存限制: 65536kB 描述 一个数的序列bi,当b1 < b2 < ... < bS的时候, ...
- ACM -- 算法小结(十)素数的两种打表法
素数的两种打表法 下面介绍两种素数打表法,由于是两年前留下的笔记,所以没有原创链接~~ @_@!! 第一种疯狂打表法: #include<stdio.h> #include<math ...
- VK Cup 2015 - Round 1 E. Rooks and Rectangles 线段树 定点修改,区间最小值
E. Rooks and Rectangles Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/problemse ...
- python 读写txt文件并用jieba库进行中文分词
python用来批量处理一些数据的第一步吧. 对于我这样的的萌新.这是第一步. #encoding=utf-8 file='test.txt' fn=open(file,"r") ...
- 【原】配置Log4j,使得MyBatis打印出SQL语句
[环境参数] JDK:jdk1.8.0_25 IDE:Eclipse Luna Servie Release 1 框架:Spring 4.1.5 + SpringMVC 4.1.5 + MyBatis ...
- MP2359 1.2A, 24V, 1.4MHz Step-Down Converter in a TSOT23-6
The MP2359 is a monolithic step-down switch mode converter with a built-in power MOSFET.It achieves ...
- VS2010下面Empty Project使用
VS2010下面Empty Project使用:1,添加代码HelloApp #include <afxwin.h> class CHelloApp:public CWinApp{publ ...
- 幸福框架:用户想看到的操作日志也要使用AOP吗?
背景 日志无论是对于开发人员.运维人员和最终用户都是一笔财富,是不是所有类型的日志都要AOP呢?本着交流的目的,这里先说一些看法,希望大家多批评. 常见的日志类型 异常日志 概念:记录异常的日志. 考 ...
- python笔记17-字典如何按value排序
前言 面试题:如何统计数组中出现次数最多的数据,按出现次数由大到小排序 这个排序看似简单,涉及到的基础知识点还是很多的,真正写起来并不容易 备注:本篇是以python3.6讲解的,python2会多一 ...