分类,logistic回归
1. 使用回归进行分类
机器学习中分类是指输入一个样本点,输出这个样本点所属的类别,预测的是一个离散值,如类别(1,2)。
而回归问题是输入一个样本点,预测一个值,这个值是连续值,可以介于\([1,2]\)之间。
以二分类问题为例,我们可不可以通过回归的方法来进行分类呢?比如输入一个样本点,如果是第1类,就让他输出1,如果是第2类就输出-1。通过线性回归的损失函数\(\frac{1}{m}\sum_{i=1}^n(y_i-\hat y)^2\),进行梯度下降,来求参数\(w,b\)最终获得一个超平面进行分类。
这种方法是不行的。因为如下图。
问题:
- 对于左边的图,我们求得是理想的分界线,但是对于右边的图,右下角部分的点属于1类,如果使用绿线的参数来预测右下角点,值会远远大于1,表示分类很正确。但是我们设定损失函数的时候,希望属于第1类的点预测值等于1,因此会使调整参数使右下角的点预测值变小接近1,结果就会使绿线变为紫线,分类不准确
- 对于多分类问题,如类1输出1,类2输出2,类3输出3。回归问题就会假想这三个类别有某种关系,比如类3跟类2比较接近,类2跟类3比较接近,因为输出值离得的比较近。但是实际上没有关系。得不到好结果。

2. 通过概率理解分类问题
我们想,通过求某个样本属于某个类别的概率,在比较属于哪个类别的概率比较大,来判断此样本属于哪个类别。这个想法也叫产生式模型。与之对应的还有判别式模型。两者有什么区别呢。
生成模型:假如有\(C_1,C_2,C_3\)三个类别,求样本\(x\)属于哪个类别。对于产生式模型是,先通过训练集分别求出每个类\(C_1,C_2,C_3\)的联合概率分布。在通过每个联合概率分布求得样本\(x\)属于哪个类别的概率,通过比较属于哪个类别概率大来判断类别。
如朴素贝叶斯模型
判定模型:通过一系列的训练集样本,直接生成一个决策边界,给定一个样本,可以直接带入函数中求得属于哪一类。即处在决策边界的哪一方。
如逻辑回归,支持向量机
下图展示了判定模型跟生成模型:可以看出判定模型是求出了决策边界,生成模型是求得联合概率分布
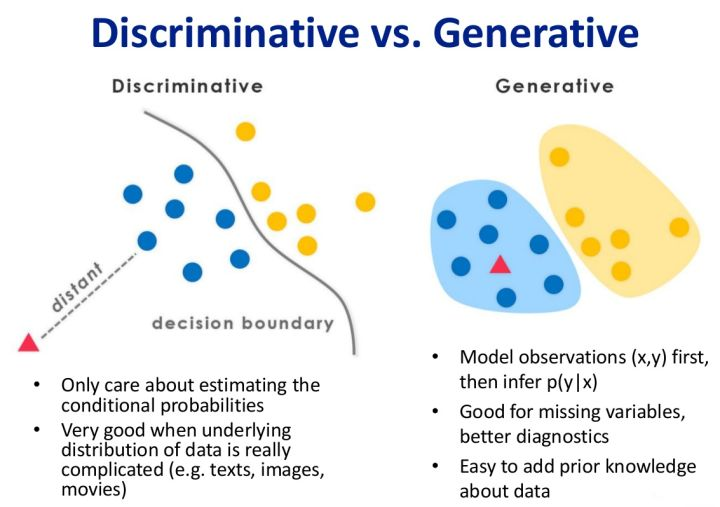
优缺点:
- 生成模型需要的样本数量少,因为只需进行统计技术来获得模型。
- 生成模型准确率一般不高,因为需要人为指定属于哪一种分布。
- 生成模型对噪声有更好的鲁棒性
- 判定模型准确率高,可直接学习求得参数,简化学习。
假设分布符合高斯分布,则给定训练集,对每一类的数据集我们可以求得一个分布函数,其中\(\mu\)为此类所有样本的平均值,\(\Sigma\)为此类样本维度对应的协方差矩阵。
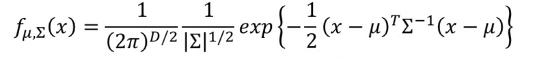
有了分布函数,给定一个样本\(x\)我们就可以求得此样本在此类分布中出现的可能行。对于某类的高斯分布函数,属于这一类的样本点的概率和是最大的。即
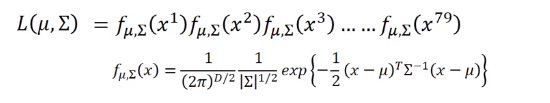
但平时我们不会为每个类别建立一个高斯分布函数,而是共用一个协方差,即求这样一个高斯分布函数,使函数值最大,其中\(\mu_1,u_2\)是训练集中每个类的样本的平均值,\(\Sigma\) 等于每个类对应的比例的协方差之和,即假如有79个1类样本,61个类样本,一共140个样本,\(\Sigma=\frac{79}{140}\Sigma_1+\frac{61}{140}\Sigma_2\)
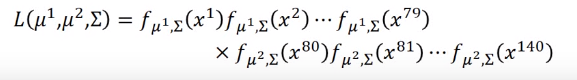
若所有样本的每一个维度都相互独立,\(x_1,x_2 \cdots x_k\)为\(x\)的每一个维度,那我们可以令:
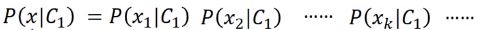
但实际中,每个属性不是相互独立的,这个模型类效果不会很好。
下面看sigmoid函数跟后验概率的联系。

可以看到若将\(ln\frac{P(x|C_1)P(C_1)}{P(x|C_2)P(C_2)}\)带入sigmoid中得到的就是样本\(x\)属于类1的概率,在将z进行化简,\(C_1,C_2\)共用协方差得到
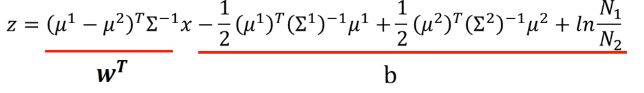
即我们可以简化为求解向量\(w^T\)跟常数\(b\)来求解样本\(x\)所属的类1的概率。
3. 逻辑回归
有了sigmoid函数后我们看如何来建立逻辑回归模型解决分类问题。
我们的假设函数为\(f_{w,b}(x)=\sigma(\sum_i w_i x_i+b)\)带入样本\(x\)输出值\((0,1)\)的预测值,\(\sigma\)为sigmoid函数。那我们的损失函数为应该设为什么样子。首先想到的是求平方差的方法,即设
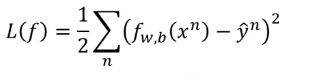
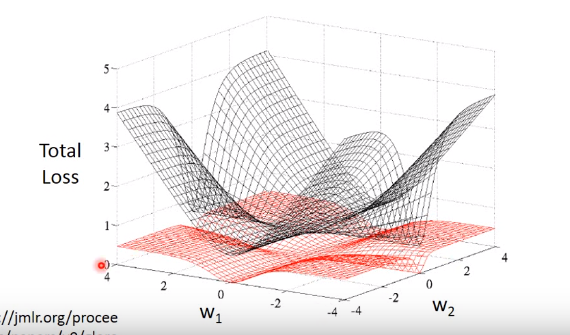
在通过梯度下降的方式求得参数\(w,b\) ,直觉上行的通,但是通过下图我们可以看出,通过求平方差设定的损失函数的图是红色网格。在整个样本空间中每个点的梯度值都很小,参数很难更新,因此我们得寻找其他方法。
设函数为下面公式,其中\(x^1,x^2 \cdots x^N为样本点\),\(x^1,x^2,x^N\)为类1,\(x^3\)为类2

我们要求得的参数$w^,b^ $就是使函数最大的值。对函数L做如下转化
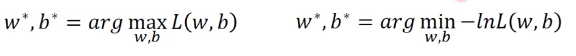
设第一类的标签为1,第二类的标签为0,可以得到如下式子,这其实使伯努利的交叉熵形式。
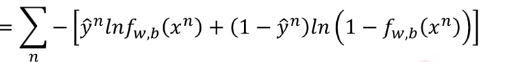
下面简要介绍交叉熵
先说信息量,信息量的公式为\(-log_2p\),\(p\)为某个时间事件发生的概率。通过公式我们可以看到,信息量与概率呈反比。这其实有很直观的解释,如果我们对某件事很确定,那这件事带给我们的信息量就很少,如果对某件事一点把握都没有,那他的信息量就很大。
信息熵:信息熵是信息量的期望公式如下,因此信息熵是平均而言发生一个事件我们得到的信息量的大小。熵越大不确定就越大,熵越小不确定性就越小。

对于每个系统,它都有个真实分布记,通过这个真实分布我们可以通过信息熵的公式求出这个系统的不确定性大小。
交叉熵:其用来衡量\(p\)的分布与\(q\)的分布有多接近
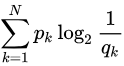
\(p_k\)为真实分布的概率,即训练集中标签,\(q_k\)为我们模拟的分布函数求得的概率,交叉熵的值越小,\(q_k\)的值越接近$q _k $,即我们模拟的函数越接近真实分布,预测越准确。因此我们在机器学习分类算法中,我们会最小化交叉熵,交叉熵越小,我们的预测就越准确。回到我们定义的损失函数,我们最小化我们的损失函数,就可以使我们的预测值,接近标签值。
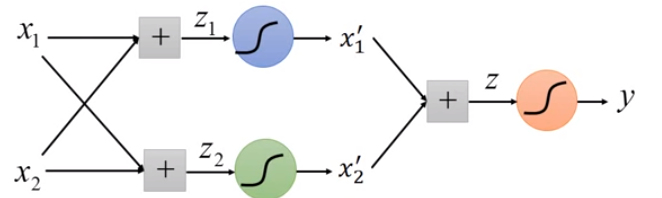
逻辑回归的一个局限性是只能产生线性分界线,可以通过进行特征转化,来将之前非线性可分的数据转换为线性可分。还可以通过组合多个逻辑回归来产生非线性分界线。其实就是神经网络。
4. 参考
- 李宏毅机器学习
- 信息熵是什么? - 滴水的回答 - 知乎
https://www.zhihu.com/question/22178202/answer/49929786 - 如何通俗的解释交叉熵与相对熵? - Noriko Oshima的回答 - 知乎
https://www.zhihu.com/question/41252833/answer/108777563
分类,logistic回归的更多相关文章
- SPSS数据分析—多分类Logistic回归模型
前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型. 多分类Logistic回归模型又分为有序多分类Logi ...
- Logistic回归分析之多分类Logistic回归
Logistic回归分析(logit回归)一般可分为3类,分别是二元Logistic回归分析.多分类Logistic回归分析和有序Logistic回归分析.logistic回归分析类型如下所示. Lo ...
- SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能 ...
- 二分类Logistic回归模型
Logistic回归属于概率型的非线性回归,分为二分类和多分类的回归模型.这里只讲二分类. 对于二分类的Logistic回归,因变量y只有“是.否”两个取值,记为1和0.这种值为0/1的二值品质型变量 ...
- 【ML系列】简单的二元分类——Logistic回归
对于了解机器学习中二元分类问题的来源与分析,我认为王树义老师这篇文章讲的非常好,通俗且易懂: http://blog.sciencenet.cn/blog-377709-1121098.html 但王 ...
- SAS学习笔记36 二分类logistic回归
这里所拟合模型的AIC和SC统计量的值均小于只有截距的模型的相应统计量的值,说明含有自变量的模型较仅含有常数项的要好 但模型的最大重新换算 R 方为0.0993,说明模型拟合效果并不好,可能有其他危险 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- SPSS数据分析—配对Logistic回归模型
Lofistic回归模型也可以用于配对资料,但是其分析方法和操作方法均与之前介绍的不同,具体表现 在以下几个方面1.每个配对组共有同一个回归参数,也就是说协变量在不同配对组中的作用相同2.常数项随着配 ...
- 机器学习公开课笔记(3):Logistic回归
Logistic 回归 通常是二元分类器(也可以用于多元分类),例如以下的分类问题 Email: spam / not spam Tumor: Malignant / benign 假设 (Hypot ...
- 5 Logistic回归(一)
首次接触最优化算法.介绍几个最优化算法,并利用它们训练出一个非线性函数用于分类. 假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该直线为最佳拟合直线),这个拟合过程称作回归. 利用Logis ...
随机推荐
- Groovy学习()起步
安装Groovy 在Windows环境下安装Groovy 下载安装包,傻瓜安装,设置环境目录,就这样搞定. 另外还需要安装Java并且设置JAVA_HOME环境变量. 两分钟搞定. 使用groovys ...
- 记录一个glibc 导致的段错误以及gdb 移植
上一篇我有相关关于一个段错误的记录,现在记录当时的段错误具体是在哪里的. // 从 GNU 的官网下载当前在使用的 glibc 的源代码以及最新的 glibc 源代码 // 地址如下: http:// ...
- sama5d3 环境检测 gpio--yx测试
说明: yx0--pioA0 yx1--pioA2 yx2--pioA4 yx3--pioA10 yx4--pioA14 yx5--pioA16 yx6--pioA12 yx7--pioA20 ...
- zabbix 监控 AWS-SQS 队列
zabbix-AWS_SQS-monitor AWS SQS status monitor with zabbix zabbix通过 AWS 云 api 自动发现.监控 AWS-SQS 本版本数据的图 ...
- TensorFlow基础笔记(8) TensorFlow简单人脸识别
数据材料 这是一个小型的人脸数据库,一共有40个人,每个人有10张照片作为样本数据.这些图片都是黑白照片,意味着这些图片都只有灰度0-255,没有rgb三通道.于是我们需要对这张大图片切分成一个个的小 ...
- 错题0925-java
1.Given the following code: public class Test { private static int j = 0; private static Boolean met ...
- 002Jsp的内置对象
1 课程回顾 Jsp基础 1)Jsp的执行过程 tomcat服务器完成:jsp文件->翻译成java文件->编译成class字节码文件-> 构造类对象-> 调用方法 tomca ...
- PHP常用技术文之文件操作和目录操作总结
<?php header("content-type:text/html;charset=utf-8"); /* *声明一个函数,传入文件名获取文件属性 *@param st ...
- Maven仓库的搭建
http://blog.csdn.net/xiao__gui/article/details/52625660 Maven仓库是有特定规则的目录结构. 目录结构由 仓库根目录 , groupId , ...
- [转]这五种方法前四种方法只支持IE浏览器,最后一个方法支持当前主流的浏览器(火狐,IE,Chrome,Opera,Safari)
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...