Python并行编程(十):多线程性能评估
1、基本概念
GIL是CPython解释器引入的锁,GIL在解释器层面阻止了真正的并行运行。解释器在执行任何线程之前,必须等待当前正在运行的线程释放GIL,事实上,解释器会强迫想要运行的线程必须拿到GIL才能访问解释器的任何资源,例如栈或Python对象等,这也正是GIL的目的,为了阻止不同的线程并发访问Python对象。这样GIL可以保护解释器的内存,让垃圾回收工作正常。但事实上,这却造成了程序员无法通过并行执行多线程来提高程序的性能。如果我们去掉GIL,就可以实现真正的并行。GIL并没有影响多处理器并行的线程,只是限制了一个解释器只能有一个线程在运行。
2、测试用例
测试一:空函数
- from threading import Thread
- def function_to_run():
- pass
- class threads_object(Thread):
- def run(self):
- function_to_run()
- class nothreads_object(object):
- def run(self):
- function_to_run()
- def non_threaded(num_iter):
- funcs = []
- for i in range(int(num_iter)):
- funcs.append(nothreads_object())
- for i in funcs:
- i.run()
- def threaded(num_threads):
- funcs = []
- for i in range(int(num_threads)):
- funcs.append(threads_object())
- for i in funcs:
- i.start()
- for i in funcs:
- i.join()
- def show_results(func_name, results):
- print("%-23s %4.6f seconds" % (func_name, results))
- if __name__ == "__main__":
- import sys
- from timeit import Timer
- repeat = 100
- number = 1
- num_threads = [1, 2, 4, 8]
- print('starting tests')
- for i in num_threads:
- t = Timer("non_threaded(%s)" % i, "from __main__ import non_threaded")
- best_result = min(t.repeat(repeat=repeat, number=number))
- show_results("non_threaded (%s iters)" % i, best_result)
- t = Timer("threaded(%s)" % i, "from __main__ import threaded")
- best_result = min(t.repeat(repeat=repeat, number=number))
- show_results("threaded (%s threads)" % i, best_result)
- print('Iterations complete')
下面的代码是用来评估多线程应用性能的简单代码。每一次测试都循环调用函数100次,重复执行多次,取速度最快的一次。在for循环中,调用non_threaded和threaded函数。同时,我们会不断增加调用次数和线程数来重复执行这个测试。在非线程测试中,调用函数与定义线程数一样多的次数。只需改变function_to_run的内容即可进行测试。
上面代码测试的为空函数,执行结果如下:
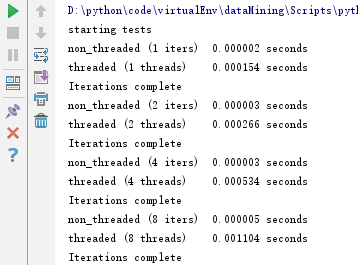
通过结果发现,使用线程的开销比不使用线程的开销大得多。
测试二:数字处理
将function_to_run改成计算斐波那契数列
- def function_to_run():
- # pass
- a, b = 0, 1
- for i in range(10000):
- a, b = b, a + b
结果如下:
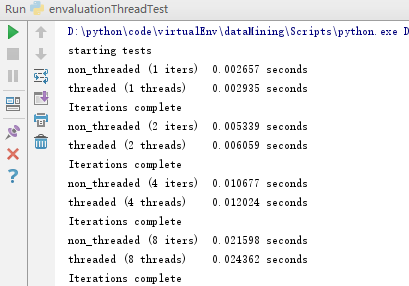
结果:提高线程的数量并没有带来收益,因为GIL和线程管理代码的开销,多线程运行永远不可能比函数顺序执行更快。GIL只允许解释器一次执行一个线程。
测试三:数据读取
更改function_to_run如下:
- def function_to_run():
- # pass
- # a, b = 0, 1
- # for i in range(10000):
- # a, b = b, a + b
- fh = open("README.md","rb")
- size = 1024
- for i in range(1000):
- fh.read(size)
运行结果:
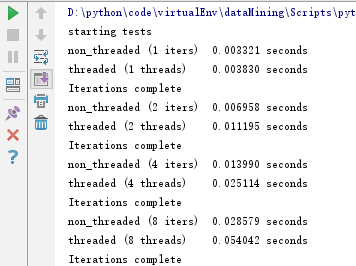
测试四:URL请求
- from threading import Thread
- def function_to_run():
- # pass
- # a, b = 0, 1
- # for i in range(10000):
- # a, b = b, a + b
- # fh = open("README.md","rb")
- # size = 1024
- # for i in range(1000):
- # fh.read(size)
- import urllib.request
- for i in range(10):
- with urllib.request.urlopen("https://www.baidu.com/") as f:
- f.read(1024)
- class threads_object(Thread):
- def run(self):
- function_to_run()
- class nothreads_object(object):
- def run(self):
- function_to_run()
- def non_threaded(num_iter):
- funcs = []
- for i in range(int(num_iter)):
- funcs.append(nothreads_object())
- for i in funcs:
- i.run()
- def threaded(num_threads):
- funcs = []
- for i in range(int(num_threads)):
- funcs.append(threads_object())
- for i in funcs:
- i.start()
- for i in funcs:
- i.join()
- def show_results(func_name, results):
- print("%-23s %4.6f seconds" % (func_name, results))
- if __name__ == "__main__":
- import sys
- from timeit import Timer
- repeat = 100
- number = 1
- num_threads = [1, 2, 4, 8]
- print('starting tests')
- for i in num_threads:
- t = Timer("non_threaded(%s)" % i, "from __main__ import non_threaded")
- best_result = min(t.repeat(repeat=repeat, number=number))
- show_results("non_threaded (%s iters)" % i, best_result)
- t = Timer("threaded(%s)" % i, "from __main__ import threaded")
- best_result = min(t.repeat(repeat=repeat, number=number))
- show_results("threaded (%s threads)" % i, best_result)
- print('Iterations complete')
运行结果:
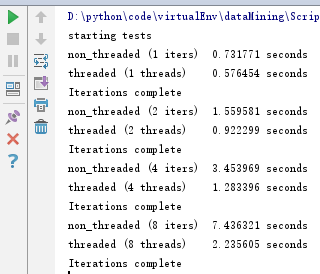
在有I/O操作时,多线程比单线程快得多。增加线程并不会提高应用启动的时间,但是可以支持并发。例如,一次性创建一个线程池,并重用worker会很有用,这可以让我们切分一个大的数据集,用同样的函数处理不同的部分。
Python并行编程(十):多线程性能评估的更多相关文章
- Python并行编程(十四):异步编程
1.基本概念 除了顺序执行和并行执行的模型以外,还有异步模型,这是事件驱动模型的基础.异步活动的执行模型可以只有一个单一的主控制流,能在单核心系统和多核心系统中运行. 在并发执行的异步模型中,许多任务 ...
- Python并行编程(十二):进程同步
1.基本概念 多个进程可以协同工作来完成一项任务,通常需要共享数据.所以在多进程之间保持数据的一致性就很重要,需要共享数据协同的进程必须以适当的策略来读写数据.同步原语和线程的库类似. - Lock: ...
- Python并发编程04 /多线程、生产消费者模型、线程进程对比、线程的方法、线程join、守护线程、线程互斥锁
Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线程join.守护线程.线程互斥锁 目录 Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线 ...
- Python并行编程的几个要点
一.基于线程的并行编程 如何使用Python的线程模块 如何定义一个线程 如何探测一个线程 如何在一个子类中使用线程 Lock和RLock实现线程同步 信号实现线程同步 条件(condition)实现 ...
- Python并行编程(二):基于线程的并行
1.介绍 软件应用中使用最广泛的并行编程范例是多线程.通常一个应用有一个进程,分成多个独立的线程,并行运行.互相配合,执行不同类型的任务. 线程是独立的处理流程,可以和系统的其他线程并行或并发地执行. ...
- python并行编程
一.编程思想 并行编程的思想:分而治之,有两种模型 1.MapReduce:将任务划分为可并行的多个子任务,每个子任务完成后合并得到结果 例子:统计不同形状的个数. 先通过map进行映射到多个子任务, ...
- python并行编程学习之绪论
计算机科学的研究,不仅应该涵盖计算处理所基于的原理,还因该反映这些领域目前的知识状态.当今,计算机技术要求来自计算机科学所有分支的专业人员理解计算机处理的基础的关键,在于知道软件和硬件在所有层面上的交 ...
- 第十篇.4、python并发编程之多线程
一 threading模块介绍 multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍 官网链接:https://docs.python ...
- Python并发编程之多线程使用
目录 一 开启线程的两种方式 二 在一个进程下开启多个线程与在一个进程下开启多个子进程的区别 三 练习 四 线程相关的其他方法 五 守护线程 六 Python GIL(Global Interpret ...
随机推荐
- python操作word之pywin32的安装
PyCharm 2016.2 官网中文汉化破解版 注册码 http://idea.lanyus.com/ 首先下载安装win32com,下载32位的,不然安装的时候可能检测不到python https ...
- H3C路由器和交换机的一些记录
一.模拟器安装需要先安装winpcap,模拟器的脚本是tcl,使用脚本根据拓扑图可以配置模拟器模拟实际的网路线路和设备.二.和模拟器的连接可以使用超级终端,但是超级终端使用的是双字符,这里使用的是Se ...
- jasperreports+Ireport开发搭建
1.报表依赖 <dependency> <groupId>net.sf.jasperreports</groupId> <artifactId>jasp ...
- 1.svn+apache整合
1:安装svn客户端, 并且在客户端下,能建立仓库,在自己的硬盘上,建一个库利用 file:///D:/xx/yy来管理自己的仓库. 2:把svn与apache整合. 2.1为什么与apache一起整 ...
- 逻辑表+session
- 多媒体开发之视频回放---dm642 做rtsp 视频回放功能
之前看过一款海康的视频录制和回放的ipnc 四路就是: 录制还是在本地电脑录制,通过插件在本地生成录制视频和snap图片, 回放估计就是按时间点生成的文件调用本地播放. http://m.blog.c ...
- 【BZOJ】1657: [Usaco2006 Mar]Mooo 奶牛的歌声(单调栈)
http://www.lydsy.com/JudgeOnline/problem.php?id=1657 这一题一开始我想到了nlog^2n的做法...显然可做,但是麻烦.(就是二分+rmq) 然后我 ...
- VC++ ListCtrl Report使用
1.在VC++ 6.0中新建基于对话框的MFC应用程序ListCtrl; 2.在主对话框上添加一个List Control至合适的位置及大小: 3.在对话框OnInitDialog中初始化ListCt ...
- Codeforces Round #311 (Div. 2) A,B,C,D,E
A. Ilya and Diplomas 思路:水题了, 随随便便枚举一下,分情况讨论一下就OK了. code: #include <stdio.h> #include <stdli ...
- jedispool 连 redis
java端在使用jedispool 连接redis的时候,在高并发的时候经常卡死,或报连接异常,JedisConnectionException,或者getResource 异常等各种问题 在使用je ...