Java源码-HashMap(jdk1.8)
一、hash方法
如下是jdk1.8中的源码
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
(1)HashMap允许一个key为空,因此key为null 的hash 值为0。
a、首先获取对象的hashCode()值;
b、然后将hashCode值右移16位;
c、然后将右移后的值与原来的hashCode做异或运算,返回结果。
(其中h>>>16,在JDK1.8中,优化了高位运算的算法,使用了零扩展,无论正数还是负数,都在高位插入0)。
(2)在putVal源码中,我们通过(n-1)&hash获取该对象的键在hashmap中的位置。
(其中hash的值就是(1)中获得的值)
其中n表示的是hash桶数组的长度,并且该长度为2的n次方,这样(n-1)&hash就等价于hash%n。
因为&运算的效率高于%运算。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
... if ((p = tab[i = (n - 1) & hash]) == null)//获取位置
tab[i] = newNode(hash, key, value, null);
...
}
二、putVal方法
jdk1.8中hashmap 的实现是通过数组+链表+红黑树来实现的,如果链表的结点数大于8,那么就将链表重构成红黑树。
完善了一张前利作者的图:
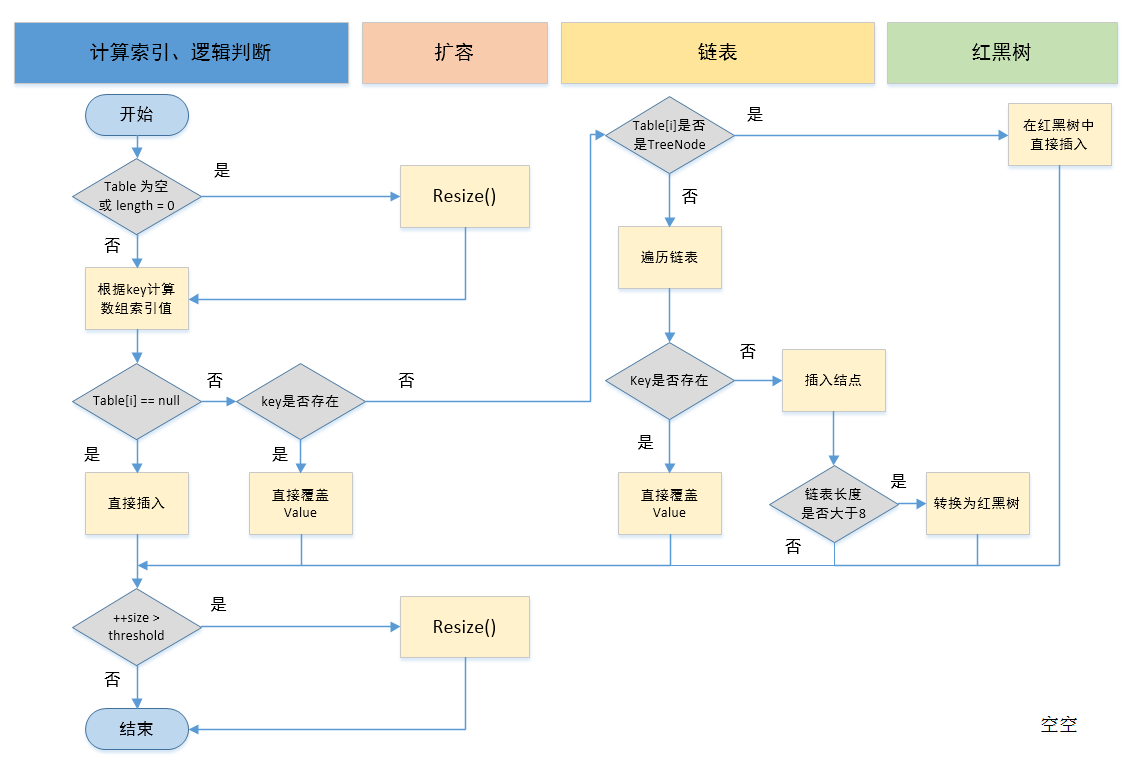
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//如果当前hashMap中无数据,那么调用resize()方法扩容
if ((p = tab[i = (n - 1) & hash]) == null)//如果当前通过hash方法找到的hash桶数组中没有值
tab[i] = newNode(hash, key, value, null);//那么直接在当前结点新建结点对象
else {//如果在当前hash桶数组中该位置有值了
Node<K,V> e; K k;//比较该位置的hash值与传入的参数hash值是否相等,并且key值是否相等
if (p.hash == hash && //即判断是否是同一个key对象
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//如果是,那么将当前数组中的对象p 赋值给 临时对象e,然后在下面替换掉value值就可以了,执行第29行。
else if (p instanceof TreeNode)//如果不是同一key对象,那么判断p是否是红黑树结点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//如果是,那么在红黑树中插入结点
else {//如果不是,那么就是普通的结点了,即存放在链表中
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//找到链表的最后一个结点
p.next = newNode(hash, key, value, null);//插入新节点
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//如果大于8,那么重构成红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;//如果在链表中存在的是同一个key对象,那么直接在下面的方法中替换掉
p = e;
}
}//如果当前位置的对象是同一对象,那么直接替换掉
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//如果超过当前的阀值,那么扩容
resize();
afterNodeInsertion(evict);
return null;
}
三、resize方法
(1) 在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
(2)每次扩展的时候,都是扩展2倍;
(3)扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap不为空的话,就是hash桶数组不为空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值
threshold = Integer.MAX_VALUE;
return oldTab;//返回
}//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组
table = newTab;//将新数组的值复制给旧的hash桶数组
if (oldTab != null) {//进行扩容操作,复制Node对象值到新的hash桶数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果旧的hash桶数组在j结点处不为空,复制给e
oldTab[j] = null;//将旧的hash桶数组在j结点处设置为空,方便gc
if (e.next == null)//如果e后面没有Node结点
newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新的数组长度求模获得存储位置
else if (e instanceof TreeNode)//如果e是红黑树的类型,那么添加到红黑树中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//将Node结点的next赋值给next
if ((e.hash & oldCap) == 0) {//如果结点e的hash值与原hash桶数组的长度作与运算为0
if (loTail == null)//如果loTail为null
loHead = e;//将e结点赋值给loHead
else
loTail.next = e;//否则将e赋值给loTail.next
loTail = e;//然后将e复制给loTail
}
else {//如果结点e的hash值与原hash桶数组的长度作与运算不为0
if (hiTail == null)//如果hiTail为null
hiHead = e;//将e赋值给hiHead
else
hiTail.next = e;//如果hiTail不为空,将e复制给hiTail.next
hiTail = e;//将e复制个hiTail
}
} while ((e = next) != null);//直到e为空
if (loTail != null) {//如果loTail不为空
loTail.next = null;//将loTail.next设置为空
newTab[j] = loHead;//将loHead赋值给新的hash桶数组[j]处
}
if (hiTail != null) {//如果hiTail不为空
hiTail.next = null;//将hiTail.next赋值为空
newTab[j + oldCap] = hiHead;//将hiHead赋值给新的hash桶数组[j+旧hash桶数组长度]
}
}
}
}
}
return newTab;
}
四、get方法
(1)get(Object key)
一般我们是通过get(key)来获取对象的键值,在jdk1.8源码中,通过getNode(hash(key),key)来获取结点对象,如果返回的结果不为空,那么就表示有对应的结点,返回e.value。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
(2)getNode(int hash, Object key)
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // 总是从第一个检查开始 ,比较hash值 和key值
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)//如果是红黑树类型,那么在红黑树中查找
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);//循环遍历
}
}
return null;//表示没有找到
}
(3)啦啦啦
Java源码-HashMap(jdk1.8)的更多相关文章
- java源码--HashMap
一.HashMap简介 1.1.HashMap概述 HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射.此类不保证映射的顺序,假定哈希函数将元素 ...
- java源码--HashMap扩容机制学习
待完成 Java中hash算法细述 https://blog.csdn.net/majinggogogo/article/details/80260400 java HashMap源码分析(JDK8) ...
- Java源码 HashMap<K,V>
HashMap类 https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html public class HashMap<K, ...
- java源码-HashMap源码分析
这次开始分析JDK8中的HashMap源码. 首先理解HashMap中几个关键变量, TREEIFY_THRESHOLD 链表转换红黑树扩容值 table 数组+链表+红黑树 size 当前存储数 ...
- Java源码——HashMap的源码分析及原理学习记录
学习HashMap时,需要带着这几个问题去,会有很大的收获: 一.什么是哈希表 二.HashMap实现原理 三.为何HashMap的数组长度一定是2的次幂? 四.重写equals方法需同时重写hash ...
- java源码-HashMap类设计
map(内部interface Entry<K,V>)->abstractMap(定义视图 entrySet抽象方法)->hashMap(静态内部类Node(继承Entry&l ...
- Java源码 HashMap.roundUpToPowerOf2原理
int rounded = number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (rounded = Integer.highestOneBit(nu ...
- 死磕Java之聊聊HashMap源码(基于JDK1.8)
死磕Java之聊聊HashMap源码(基于JDK1.8) http://cmsblogs.com/?p=4731 为什么面试要问hashmap 的原理
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
随机推荐
- 【EF】Entity Framework实现属性映射约定
Entity Framework Code First属性映射约定中“约定”一词,在原文版中为“Convention”,翻译成约定或许有些不好理解,这也是网上比较大多数的翻译,我们就当这是Entity ...
- AtCoder Grand Contest 019 A: Ice Tea Store
tourist出的题诶!想想就很高明,老年选手可能做不太动.不过A题还是按照惯例放水的. AtCoder Grand Contest 019 A: Ice Tea Store 题意:买0.25L,0. ...
- 【bzoj3456】城市规划 容斥原理+NTT+多项式求逆
题目描述 求出n个点的简单(无重边无自环)无向连通图数目mod 1004535809(479 * 2 ^ 21 + 1). 输入 仅一行一个整数n(<=130000) 输出 仅一行一个整数, 为 ...
- 【bzoj4695】最假女选手 线段树区间最值操作
题目描述 给定一个长度为 N 序列,编号从 1 到 N .要求支持下面几种操作:1.给一个区间[L,R] 加上一个数x 2.把一个区间[L,R] 里小于x 的数变成x 3.把一个区间[L,R] 里大于 ...
- 【刷题】BZOJ 2599 [IOI2011]Race
Description 给一棵树,每条边有权.求一条简单路径,权值和等于K,且边的数量最小.N <= 200000, K <= 1000000 Input 第一行 两个整数 n, k 第二 ...
- 【BZOJ2460】元素(贪心,线性基)
[BZOJ2460]元素(贪心,线性基) 题面 BZOJ Description 相传,在远古时期,位于西方大陆的 Magic Land 上,人们已经掌握了用魔 法矿石炼制法杖的技术.那时人们就认识到 ...
- 【入门OJ】2003: [Noip模拟题]寻找羔羊
这里可以复制样例: 样例输入: agnusbgnus 样例输出: 6 这里是链接:[入门OJ]2003: [Noip模拟题]寻找羔羊 这里是题解: 题目是求子串个数,且要求简单去重. 对于一个例子(a ...
- Codeforces 671D. Roads in Yusland(树形DP+线段树)
调了半天居然还能是线段树写错了,药丸 这题大概是类似一个树形DP的东西.设$dp[i]$为修完i这棵子树的最小代价,假设当前点为$x$,但是转移的时候我们不知道子节点到底有没有一条越过$x$的路.如果 ...
- Codeforces 582C. Superior Periodic Subarrays(数学+计数)
首先可以把 i mod n=j mod n的看成是同一类,i mod s=j mod s的也看成是同一类,也就是i mod gcd(s,n)的是同一类,很好理解,但是不会数学证明...大概可以想成数轴 ...
- Codeforces 585E. Present for Vitalik the Philatelist(容斥)
好题!学习了好多 写法①: 先求出gcd不为1的集合的数量,显然我们可以从大到小枚举计算每种gcd的方案(其实也是容斥),或者可以直接枚举gcd然后容斥(比如最大值是6就用2^cnt[2]-1+3^c ...