python实现一个层次聚类方法
层次聚类(Hierarchical Clustering)
一.概念
层次聚类不需要指定聚类的数目,首先它是将数据中的每个实例看作一个类,然后将最相似的两个类合并,该过程迭代计算只到剩下一个类为止,类由两个子类构成,每个子类又由更小的两个子类构成。如下图所示:
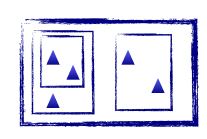
二.合并方法
在聚类中每次迭代都将两个最近的类进行合并,这个类间的距离计算方法常用的有三种:
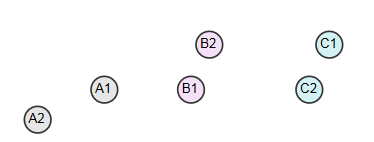
1.单连接聚类(Single-linkage clustering)
在单连接聚类中,两个类间的距离定义为一个类的所有实例到另一个类的所有实例之间最短的那个距离。如上图中类A(A1,A2),B(B1,B2),C(C1,C2),A类和B类间的最短距离是A1到B1,所以A类与B类更近,所有A和B合并。
2.全连接聚类(Complete-linkage clustering)
在全连接聚类中,两个类间的距离定义为一个类的所有实例到另一个类的所有实例之间最长的那个距离。图中A类和B类间最长距离是A2到B2,B类和C类最长距离是B1到C1,distance(B1-C1)<distance(A2-B2),所以B类和C类合并在一起。
3.平均连接聚类(Average-linkage clustering)
在平均连接聚类中,类间的距离为一个类的所有实例到另一个类的所有实例的平均距离。
三.python实现(单连接)
#!/usr/bin/python
# -*- coding: utf-8 -*- from queue import PriorityQueue
import math
import codecs """
层次聚类
"""
class HCluster: #一列的中位数
def getMedian(self,alist):
tmp = list(alist)
tmp.sort()
alen = len(tmp)
if alen % 2 == 1:
return tmp[alen // 2]
else:
return (tmp[alen // 2] + tmp[(alen // 2) - 1]) / 2 #对数值型数据进行归一化,使用绝对标准分[绝对标准差->asd=sum(x-u)/len(x),x的标准分->(x-u)/绝对标准差,u是中位数]
def normalize(self,column):
median = self.getMedian(column)
asd = sum([abs(x - median) for x in column]) / len(column)
result = [(x - median) / asd for x in column]
return result def __init__(self,filepath):
self.data={}
self.counter=0
self.queue=PriorityQueue()
line_1=True#开头第一行
with codecs.open(filepath,'r','utf-8') as f:
for line in f:
#第一行为描述信息
if line_1:
line_1=False
header=line.split(',')
self.cols=len(header)
self.data=[[] for i in range(self.cols)]
else:
instances=line.split(',')
toggle=0
for instance in range(self.cols):
if toggle==0:
self.data[instance].append(instances[instance])
toggle=1
else:
self.data[instance].append(float(instances[instance]))
#归一化数值列
for i in range(1,self.cols):
self.data[i]=self.normalize(self.data[i]) #欧氏距离计算元素i到所有其它元素的距离,放到邻居字典中,比如i=1,j=2...,结构如i=1的邻居-》{2: ((1,2), 1.23), 3: ((1, 3), 2.3)... }
#找到最近邻
#基于最近邻将元素放到优先队列中
#data[0]放的是label标签,data[1]和data[2]是数值型属性
rows=len(self.data[0])
for i in range(rows):
minDistance=10000
nearestNeighbor=0
neighbors={}
for j in range(rows):
if i!=j:
dist=self.distance(i,j)
if i<j:
pair=(i,j)
else:
pair=(j,i)
neighbors[j]=(pair,dist)
if dist<minDistance:
minDistance=dist
nearestNeighbor=j
#创建最近邻对
if i<nearestNeighbor:
nearestPair=(i,nearestNeighbor)
else:
nearestPair=(nearestNeighbor,i)
#放入优先对列中,(最近邻距离,counter,[label标签名,最近邻元组,所有邻居])
self.queue.put((minDistance,self.counter,[[self.data[0][i]],nearestPair,neighbors]))
self.counter+=1 #欧氏距离,d(x,y)=math.sqrt(sum((x-y)*(x-y)))
def distance(self,i,j):
sumSquares=0
for k in range(1,self.cols):
sumSquares+=(self.data[k][i]-self.data[k][j])**2
return math.sqrt(sumSquares) #聚类
def cluster(self):
done=False
while not done:
topOne=self.queue.get()
nearestPair=topOne[2][1]
if not self.queue.empty():
nextOne=self.queue.get()
nearPair=nextOne[2][1]
tmp=[]
#nextOne是否是topOne的最近邻,如不是继续找
while nearPair!=nearestPair:
tmp.append((nextOne[0],self.counter,nextOne[2]))
self.counter+=1
nextOne=self.queue.get()
nearPair=nextOne[2][1]
#重新加回Pop出的不相等最近邻的元素
for item in tmp:
self.queue.put(item) if len(topOne[2][0])==1:
item1=topOne[2][0][0]
else:
item1=topOne[2][0]
if len(nextOne[2][0])==1:
item2=nextOne[2][0][0]
else:
item2=nextOne[2][0]
#联合两个最近邻族成一个新族
curCluster=(item1,item2)
#下面使用单连接方法建立新族中的邻居距离元素,一:计算上面新族的最近邻。二:建立新的邻居。如果 item1和item3距离是2,item2和item3距离是4,则在新族中的距离是2
minDistance=10000
nearestPair=()
nearestNeighbor=''
merged={}
nNeighbors=nextOne[2][2]
for key,value in topOne[2][2].items():
if key in nNeighbors:
if nNeighbors[key][1]<value[1]:
dist=nNeighbors[key]
else:
dist=value
if dist[1]<minDistance:
minDistance=dist[1]
nearestPair=dist[0]
nearestNeighbor=key
merged[key]=dist
if merged=={}:
return curCluster
else:
self.queue.put((minDistance,self.counter,[curCluster,nearestPair,merged]))
self.counter+=1 if __name__=='__main__':
hcluser=HCluster('filePath')
cluser=hcluser.cluster()
print(cluser)
参考:1.machine.learning.an.algorithmic.perspective.2nd.edition.
2.a programmer's guide to data mining
python实现一个层次聚类方法的更多相关文章
- Python机器学习——Agglomerative层次聚类
层次聚类(hierarchical clustering)可在不同层次上对数据集进行划分,形成树状的聚类结构.AggregativeClustering是一种常用的层次聚类算法. 其原理是:最初将 ...
- 挑子学习笔记:BIRCH层次聚类
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/6129425.html 本文是“挑子”在学习BIRCH算法过程中的笔记摘录,文中不乏一些个人理解,不当之处望 ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- python类:magic魔术方法
http://blog.csdn.net/pipisorry/article/details/50708812 魔术方法是面向对象Python语言中的一切.它们是你可以自定义并添加"魔法&q ...
- (转)python类:magic魔术方法
原文:https://blog.csdn.net/pipisorry/article/details/50708812 版权声明:本文为博主皮皮http://blog.csdn.net/pipisor ...
- 【python】利用scipy进行层次聚类
参考博客: https://joernhees.de/blog/2015/08/26/scipy-hierarchical-clustering-and-dendrogram-tutorial/ 层次 ...
- 送你一个Python 数据排序的好方法
摘要:学习 Pandas排序方法是开始或练习使用 Python进行基本数据分析的好方法.最常见的数据分析是使用电子表格.SQL或pandas 完成的.使用 Pandas 的一大优点是它可以处理大量数据 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
随机推荐
- idea - maven子工程找不到父工程pom
1.应该先构建父项目,再构建子项目.因为子项目依赖于父项目.即父项目先install到本地
- Windows系统下同时安装Python2和Python3
Windows系统下同时安装Python2和Python3 说明 有时由于工作需求我们需要在Python2版本下面进行一些开发,有时又需要Python3以上的版本,那么我们怎么在一台电脑上同时安装多个 ...
- 使用Python基于OpenCV的验证码识别
Blog:https://blog.csdn.net/qq_40962368/article/details/89312429(Verification_Code_Identification) 步骤 ...
- springboot mongodb jpa常用方法整理
官方文档https://docs.spring.io/spring-data/data-mongodb/docs/current/reference/html/index.html 查询: ***** ...
- 枚举类型C语言规律用法总结
注:以下全部代码的执行环境为VC++ 6.0 在程序中,可能需要为某些整数定义一个别名,我们可以利用预处理指令#define来完成这项工作,您的代码可能是: #define MON 1#define ...
- loj 6043「雅礼集训 2017 Day7」蛐蛐国的修墙方案
loj 爆搜? 爆搜! 先分析一下,因为我们给出的是一个排列,然后让\(i\)给\(p_i\)连边,那么我们一定会得到若干个环,最后要使得所有点度数为1,也就是这些环有完备匹配,那么最后一定全是偶环. ...
- 图片哈希概论及python中如何实现对比两张相似的图片
Google 以图搜图的原理,其中的获取图片 hash 值的方法就是 AHash. 每张图片都可以通过某种算法得到一个 hash 值,称为图片指纹,两张指纹相近的图片可以认为是相似图片. 以图搜图的原 ...
- with as 语句
with就是一个sql片段,供后面的sql语句引用. 详情参见:https://www.cnblogs.com/Niko12230/p/5945133.html
- 第九篇 float浮动
float浮动 首先老师要声明,浮动这一块,和边距.定位相比,它是比较难的,但是用它,页面排版会更好. 这节课就直接上代码,看着代码去学浮动. 我们先弄一个div,给它一个背景颜色: HTML ...
- java复制文件范例代码
String url1 = "F:\\SuperMap-Projects\\region.udb";// 源文件路径 try { for(int i=1;i<101;i++) ...