机器学习【一】K最近邻算法


from sklearn.neighbors import KNeighborsClassifier #导入KNN分类器
import matplotlib.pyplot as plt #导入画图工具
from sklearn.model_selection import train_test_split #导入数据集拆分工具
data = make_blobs(n_samples=200, centers = 2,random_state = 8) #生成样本数为200,分类为2的数据
X ,y = data #将生成的数据可视化
plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.spring,edgecolor='k')
plt.show()

接下来用KNN拟合这些数据:
clf = KNeighborsClassifier()
clf.fit(X,y)
x_min,x_max = X[:,0].min() -1,X[:,0].max() + 1
y_min,y_max = X[:,1].min() -1,X[:,1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx,yy,Z,cmap=plt.cm.Pastel1)
plt.scatter(X[:, 0],X[:, 1],c = y,cmap = plt.cm.spring, edgecolor = 'k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
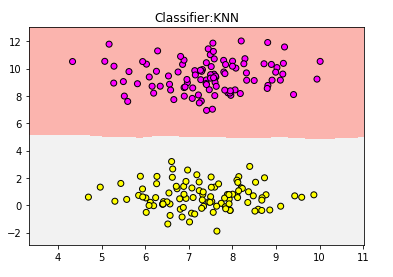

可见,分到了浅灰色一类
验证代码如下:
2.处理多元分类任务
data2 = make_blobs(n_samples=500, centers = 5,random_state = 8)
X2,y2 = data2
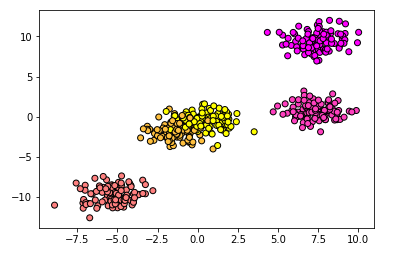
#用散点图将数据可视化
plt.scatter(X2[:,0],X2[:,1],c = y2,cmap = plt.cm.spring,edgecolor='k')
plt.show()
用KNN建立模型拟合数据:
clf = KNeighborsClassifier()
clf.fit(X2,y2)
x_min,x_max = X2[:,0].min() -1,X2[:,0].max() + 1
y_min,y_max = X2[:,1].min() -1,X2[:,1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx,yy,Z,cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0],X2[:, 1],c = y2,cmap = plt.cm.spring, edgecolor = 'k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
plt.show()
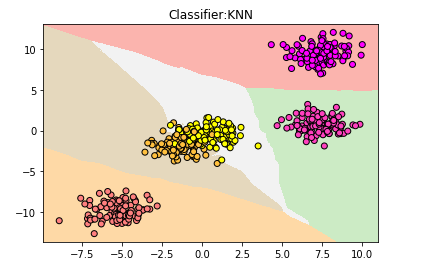
但仍然有小部分数据进入错误的分类

3.用于回归分析
make_regression函数,一个非常好的用于回归分析的数据集生成器
from sklearn.datasets import make_regression
#生成特征数量为1,噪音为50的数据集
X,y = make_regression(n_features=1,n_informative=1,noise=50,random_state=8)
#用散点图将数据点可视化
plt.scatter(X,y,c='orange',edgecolor='k')
plt.show()
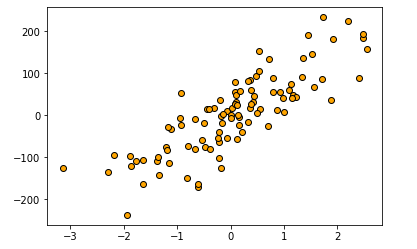
如上,横轴代表样本特征的数值,范围大概在-3~3;
纵轴代表样本的测定值,范围在-250~250
使用KNN进行回归分析:
#导入用于回归分析的KNN模型
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor()
#利用KNN模型拟合数据
reg.fit(X,y)
#把预测结果可视化
z = np.linspace(-3,3,200).reshape(-1,1)
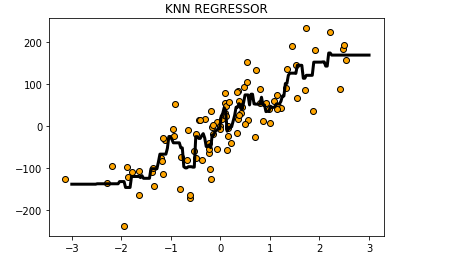
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',linewidth=3)
#添加标题
plt.title("KNN REGRESSOR")
plt.show()
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor(n_neighbors=2)
#利用KNN模型拟合数据
reg.fit(X,y)
#把预测结果可视化
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',linewidth=3)
#添加标题
plt.title("KNN REGRESSOR:n_neighbors=2")
plt.show()

KNN实战——酒的分类
使用load_wine函数载入的酒数据集,是一种Bunch对象,包括键【keys】和数值【values】
检查酒的数据集有哪些键:
from sklearn.datasets import load_wine
#载入数据集
wine_dataset = load_wine()
#打印数据集中的键
print(wine_dataset.keys())
#打印数据集中的数值,详见博客--机器学习入门
#print(wine_dataset.values())

数据集中有多少样本【samples】变量【features】:
可以使用.shape语句告诉我们大概的数据轮廓
from sklearn.datasets import load_wine
#载入数据集
wine_dataset = load_wine()
#打印数据集中有多少样本和变量
print(wine_dataset['data'].shape)

即有178个样本,13个特征变量
#查看更细节的信息
print(wine_dataset['DESCR'])
生成训练数据集和测试数据集
sklearn中,有一个 train_test_split 函数,用来帮助用户把数据集拆分的工具
原理:
将数据集随机排列,默认情况下,将75%的数据及对应的标签划到训练数据集,将25%的数据和对应的标签划归到测试数据集
一般用大写的X表示数据特征,小写的y表示数据对应的标签
因为X是一个二维数组,也称为矩阵,y是一个一维数组,或者说是一个向量
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#将数据集拆分为训练+ 测试集
X_train,X_test,y_train,y_test = train_test_split(wine_dataset['data'],wine_dataset['target'],random_state=0)
上述,train_test_split 函数生成一个伪随机数,并根据这个伪随机数对数据集拆分
相同的 random_state 参数,会一直生成同样的伪随机数,但当这个值我们设为0的时候,或者保持缺省的时候,每次生成的伪随机数均不同
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#将数据集拆分为训练+ 测试集
X_train,X_test,y_train,y_test = train_test_split(wine_dataset['data'],wine_dataset['target'],random_state=0)
#训练集中特征向量的形态
print(X_train.shape)
#测试集中特征向量的形态
print(X_test.shape)
#训练集中目标的形态
print(y_train.shape)
#测试集中目标的形态
print(y_test.shape)

使用KNN建模
#导入KNN分类模型
from sklearn.neighbors import KNeighborsClassifier
#指定模型的n_neighbors参数值为1
knn = KNeighborsClassifier(n_neighbors=1)
#使用模型对数据拟合
knn.fit(X_train,y_train)
print(knn)

# knn的拟合方法,把自身作为结果返回,从结果中可以看到模型的全部参数设定【除了n_neighbors=1,其余默认即可】
KNN根据训练集建立模型,在训练数据集中寻找和新输入的数据最近的数据点,然后把这个数据点的标签,分给新的数据点
代码详细解释:
机器学习模块,都是在固定的类中运行的
而KNN是在neighbors模块的KNeighborsClassifier类中运行
从一个类中创建对象的时候,需要给模型一个参数,对于KNeighborsClassifier类最关键的参数就是近邻的数量,也就是n_neighbors
knn则是在该类中创建的一个对象
该对象中,有一个“拟合”的方法——> fit 【用此建模】
建模的依据就是训练集中的样本数据X_train和对应的标签y_train
使用模型对新样本的分类进行预测
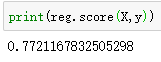
print(knn.score(X_test,y_test))
测试集的得分:
0.7555555555555555
对新酒进行分类预测:
import numpy as np
#输入新的数据点
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
#使用.predict预测
pre = knn.predict(X_new)
print(wine_dataset['target_names'][pre])
['class_2']
KNN不适用:
需要提前对数据集认真的预处理、对规模超大的数据集拟合的时间较长、对高维数据集拟合欠佳、对稀疏数据集无能为力
在高维数据集中表现良好的算法:广义线性模型
机器学习【一】K最近邻算法的更多相关文章
- 机器学习-K最近邻算法
一.介绍 二.编程 练习一(K最近邻算法在单分类任务的应用): import numpy as np #导入科学计算包import matplotlib.pyplot as plt #导入画图工具fr ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 《算法图解》——第十章 K最近邻算法
第十章 K最近邻算法 1 K最近邻(k-nearest neighbours,KNN)——水果分类 2 创建推荐系统 利用相似的用户相距较近,但如何确定两位用户的相似程度呢? ①特征抽取 对水果 ...
- [笔记]《算法图解》第十章 K最近邻算法
K最近邻算法 简称KNN,计算与周边邻居的距离的算法,用于创建分类系统.机器学习等. 算法思路:首先特征化(量化) 然后在象限中选取目标点,然后通过目标点与其n个邻居的比较,得出目标的特征. 余弦相似 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
- K最近邻算法项目实战
这里我们用酒的分类来进行实战练习 下面来代码 1.把酒的数据集载入到项目中 from sklearn.datasets import load_wine #从sklearn的datasets模块载入数 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
随机推荐
- php关于jquery ajax json不返回数据的问题
分析原因: 1.php端代码有错导致echo输出错误,导致ajax返回函数不执行 2.jquery版本原因 3.juqery前端script代码问题
- java高并发核心要点|系列1|开篇
在java高并发编程,有几个很重要的内容: 1.CAS算法 2.CPU重排序 3.缓存行伪共享 我们先来说说高并发世界中的主要关键问题是什么? 是数据共享. 因为多线程之间要共享数据,就会遇到各种问题 ...
- javascript之定时器的使用
一:什么是定时器 (一)无限循环定时器 <script> window.onload = function(){ function test(){ alert("test&quo ...
- apk反编译(仅供娱乐)
第一个文件夹里面放apk,第二个解析classes.dex,第三个查看java代码,下面三个apktool用来解析apk文件, 记得在环境变量中配置apktool,路径为apktool所在路径 1.解 ...
- Maven:mirror和repository
1 Repository(仓库) 1.1 Maven仓库主要有2种: remote repository:相当于公共的仓库,大家都能访问到,一般可以用URL的形式访问 local repository ...
- c++string int转化简单写法
#include<iostream> #include<string> #include<sstream> //定义了stringstream类 using nam ...
- 关于python pip安装第三方库 jieba 中文分词工具后提示"ImportError: cannot import name 'Random'"报错问题
具体错误提示如下: >>> import jieba Traceback (most recent call last): File "<stdin>" ...
- python学习理论
结论 其实学python这本书 不一定要全部敲一遍 在“”动手试一试“”里面 把这篇学到的东西测试一下就算是掌握了 要在实际工作场景当中使用还需要进一步练习这样做的话 比较好一点 边学边测试 加深掌握 ...
- Buffer转成字符串
如果data为buffer格式,则: data.toString()
- anaconda 安装caffe,cntk,theano-未整理
一,anancona 安装 https://repo.anaconda.com/archive/ conda create -n caffe_gpu -c defaults python=3.6 ca ...