Hadoop2.7.4 yarn(HA)集群搭建步骤(CentOS7)
群节点分配:
Park01:Zookeeper、NameNode(active)、ResourceManager(active)
Park02:Zookeeper、NameNode(standby)
Park03:Zookeeper、ResourceManager(standby)
Park04:DataNode、NodeManager、JournalNode
Park05:DataNode、NodeManager、JouralNode
Park06:DataNode、NodeManager、JournalNode
安装步骤:
0、永久关闭每台机器的防火墙
systemctl stop firewalld.service
1、为每台机器配置主机名(每台机器改为固定ip)
Park01->hadoop01
Park02->hadoop02
Park03->hadoop03
Park04->hadoop04
Park05->hadoop05
Park06->hadoop06
修改host文件,并hostname更改主机名
2、通过远程命令将配置好的hosts文件scp到其他5台节点上
例:scp /etc/hosts hadoop02:/etc
3、为每台机器配置ssh免秘登录
ssh-keygen
ssh-copy-id root@hadoop01(分别发送到6台节点上)
4、前三台机器安装和配置zookeeper
配置conf目录下的zoo.cfg以及创建myid文件(安装步骤略)
5、为每台机器安装jdk和配置jdk环境
6、为每台机器配置主机名
hostnamectl set-hostname hadoop01
7、节点的hadoop
配置 hadoop-env.sh
配置jdk安装所在目录
配置hadoop配置文件所在目录
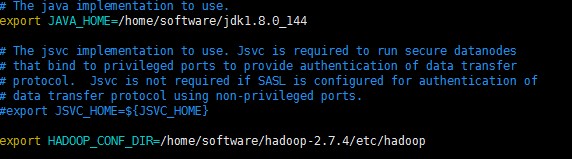
8、配置core-site.xml
<configuration>
<!--用来指定hdfs的老大,ns为固定属性名,表示两个namenode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.4/tmp</value>
</property>
<!--执行zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
节点的hdfs-site.xml
<configuration>
<!--执行hdfs的nameservice为ns,和core-site.xml保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns下有两个namenode,分别是nn1,nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上的存放位置,这样,namenode2可以 从jn集群里获取
最新的namenode的信息,达到热备的效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
;hadoop06:8485/ns</value>
</property>
<!--指定JournalNode存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-2.7.4/journal</value>
</property>
<!--开启 namenode 故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置隔离机制的ssh登录秘钥所在的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode数据存放的位置,可以不配置,如果不配置,默认用的是
core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-2.7.4/tmp/namenode</value>
</property>
<!--配置datanode数据存放的位置,可以不配置,如果不配置,默认用的是
core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/software/hadoop-2.7.4/tmp/datanode</value>
</property>
<!--配置block副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置 hdfs 的操作权限, false 表示任何用户都可以在 hdfs 上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
10、 配置 mapred-site.xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
11、配置yarn-site.xml
<configuration>
<!--开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定两个 resourcemanager 的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1,rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
<description>For multiple zk services, separate them with comma</description>
</property>
<!--指定YARN HA的名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager 获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
12、配置slaves文件
配置代码:
hadoop04
hadoop05
hadoop06
13、配置 hadoop 的环境变量(可不配)
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.4
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
14、 根据配置文件,创建相关的文件夹,用来存放对应数据
在hadoop-2.7.4目录下创建:
①journal目录
②创建tmp目录
③在tmp目录下,分别创建namenode目录和datanode目录
台机器上
比如向hadoop02节点传输:
scp -r hadoop-2.7.4 hadoop02:/home/software
Hadoop集群启动
16、启动zookeeper集群
在Zookeeper安装目录的bin目录下执行:sh zkServer.sh start
利用sh zkServer.sh status检查状态
17、格式化zookeeper
在zk的leader节点上执行:
hdfs zkfc -formatZK,这个指令的作用是在zookeeper集群上生成ha节点 (ns节点)

注:18--24步可以用一步来替代:进入hadoop安装目录的sbin目录,执行: start-dfs.sh 。 但建议还是按部就班来执行,比较可靠。
18、启动journalnode集群
节点上执行:
切换到hadoop安装目录的sbin目录下,执行:
sh hadoop-daemons.sh start journalnode
然后执行jps命令查看:
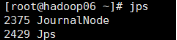
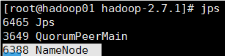
19、节点的namenode
节点上执行:
hadoop namenode -format
节点的namenode
节点上执行:
hadoop-daemon.sh start namenode
21、节点的namenode节点变为standby namenode节点
节点上执行:
hdfs namenode -bootstrapStandby

22、 节点的 namenode 节点
节点上执行:
hadoop-daemon.sh start namenode
23、在04,05,06节点上启动datanode节点
在 04,05,06 节点上执行:hadoop-daemon.sh start datanode
24、启动zkfc(启动FalioverControllerActive)
在01,02节点上执行:
hadoop-daemon.sh start zkfc
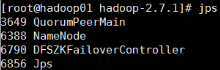
25、节点上启动主Resourcemanager
节点上执行:start-yarn.sh
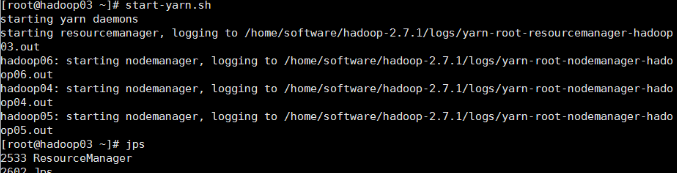
启动成功后,04,05,06节点上应该有nodemanager 的进程
节点上启动副 Resoucemanager
节点上执行:yarn-daemon.sh start resourcemanager
27、测试
输入地址: http://192.168.234.21:50070 ,查看 namenode 的信息,是active状态 的
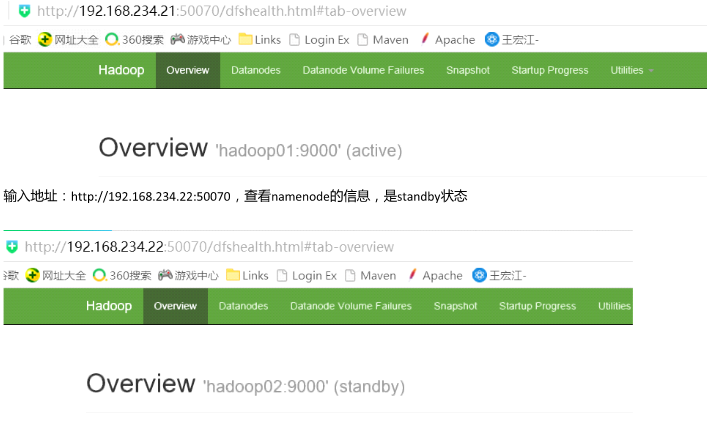
节点的namenode,此时返现standby的namenode变为active。
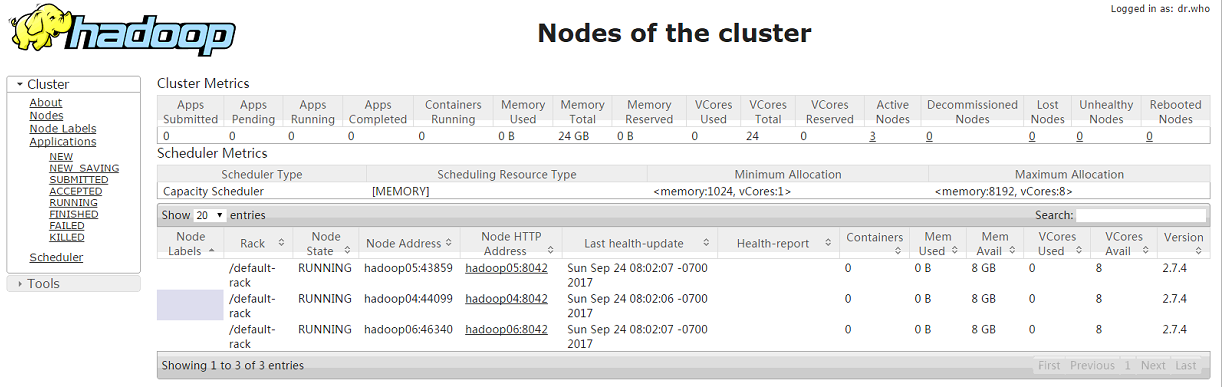
28、 查看 yarn 的管理地址
端口)
Hadoop2.7.4 yarn(HA)集群搭建步骤(CentOS7)的更多相关文章
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- hadoop2.6.4的HA集群搭建超详细步骤
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.6.4又增加了YARN HA 注意:apache提供的hadoop-2.6.4的安装包是 ...
- hadoop yarn HA集群搭建
可先完成hadoop namenode HA的搭建:http://www.cnblogs.com/kisf/p/7458519.html 搭建yarnde HA只需要在namenode HA配置基础上 ...
- hadoop2.8 ha 集群搭建
简介: 最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- Spark1.3.1 On Yarn的集群搭建
下面给出的是spark集群搭建的环境: 操作系统:最小安装的CentOS 7(下载地址) Yarn对应的hadoop版本号:Hadoop的Cloudera公司发行版Hadoop2.6.0-CDH5.4 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop2.6.5高可用集群搭建
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3, m4, m5这五部机, 每部主机的用户名 ...
随机推荐
- React Native调用系统浏览器
import { Linking} from 'react-native'; //使用系统浏览器访问指定URLexport const contactBaidu = () => { var ba ...
- CTF—WEB—sql注入之无过滤有回显最简单注入
sql注入基础原理 一.Sql注入简介 Sql 注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击,它目前黑客对数据库进行攻击的最常用手 ...
- 快速安装pycharm,最详细的pycharm安装图文教程
大家都知道python的开发工具Pycharm吧,它是由JetBrains打造的一款Python IDE,它功能强大,已经是python开发者使用最多的编辑工具.首先,它支持多平台(Linux.WIn ...
- 【AI-人工智能-mmdetection】ModuleNotFoundError: No module named 'mmdet.version'
在集成 mmdetection 框架时遇到这样的问题. ModuleNotFoundError: No module named 'mmdet.version' mmdetection 框架搭建过程很 ...
- Angular5 tslint错误:The selector of the component “XXXComponent” should be used as element
错误描述 在项目中自己封装了一个 select 组件 @Component({ selector: '[app-choosen-select]', templateUrl: './selectcomm ...
- 2019JAVA第三次实验报告
Java实验报告 班级 计科二班 学号 20188442 姓名 吴怡君 完成时间 2019.9.24 评分等级 实验三 String类的应用 一.实验目的 掌握类String类的使用: 学会使用JDK ...
- 第八周总结and实验
1.实验目的 理解异常的基本概念:掌握异常处理方法及熟悉常见异常的捕获方法. 2.实验要求 练习捕获异常.声明异常.抛出异常的方法.熟悉try和catch子句的使用.掌握自定义异常类的方法. 3.实验 ...
- CDH6.2扩容
参考: yum方式扩容: https://www.cnblogs.com/yinzhengjie/articles/11104776.html 二进制包方式扩容: https://www.cnblog ...
- jira:恢复数据:AO_187CCC_SIDEBAR_LINK
JIRA 恢复数据时报错 ,关键词是找不到 AO_187CCC_SIDEBAR_LINK. 经网上查为 mysql connect jar 包 的版本过高所致. 降低版本后,成功导入数据.
- [POI2011]SMI-Garbage 题解
题面 想必各位大佬一定想到了把现在和目标值不一致的边加入到一个新建的图上: 问题就变为了在新的图上寻找有多少个欧拉回路,并输出这些路径: 我们可以用栈来记录情况,然后对于会回答稍微处理处理就好了: # ...