Task8.循环和递归神经网络
RNN提出的背景:
RNN通过每层之间节点的连接结构来记忆之前的信息,并利用这些信息来影响后面节点的输出。RNN可充分挖掘序列数据中的时序信息以及语义信息,这种在处理时序数据时比全连接神经网络和CNN更具有深度表达能力,RNN已广泛应用于语音识别、语言模型、机器翻译、时序分析等各个领域。
RNN的训练方法——BPTT算法(back-propagation through time)
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。 这里寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。
这个式子看起来简单但是求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求导过程。RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。 W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻 L对W的偏导数为:
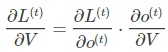
这个式子看起来简单但是求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求导过程。RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。 W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻 L对W的偏导数为:

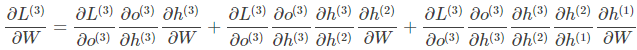
双向RNN:
Bidirectional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且 还与之后的序列有关,例如:预测一个语句中缺失的词语那么需要根据上下文进 行预测;Bidirectional RNN是一个相对简单的RNNs,由两个RNNs上下叠加在 一起组成。输出由这两个RNNs的隐藏层的状态决定。
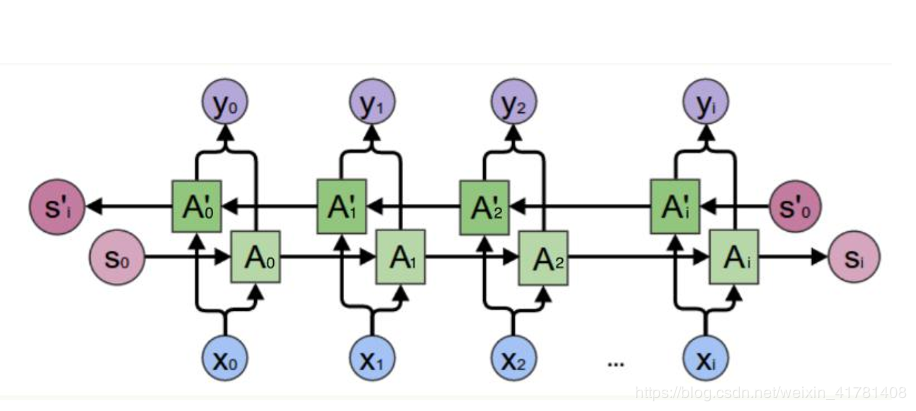
LSTM
上面介绍的RNN模型,存在“长期依赖”的问题。模型在预测“大海的颜色是”下一个单词时,很容易判断为“蓝色”,因为这里相关信息与待预测词的位置相差不大,模型不需要记忆这个短句子之前更长的上下文信息。但当模型预测“十年前,北京的天空很蓝,但随着大量工厂的开设,废气排放监控不力,空气污染开始变得越来越严重,渐渐地,这里的天空变成了”下一个单词时,依靠“短期依赖”就不能很好的解决这类问题,因为仅仅根据“这里的天空变成了”这一小段,后一个单词可以是“蓝色”,也可以是“灰色”。上节描述的简单RNN结构可能无法学习到这种“长期依赖”的信息,LSTM可以很好的解决这类问题。
与简单RNN结构中单一tanh循环体不同的是,LSTM使用三个“门”结构来控制不同时刻的状态和输出。所谓的“门”结构就是使用了sigmoid激活函数的全连接神经网络和一个按位做乘法的操作,sigmoid激活函数会输出一个0~1之间的数值,这个数值描述的是当前有多少信息能通过“门”,0表示任何信息都无法通过,1表示全部信息都可以通过。其中,“遗忘门”和“输入门”是LSTM单元结构的核心。下面我们来详细分析下三种“门”结构。
遗忘门,用来让RNN“忘记”之前没有用的信息。比如“十年前,北京的天空是蓝色的”,但当看到“空气污染开始变得越来越严重”后,RNN应该忘记“北京的天空是蓝色的”这个信息。遗忘门会根据当前时刻节点的输入Xt、上一时刻节点的状态C(t-1)和上一时刻节点的输出h(t-1)来决定哪些信息将被遗忘。
输入门,用来让RNN决定当前输入数据中哪些信息将被留下来。在RNN使用遗忘门“忘记”部分之前的信息后,还需要从当前的输入补充最新的记忆。输入门会根据当前时刻节点的输入Xt、上一时刻节点的状态C(t-1)和上一时刻节点的输出h(t-1)来决定哪些信息将进入当前时刻节点的状态Ct,比如看到“空气污染开始变得越来越严重”后,模型需要记忆这个最新的信息。
输出门,LSTM在得到最新节点状态Ct后,结合上一时刻节点的输出h(t-1)和当前时刻节点的输入Xt来决定当前时刻节点的输出。比如当前时刻节点状态为被污染,那么“天空的颜色”后面的单词应该是“灰色”。
在TensorFlow中可以使用lstm = rnn_cell.BasicLSTMCell(lstm_hidden_size)来声明一个LSTM结构。
GRU:

GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
梯度消失、爆炸解决
RNN关于Gradient Vanish,本秩原因是因为矩阵高次幂导致的。在RNN的训练z中,更新参数的方式是BPTT(Back Propagation Through Time)。其计算梯度的方式和DNN中的BP类似,所以会存在Gradient Vanish和Gradient Explode。
下面介绍LSTM如何能够避免Gradient Vanish:
对于LSTM,有如下公式:
模仿 RNN,我们对 LSTM 计算,有
可以看出当时,就算其余项很小,梯度仍然可以很好地传导到上一个时刻,此时即使层数较深也不会发生 Gradient Vanish 的问题;当
时,即上一时刻的信号不影响到当前时刻,则此项也会为0;
在这里控制着梯度传导到上一时刻的衰减程度,与它 Forget Gate 的功能一致。
对于 Gradient Explode,一般处理方法就是将梯度限制在一定范围内,即 Gradient Clipping。可以是通过阈值,也可以做动态的放缩.
Text-RNN
论文:Recurrent Neural Network for Text Classification with Multi-Task Learning 利用CNN进行文本分类,说到底还是利用卷积核寻找n-gram特征。卷积核的大小是超参。而RNN基本是处理文本信息的标配了,因为RNN先天就是为处理时间序列而设计的,它通过前后时刻的输出链接保证了“记忆”的留存。但RNN循环机制过于简单,前后时刻的链接采用了最简单的f=activate(ws+b) f=activate(ws+b)f=activate(ws+b)的形式,这样在梯度反向传播时出现了时间上的连乘操作,从而导致了梯度消失和梯度爆炸的问题。RNN的 变种LSTM/GRU在一定程度上减缓了梯度消失和梯度爆炸问题,因此现在使用的其实要比RNN更多。
利用RNN做文本分类也比较好理解。对于英文,都是基于词的。对于中文,首先要确定是基于字的还是基于词的。如果是基于词,要先对句子进行分词。之后,每个字/词对应RNN的一个时刻,隐层输出作为下一时刻的输入。最后时刻的隐层输出h_ThTcatch住整个句子的抽象特征,再接一个softmax进行分类。
RCNN
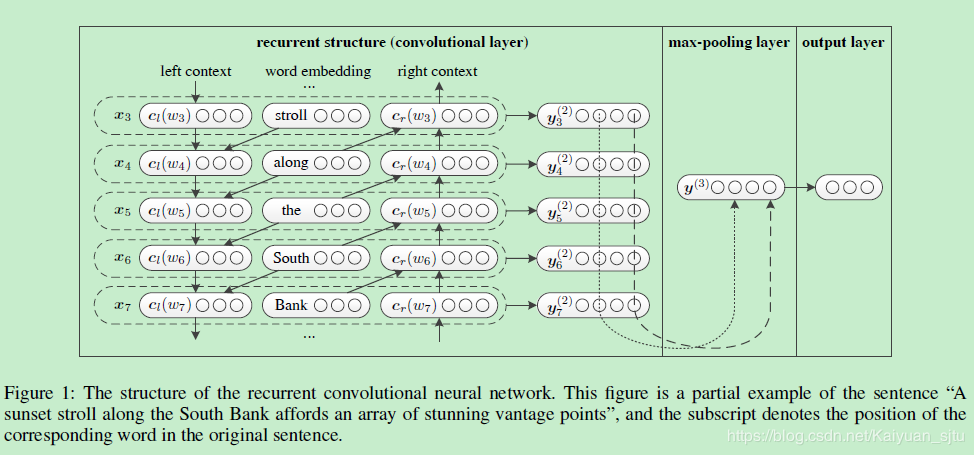
参考:https://blog.csdn.net/yanyiting666/article/details/88620434
https://blog.csdn.net/hongyesuifeng/article/details/90552778
Task8.循环和递归神经网络的更多相关文章
- 递归神经网络之理解长短期记忆网络(LSTM NetWorks)(转载)
递归神经网络 人类并不是每时每刻都从头开始思考.正如你阅读这篇文章的时候,你是在理解前面词语的基础上来理解每个词.你不会丢弃所有已知的信息而从头开始思考.你的思想具有持续性. 传统的神经网络不能做到这 ...
- lecture7-序列模型及递归神经网络RNN
Hinton 第七课 .这里先说下RNN有recurrent neural network 和 recursive neural network两种,是不一样的,前者指的是一种人工神经网络,后者指的是 ...
- lecture7-序列模型及递归神经网络RNN(转载)
Hinton 第七课 .这里先说下RNN有recurrent neural network 和 recursive neural network两种,是不一样的,前者指的是一种人工神经网络,后者指的是 ...
- 学习笔记CB010:递归神经网络、LSTM、自动抓取字幕
递归神经网络可存储记忆神经网络,LSTM是其中一种,在NLP领域应用效果不错. 递归神经网络(RNN),时间递归神经网络(recurrent neural network),结构递归神经网络(recu ...
- 递归神经网络(Recursive Neural Network, RNN)
信息往往还存在着诸如树结构.图结构等更复杂的结构.这就需要用到递归神经网络 (Recursive Neural Network, RNN),巧合的是递归神经网络的缩写和循环神经网络一样,也是RNN,递 ...
- 递归神经网络——就是解决AST这样的问题
原文:https://zybuluo.com/hanbingtao/note/626300 有时候把句子看做是词的序列是不够的,比如下面这句话『两个外语学院的学生』: 上图显示了这句话的两个不同的语法 ...
- TensorFlow(十一):递归神经网络(RNN与LSTM)
RNN RNN(Recurrent Neural Networks,循环神经网络)不仅会学习当前时刻的信息,也会依赖之前的序列信息.由于其特殊的网络模型结构解决了信息保存的问题.所以RNN对处理时间序 ...
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- Atitit 循环(loop), 递归(recursion), 遍历(traversal), 迭代(iterate).
Atitit 循环(loop), 递归(recursion), 遍历(traversal), 迭代(iterate). 1.1. 循环算是最基础的概念, 凡是重复执行一段代码, 都可以称之为循环. ...
随机推荐
- commons-collections包中的常用的工具类
commons-collections包中的常用的工具类 <dependency> <groupId>commons-collections</groupId> & ...
- import * as 用法
- 函数介绍——MulDiv
http://blog.sina.com.cn/s/blog_579ebc11010008ql.html 函数介绍——MulDiv (2007-03-27 10:05:30) 转载▼ 分类: 编程 ...
- js中parseInt()与parseFloat(),Number(),Boolean(),String()转换
js将字符串转数值的方法主要有三种 转换函数.强制类型转换.利用js变量弱类型转换. 1. 转换函数: js提供了parseInt()和parseFloat()两个转换函数.前者把值转换成整数,后者把 ...
- fiddler之简单的接口性能测试
在针对某一个/某一些接口,发送相同的请求,不考虑参数的变化时,可以使用fiddler进行简单的性能测试.(使用功能为:replay) 一.replay功能调用 (1.Reissue Requests: ...
- 简述Vue中的计算属性
1.什么是计算属性 如果模板中的表达式存在过多的逻辑,那么模板会变得臃肿不堪,维护起来也异常困难,因此为了简化逻辑出现了计算属性: <template> <div id=" ...
- python 入门学习之anaconda篇
还没下载的同学先点击这里进入anaconda官方网站进行下载. 然后点击安装,注意的是这里 安装好了之后呢,我们就开始进行Conda的环境管理,Conda的环境管理功能允许我们同时安装 若干不同版本的 ...
- mybatis工作流程&源码详解
该篇主要讲解的是mybatis从seesion创建到执行sql语句的流程 流程主线: 1.创建SqlSessionFactoryBuilder 2.创建会话工厂SqlSessionFactory 3. ...
- Excel VBA批量处理寸照名字(类模块加FSO版)
需求:因为处理学生学籍照片,从照相馆拿回来的寸照是按班级整理好,文件名是相机编号的文件.那么处理的话,是这么一个思路,通过Excel表格打印出各班A4照片列表,让学生自行填上照片对应姓名.表格收回来后 ...
- Jquery中$(function(){})
1. 在哪书写js文件 如果我们要执行一段js代码,我们该怎么办呢? 1.我们可以写一个js文件,在js文件里写执行函数,然后再<script src='...'> ... </sc ...