SQL的积累
SQL的积累学习(不常用的经常会忘记,所以以后用到的就会记在下面):
--新增字段
alter table t_Student add Test varchar(200)
--删除字段
alter table t_Student drop COLUMN Test
--修改字段类型
alter TABLE t_Student alter column Test VARCHAR(100)
--修改字段名称
exec sp_rename 't_student_2019._Test','!_Test' --exec sp_rename '表名.列名','新列名'
--修改表名
exec sp_rename 't_Student','t_student_2019'
--删除主键约束
alter table t_student_2019 drop constraint [PK__t_Studen__3214EC07267ABA7A]
--新增主键约束
alter TABLE t_student_2019 add CONSTRAINT [PK_T_Student_Id_Name] primary key(Id,Name)
--删除外键约束
alter table t_student_2019 drop constraint [FK__t_Student__TId__286302EC]
--新增外键约束
alter table t_student_2019 add constraint [FK_T_Student_2019_TId] foreign key (TId) references t_test(Id)
--新增唯一约束
alter table t_student_2019 add constraint [UN_T_student] unique([Id],[Name])
--给字段加注释
exec sp_addextendedproperty 'MS_Description','huageTest','SCHEMA','dbo','table','t_student_2019','column','Name'
--系统表
select * from sys.objects where type='U' --所有用户表
select * from sys.syscolumns where id=613577224 --所有字段
select * from sys.extended_properties where major_id= OBJECT_ID('t_student_2019') --字段描述
--字段加描述
select a.name,b.value from syscolumns a left join sys.extended_properties b on a.colid=b.minor_id where a.id=OBJECT_ID('t_student_2019')
--字段加字段类型长度描述
select a.name,type=c.name,a.length,b.value from syscolumns a left join sys.extended_properties b on a.colid=b.minor_id
left join sys.systypes c on a.xtype=c.xtype
where a.id=OBJECT_ID('t_student_2019') and c.status=0 order by a.colid
--创建数据库 create DataBase 数据库名称
--清空数据库 exec sp_MSForeachTable 'truncate table ?'
--创建表 create table 表名(column1 type1,column2 type2)
--复制表 select * into 新表名 from 旧表名
--删除表 drop table 表名
--删除表记录 delete from 表名
--重置表(清空记录并且不影响自增列)truncate table 表名
--计算两个日期时间 DATEDIFF(datepart, startdate, enddate)
--日期加时间 dateadd(datatype,num,date) 如 DATEADD(yyyy,3,rxrq)
--GUID select newid();--36位带四位‘-’符号;SQL Server 2005以上提供一种可以设置默认值约束的另一种方式 newsequentialid() 如 create table test(GUID uniqueidentifier default(newsequentialid()) primary key not null , Name nvarchar(10))
newid()还以设置随机取表中的数据 如 select top 100 * from tableName order by newid() (实现方式给所有数据新增一列guid,然后排序再取数据,性能不高)例如随机取10%的数据
select top 10 percent * from Table order by NEWID()
--order by a desc ,b (asc),c desc 先进行a的倒序,之后再进行b的升序,最后在执行c的降序
--Partition by可以理解为 对多行数据分组后排序取每个产品的第一行数据 相比于分组之后去最大最小的id来筛选记录,partition by 更简便
select * ,t=row_number() over(partition by '分组名称' order by '升降序字段' asc/desc) from #tmp
--for xml path('') --用于将表里的多条记录转换成xml格式输出
select * from #tnp for xml path('Huge')--> <Huge><列名1>值1</列名1><列名2>值2</列名2></Huge> <Huge><列名1>值1</列名1><列名2>值2</列名2></Huge> <Huge><列名1>值1</列名1><列名2>值2</列名2></Huge>这个样的XML,多行就会有多个。
最实用的例子还是 select 列+'、' from table for xml path('') =》值1、值2、值3、 最后可以去除最后一个字符即可
--数据库锁 悲观锁(就是悲观的认为是自己造成的并发) 乐观锁(乐观的为表创建一个版本号或者时间戳,这样每一次的新增/更新,导致版本号和时间戳都会变动,作为条件带到操作语句中)
悲观锁的一种用法
begin tran --开启一个事务
select top 10 * from #tmp WITH (UPDLOCK, ROWLOCK) where id=123--给这个表加一个行级锁
waitfor delay '00:00:30' --等待30秒(相当于C#中的线程sleep方法)
COMMIT tran--提交事务 --这时候新建一个Sql窗口,去修改这边记录数
update #tmp set sj=getdate() where id=123
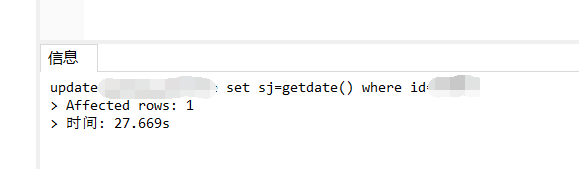
效果就是这样,必须等待事务提交,才可以进行数据的修改
--系统表 sys.dm_tran_locks (查看数据库资源锁)
begin tran
select top 100 * from #TMP with(UPDLOCK,RowLock) where A=2019
select * from sys.dm_tran_locks where resource_type = 'OBJECT'
--waitfor delay '00:00:20'
COMMIT tran
上述既可看到你当前查询的锁,可以通过 kill [request_session_id] 查询出来的这个id进行kill 这个锁
--SQL中取出decimal类型中对于的0
在sql server 建个函数ClearZero,使用这个函数去掉小数点后面多余的零。
CREATE function [dbo].[ClearZero](@inValue varchar(50))
returns varchar(50)
as
begin
declare @returnValue varchar(20)
if(@inValue='')
set @returnValue='' --空的时候为空
else if (charindex('.',@inValue) ='')
set @returnValue=@inValue --针对不含小数点的
else if ( substring(reverse(@inValue),patindex('%[^0]%',reverse(@inValue)),1)='.')
set @returnValue =left(@inValue,len(@inValue)-patindex('%[^0]%',reverse(@inValue))) --针对小数点后全是0的
else
set @returnValue =left(@inValue,len(@inValue)- patindex('%[^0]%.%',reverse(@inValue))+1) --其他任何情形
return @returnValue
end
在c#中呢? decimal d = 0.0500m; d.ToString("0.##")就出来了 也可以这样 string.Format("{0:0.##}",d000)
--SQL Server 2008 r2 常用函数整理
select ltrim(rtrim(' h u a g e ')) --去首尾空格 C#对应 Trim()函数
select REPLACE(' h u a g e ',' ','') --去所有的空格 C#对应Replace(" ", "")函数
select charindex(',',' as ,') --查找字符串目标字符(串)出现的第一个index(常常与截取字符串连用) C#对应 IndexOf(" ")函数
select SUBSTRING(', huages ,',1,3) --截取字符串(截取的位置开始到结束..数据库中的位数是从1开始的,不是0) C#对应Substring(1) --这边是从0开始
select right(left('huage',3),1) --取字符串左边3位再取右边一位 C#无对应函数 可以使用截取字符串
select reverse('huage') --字符串反转 C#无对应函数,可以使用 string.Join("",hua.ToCharArray().Reverse());
select len('huage') --字符串长度 C#对应Length()函数
select patindex('%[0]%','100');
select patindex('%[^0]%','0100') --'%[0]%'表示匹配第一个0的位置,'%[^0]%'匹配不是0的第一个位置 C#无对应函数
STUFF ( character_expression , start , length ,character_expression ) --字符串中,开始的,长度,删除后,新增另一个字符串 C#无对应函数
--SQL server2008以上版本:存储过程将表当做变量
--创建自定义的表类型
Create type XTableType as table(Id int,Name nvarchar(10))--自定类型(表)
--创建存储过程
Create Procedure [dbo].[pro_getname](@tmp XTableType readonly,@name varchar(10))
as
BEGIN
SELECT * FROM @tmp where Name=@name ;
END --调用存储过程
declare @tt as XTableType
insert into @tt(Id,Name) select 1,'zhangsan' union select 2,'lisi' union select 3,'wangwu'
exec pro_getname @tmp=@tt,@name=N'zhangsan'
--SQL Server函数返回 表数据
Create Function fnGetSplitTable
(@SourceSql NVARCHAR(MAX))
RETURNS @temp TABLE ( F1 VARCHAR(100) )
AS
BEGIN
DECLARE @ch AS VARCHAR(100)
WHILE ( CHARINDEX(',',@SourceSql)>0 )
BEGIN
SET @ch = substring(@SourceSql,1,CHARINDEX(',',@SourceSql)-1) -- SUBSTRING(@name,1,CHARINDEX(',',@name)-1)
INSERT @temp
VALUES ( @ch )
SET @SourceSql = substring(@SourceSql,CHARINDEX(',',@SourceSql)+1,100)
END
INSERT @temp
VALUES ( @SourceSql )
RETURN
END
--执行动态SQL语句
create table #tt(
id int,
name nvarchar(10)
)
insert into #tt select '1','zhangsan' union select '2','lisi' declare @name nvarchar(10)='zhangsan'
declare @sql nvarchar(max)='' set @sql='select * from #tt where name='''+@name+''' '
exec(@sql) --相当于执行拼接好的SQL语句,容易SQL注入 set @sql='select * from #tt where name=@name '
exec sp_executesql @sql,N'@name nvarchar(10)',@name=@name --参数化查询
--SQL Sever 触发器
--经常忘记触发判断是更新还是新增,所以记录一下
--基础语法
CREATE TRIGGER trigger_name
ON table_name
[WITH ENCRYPTION]
FOR | AFTER | INSTEAD OF [DELETE, INSERT, UPDATE]
AS
T-SQL语句
GO
--with encryption 表示加密触发器定义的sql文本
--delete,insert,update指定触发器的类型 --实例
Create TRIGGER [dbo].[tr_name]
ON [dbo].[tablename]
AFTER insert,update
AS
BEGIN
IF EXISTS(SELECT 1 FROM inserted) AND NOT EXISTS(SELECT 1 FROM deleted)--//新增 if Exists (select 1 from inserted) and Exists(select 1 from deleted)--//修改 if not Exists (select 1 from inserted) and Exists(select 1 from deleted)--//删除 select id from inserted
END
--行专列PIVOT,列转行UNPIOT的用法
select * into #tmp from (
select name='张三',cj=85,km='语文'
union
select '张三',85,'数学'
union
select '张三',90,'英语'
union
select '李四',90,'语文'
union
select '李四',90,'数学'
union
select '李四',85,'英语'
) tt select * from #tmp --select * from tt
declare @km varchar(50)
select @km=(select km+',' from #tmp GROUP BY km for xml path(''))
select @km=left(@km,len(@km)-1) exec(' select * from hua unpivot ( cj for km in ('+@km+') ) #unpiv') exec(' select * into hua from( select * from #tmp PIVOT (
max(cj)
for km in ('+@km+')
) as #PIV) tt select * from hua') exec(' select * from #tmp PIVOT (
max(cj)
for km in ('+@km+')
) as #PIV') select * from hua unpivot ( cj for km in (数学,英语,语文) ) #unpiv order by name,km,cj exec(' select * from hua unpivot ( cj for km in ('+@km+') ) #unpiv')
SQL的积累的更多相关文章
- sql 的积累
sql的积累 By:山高似水深 原创 转载注明出处 .REVERSE() 反转 例如: Hive 可用 2016年12月3日11:31:59 2.instr(str,'.')位置 结果:得出在str中 ...
- SQL常见问题积累
SQL积累--仅适用于SQL Server 1.sql中,字符串保存序号,按照数字顺序进行排序 ))),) asc --householdNo 为要排序字段 2.控制小数位数 ,),,)))+'%' ...
- SQL Server 积累
2016-11-24 sql语句修改某表某字段的数据类型和字段长度: 问题是在修改老功能中暴露出来的,我修改了图片上传功能,结果报图片路径超出数据库字段规定长度,我检查数据库后发现之前设计数据库的人将 ...
- sql语句积累
有一个需求表(demand),每一记录就是一条需求:另外有一个报价表(quotation),每一条记录是对需求记录的报价详情. 需求表: 报价表: 我现在想得到每条需求的信息以及有多少人报价了,我们可 ...
- SQL面试积累
以下题目都在MySQL上测试可行,有疏漏或有更优化的解决方法的话欢迎大家提出,我会持续更新的:) 有三个表,如果学生缺考,那么在成绩表中就不存在这个学生的这门课程成绩的记录,写一段SQL语句,检索出每 ...
- 有用的sql语句积累
⑴. sql查询未被外键关联的数据 select * from bb b where not exists (select 1 from aa a where a.bid=b.bid)
- PHP SQL写法 积累(注:PHPSQL与LINQ SQL相似)
1: $data ['parentid'] = $pid; M('menu')->where($data)->order(' id asc ')-> select(); // ...
- sql 整理积累
) AS t1 LEFT JOIN (SELECT * FROM dbo.xcqy2017_News_Classification) AS t2 ON t2.Ncid = t1.Ncid left j ...
- Oracle SQL语句积累
字段合并: select EVFOUNDATIONTYPEA || EVFOUNDATIONTYPEB|| EVFOUNDATIONTYPEC ||EVFOUNDATIONTYPED as b fro ...
随机推荐
- Tarjan水题系列(5):最大半连通子图 [ZJOI2007 luogu P2272]
题目 大意: 缩点后转为求最长链的长度和最长链的个数 思路: 看懂题就会做系列 长度和个数都可以拓扑排序后DP求得 毕竟是2007年的题 代码: 如下 #include <cstdio> ...
- centos7下安装composer和git
一.安装composer composer 属于php的包依赖管理工具. 1.进入Composer国内镜像网站文档页查看安装方法: https://docs.phpcomposer.com/00-in ...
- Ubuntu16.04.1安装Caffe(GPU)
Caffe的优势: 1.上手快:模型与相应优化均以文本形式而非代码形式给出,caffe给出了模型的定义,最优化设置以及预训练的权重 2.速度快:与CuDNN结合使用,测试AlexNet模型,在K40上 ...
- laravel5.8 eloquent
https://learnku.com/docs/laravel/5.8/eloquent/3931 示例1: $flights = App\Flight::all(); foreach ($flig ...
- FMCJ450-基于ADRV9009的射频收发模块
FMCJ450-基于ADRV9009的射频收发模块 一.板卡概述 接收路径包括两个具有动态范围的独立式宽带宽直接转换接收器.该器件还支持宽带宽分时观察路径接收器,供在 TDD 应用中使用.完整的接收子 ...
- mydql 设置充许远程链接
1 本机作为服务器时,其他机器连接不上? 1)看一下防火墙是否打开了. 2)在cmd中设置权限. 第一种:(进入数据库的情况下) 1.d:\mysql\bin\>mysql -h localho ...
- sftp接口机上传脚本
sftp只要有秘钥,就不需要输入密码. #!/bin/bash #上传现在时间的前一小时的文件 date=`date -d -1hour +%Y%m%d` hour=`date -d -1hour + ...
- 中文转换为ASCII码的方式
可以到jdk安装路径: 找到native2ascii.exe文件 双击运行,敲入中文即可获取对应的ASCII编码
- 使用@ConditionalOnProperty注解
Spring boot中的注解@ConditionalOnProperty,可以通过配置文件中的属性值来判定configuration是否被注入, @Retention(RetentionPolicy ...
- Docker MongoDB 部署
docker search mongo 命令来查看可用版本: $ docker search mongo NAME DESCRIPTION STARS OFFICIAL AUTOMATED mongo ...