note: Spanner: Google’s Globally-Distributed Database
1. Abstract & introduction
ref:http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/spanner-osdi2012.pdf
Spanner是google为了弥补bigtable的不足而推出的新一代的数据库系统。首先,看看bigtable有哪些不足。
看这篇文章前应该看看bigtable的文章http://www.cnblogs.com/zwCHAN/p/3698191.html
- 只支持row级别的事物,不支持跨行事物,更别提跨表和跨库,乃至跨数据中心的事务性;
- 很好地依赖GFS天然支持解决了其他数据库通过复杂的replication才能解决的容错、读写分离的并发性问题,但是在跨数据库的容灾问题上,GFS没有提出有效的解决方案,bigtable当然也不支持;
- 它有k-v模型在海量数据的优势,同时也有该模型的劣势:相比支持sql的关系数据库,极为有限的查询功能;
另外,对于Gmail、Calendar、Android market、AppEngine这几个我平时用的应用时在Megastore上运行的表示极为惊讶。。
所以,Spanner的设计目标是集传统关系数据库和k-v模型数据库的优势于一体,支持可扩展、多版本、全球分布式、全局同步复制的半关系话数据库。为了支持这些特性,它提出了TrueTime的概念,使用了paxos同步算法、只读事务无锁化处理等方法;设计了一套类似Megastore的sql语言;为了支持全球范围的分布式数据库(同步复制)功能,spanner有几个功能很有启发性,
- 由应用负责细化数据复制和分布的策略。这一点传统数据库如mysql都是对外透明的;这显然是鱼和熊掌不能兼得的表现:全球范围内理论延时都有超过100ms,即使g神也无法超越光速。所以让应用根据自己需要做出权衡;应用可以控制数据做几个备份(不同数据中心的备份,在一个数据中心是由GFS复杂冗余备份的,后面说到备份<replica>同),以及在哪些数据中心放置这些备份;而spanner负责在这些指定的数据中心之间做数据的replica。
- spanner支持居于时间戳的读写的全局一致性。这是一件非常困难的事情。。
2 Implementation:
2.1 spanner的逻辑结构:
- 最外层,universe,这是整个数据库架构上的最大集合,从这个名字就能看出gger有多狂妄。。
- universemaster除了名字同样很华丽外只做些监控调试的功能;
- placement driver;placement driver这样低调名字的才是真中干大事的:负责自动跨zone的数据复制;
- zone:到了zone级别后,就基本相当于一个bigtable系统了。
- zonemaster
- location proxy
- spanner server

- directory :另外,提出了一个扩展了bigtable中locality group概念的directory,他是数据复制、管理、移动的基本单位,另外关于directory的一个重要变化是:在directory内,key是全局唯一的且俺字典序排序的;但在不同的directory是由重叠的。这点与bigtable不同。
2.2 软件架构
- 数据模型:
- (key:string, timestamp:int64) –> string, 这里没有画出column,但是他们肯定也是存在的;最大的不同是,timestamp是包含在数据里面的,这就类似mysql中的多版本并行控制策略了(MVCC,Multi-Version Concurrency Control)。这明显是改正了bigtable设计中莫名其妙把timestamp放到外面的方案;
- spanner需要每行数据中指定某些列作为主键,其他部分相当于这个key对应的value。所以它看起来也像k-v模型的。
- paper中提供了两个软件结构的视图,

- 我把这两个图整合起来理解可能更好一点,各个模块的功能:
- paxos: 每个tablet都有一个对应的paxos状态机,它存储着对应tablet在各个zone内replica的状态,确保他们之间一致性;通过这些状态信息,可以判断对应的replica是否足够新(suffieciently up-to-date), 以满足基于时间戳的读操作。
- paxos group:一个directory的所有replica的paxos合在一起就形成了一个paxos group,他们其中的一个会被推选为这个paxos group的leader;
- lock table:每个leader都有locktable记录着replicas的哪些key值正在被同步操作占用。
- leader: 每一份directory数据会有多个replica,不同的replica分布在不同的zone内,其中的一个replica所在的tablet的paxos会被推选为leader,负责各个replica之间的同步工作;
- transaction manager:每个spanner server都有一个transaction server服务,负责参协调与不同directory数据之间的事物关系;
- participant leader/slave:paxos所在的replica对应的participant自然成为participant leader, 其他未particicant slave;当只有一个paxos组参与事务时,通过lock table和paxos的同步功能,就能实现事务性:原子性、一致性、独立性、持久性(ACID)。
- coordinator: 当有多个paxos paxosgroup参与事务时,paxos group之间就要进行2PC(two phase commit)操作。2PC要求要有一个协调者,所以就出现了coordinator的概念。 它与leader不同点在于,leader是一个paxos group内部的leader,存在leader是因为paxos一致性算法需要一个leader; 而coordinator是paxos group之间的“leader”,存在的原因是2PC算法需要一位协调者(它不叫leader,但其实是一个意思)。至于coordinator leader/slave,是指被选举coordinator的paxos group内部的区分,没特别的含义。
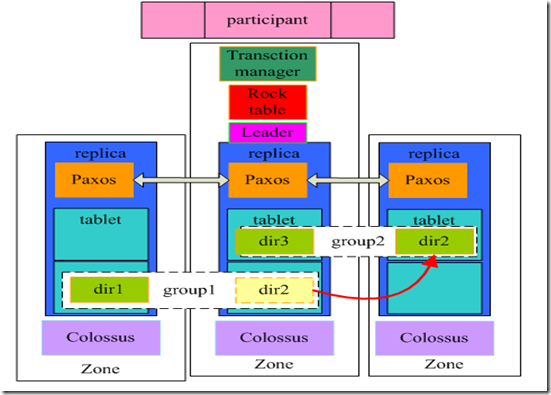
- movedir是一个负责directory移动的事务。 由于一个paxos拥有多个directory,所以同一时间只能有一个directory可以占用这个paxos状态机。为了减少冲突的概率,movdir通过分两次移动数据的方式实现:第一次移动时并不占用paxos,且不会影响任何读写操作(可以理解为先拷贝到缓冲区);第二次移动时占用paxos,但是只需要移动第一次移动开始的时间点到获取到paxos状态锁的时间段内的增量数据;

3. TrueTime
truetime的概念在spanner中非常重要,但却没有说怎么实现的。说在另一篇论文说明,但没找到。truetime的api:

TT.now()这样的接口在平时的api中会返回一个确切的时间,但这里返回的是一个时间范围,它表示,调用TT.now的真实时间,肯定在返回值得时间范围内。其实这也很好理解,因为如果在一台机器上,要确定一个时间是很简单的,获取当前时钟就可以了;但是如果想在同一绝对时间内(绝对时间是指不依赖于计算机时钟系统的客观时间)在所以机器上调用TT.now,都要得到一个相同的返回值,这就要求所以机器的时钟系统是完全一致的。这其实是不可能做到的事情(参见http://www.cnblogs.com/zwCHAN/p/3652948.html),假设所有机器的时间差(最慢的时钟减去最快的时钟的差为e,那么在任何一台机器上调用TT.now,都可以确定此时的真实时间范围是(-e+TT.now, e+TT.now). 如下图,完美的钟指示着绝对时间,而在绝对时间的9:00:00后每隔10s,同时在三台server上调用获取now时间,他们得到的值不同,误差为7s。所以当一个人不知道绝对时间,但直到这个误差为7s,在server1上调用now,得到9:00:08这个时间点,他就可以肯定当前真实时间在(9:00:01,9:00:15)之间(时钟频率的偏差都在10**-6以下,可忽略)。
而事实上,获取误差e的准确值也是不可能(和时钟同步一个道理),只能确定某个e’,且e’>=e, 这样,我们就相当于取个“安全值”。例如这个例子中取个10s误差,那肯定也是正确的。同时也说明,server之间的误差越小,我们能得到的e’也就越小。

paper中说谷歌使用的是GPS时钟同步,可以使e降低为10ms以内;而他们的目标是1ms。。。 truetime的误差对系统的影响也是赤裸裸的:在这个误差范围内,只能有一个事务执行。
4. Concurrency control
在spanner系统中,只有读写事务操作使用了悲观锁机制,其他操作都是无锁的。spanner依赖于分配给各个事务的时间戳的单调递增性,也就是需要确保事务的有序性。
对于读写事务操作,站在软件架构最高位置的coordinator leader再给一个写事务分配时间戳Si时,确保Si不小于TT.now().latest,也就是这个时间戳肯定在其他所有参与事务的机器上的事务的时间戳都大,当每个事务都这样操作时,就能确保时间戳是单调递增的(当然,为了满足这个条件,coordinator可能要等待。
分析一个完整的读写事务的过程:client的一个事务要求要读取group1、group2、group3的值后更新。图中的数字标识步骤。了解了最复杂的读写事务,其他事务就很容易了。

- client通知leader replica获取读锁read-lock;
- client read last-update data on a replica;
- client write all to the buffer
- client选择一个coordinator group, 然后开始发起一个2PC提交写的内容;
- client将选择到的coordinator标识+buffer write 发送给所有的paticipant leader;(从而避免发给coordiantor,然后coordinator再发给participant,在这点上对事务成功是乐观的);
- 每个non-coordinator-participant leader(也就是不是coordinator的paxos group的leader)都在本组内获取wirte-lock,然后选取一个比本组内所有之前提出的事务时间戳都大的时间戳,再写入一个prepare paxos log;
- 然后non-coordinator-participant leader将选出的时间戳发给coordinator。(至此2PC的Prepare阶段完成)
- coordnator自己也在本地获取write-lock,(显然它不用做prepare阶段的事了,client帮它发了)。然后coordinator等待所有的participant learder发过来的时间戳(第7步),选取一个最大值Pmax;
- coordinator获取TT.now(),并比较TT.now().latest与Pmax。如果TT.now().laster>=Pmax(标识此时TT.now()为s), 继续往下执行; 否则重复第9步。(这步取保了事务时间戳的单调递增);
- coordinator commit一个log到paxos状态机(标识commit事务);
- 由于coordinator 提交了commit到paxos状态机,其他的participant就知道事务已经提交了(但不知道coordnator选择的提交的时间戳等详情)。但其他需要同步的Replica还不能马上得到数据,coordinator需要等到after( s)之后才允许同步。这是为了等待前面提到的2倍误差时间过去,确保这个时间戳(时间段)真的过去了(目前为止,所有锁都没释放),然后coordinator开始通知所有的participant和client事务提交的时间戳与事务结果状态;
- 每个participant将事务的结果状态提交到自己的paxos group中;
- 所有的参与者在得到事务的结果状态和时间戳后,释放锁资源;
5.Evaluation

上图表明,随着replicas的增加,snapshot效率是线性增长的(lock-free),事务写吞吐量会降低,延时变化不大(获取锁效率高)。

上图是2PC的可扩展性性能指标。在50个节点左右,性能恶化不明显。大于100后恶化明显;

上图是google使用GPS时钟同步后,能做到的时钟误差e,基本都在10ms以内;所以它的写事务延时在10ms+;

上图是spanner实际应用中24h平局延时和偏差。(跨美国东西海岸)。可见结果也不容乐观。
note: Spanner: Google’s Globally-Distributed Database的更多相关文章
- Spanner: Google’s Globally-Distributed Database
https://research.google.com/archive/spanner.html Spanner is Google’s scalable, multi-version, global ...
- 《Spanner: Google’s Globally-Distributed Database》论文总结
Spanner 总结 说明:本文为论文 <Spanner: Google's Globally-Distributed Database> 的个人理解,难免有理解不到位之处,欢迎交流与指正 ...
- 「2014-2-23」Note on Preliminary Introduction to Distributed System
今天读了几篇分布式相关的内容,记录一下.非经典论文,非系统化阅读,非严谨思考和总结.主要的着眼点在于分布式存储:好处是,跨越单台物理机器的计算和存储能力的限制,防止单点故障(single point ...
- Note on Preliminary Introduction to Distributed System
今天读了几篇分布式相关的内容,记录一下.非经典论文,非系统化阅读,非严谨思考和总结.主要的着眼点在于分布式存储:好处是,跨越单台物理机器的计算和存储能力的限制,防止单点故障(single point ...
- TiDB, Distributed Database
https://www.zhihu.com/topic/20062171/top-answers
- Ubiq:A Scalable and Fault-tolerant Log Processing Infrastructure
Abstract 互联网应用通常会产生大量的时间日志需要进行分析和处理.本文介绍Ubiq的架构,它是一个分布式系统,用于处理不断增长的日志文件,具有可扩展性.高可用.低延迟的特性.Ubiq框架容忍基础 ...
- Cosmos DB
类似的数据库还有Google的Spanner. 参考:官网说明 另一个介绍 Key capabilities As a globally distributed database service, A ...
- Distributed PostgreSQL on a Google Spanner Architecture – Storage Layer
转自:https://blog.yugabyte.com/distributed-postgresql-on-a-google-spanner-architecture-storage-layer/ ...
- Distributed PostgreSQL on a Google Spanner Architecture – Query Layer
转自:https://blog.yugabyte.com/distributed-postgresql-on-a-google-spanner-architecture-query-layer/ Ou ...
随机推荐
- luogu P4006 小 Y 和二叉树
luogu loj 可以发现度数\(< 3\)的点可以作为先序遍历的第一个点,那么就把度数\(< 3\)的编号最小的点作为第一个点.然后现在要确定它的左右儿子(或者是右儿子和父亲).我们把 ...
- 冒泡排序(java可直接跑,算法思想等小儿科不多说直接上代码)
import java.util.Arrays; /** *冒泡排序:时间复杂度O(N^2),空间复杂度O(1),稳定的排序 * 每趟确定一个元素的位置,所以需要arr.length趟排序, */pu ...
- 05 Django之模型层---单表操作
一 ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人 ...
- layer单选框 radio的问题总结
放官方文档: 位置 页面元素-表单:内置模块-表单属性title可自定义文本属性disabled开启禁用设置value="xxx"可自定义值,否则选中时返回的就是默认的onradi ...
- openstack Rocky系列之keystone:(二)keystone中API注册
主要说一下initialize_application中的application_factory def loadapp(): app = application.application_factor ...
- Mac OSX编译安装php7.1.8
laravel中用到ldap认证包,要求php7.0以上版本,而且安装Mews\Captcha包的时候 验证码无法显示 报错如下: Call to undefined function Interve ...
- 标准C语言(11)
多文件编程时一个文件里可以包含多个函数,一个函数只能属于一个文件 /* * 多文件编程演示 * */ #include <stdio.h> #include "01add.h&q ...
- string::empty
bool empty() const noexcept;注:判断string对象是否为空,为空返回true #include <iostream>#include <string&g ...
- maven地址配置为阿里maven仓库,附ali maven官方指南链接
一.参考链接 官方指南 链接地址:https://help.aliyun.com/document_detail/102512.html?spm=a2c40.aliyun_maven_repo.0.0 ...
- Automatches
import os def combine(ArrayList,count): ArrayList=list(ArrayList) newArrayList=[] for i in range(0,A ...