SnowFlake 雪花算法详解与实现 & MP中的应用
BackGround
现在的服务基本是分布式,微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性。
对于 MySQL 而言,一个表中的主键 id 一般使用自增的方式,但是如果进行水平分表之后,多个表中会生成重复的 id 值。那么如何保证水平分表后的多张表中的 id 是全局唯一性的呢?
如果还是借助数据库主键自增的形式,那么可以让不同表初始化一个不同的初始值,然后按指定的步长进行自增。例如有3张拆分表,初始主键值为1,2,3,自增步长为3。
当然也有人使用 UUID 来作为主键,但是 UUID 生成的是一个无序的字符串,对于 MySQL 推荐使用增长的数值类型值作为主键来说不适合。
也可以使用 Redis 的自增原子性来生成唯一 id,但是这种方式业内比较少用。
当然还有其他解决方案,不同互联网公司也有自己内部的实现方案。雪花算法是其中一个用于解决分布式 id 的高效方案,也是许多互联网公司在推荐使用的。
SnowFlake 雪花算法
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID。在2014年开源 scala 语言版本。
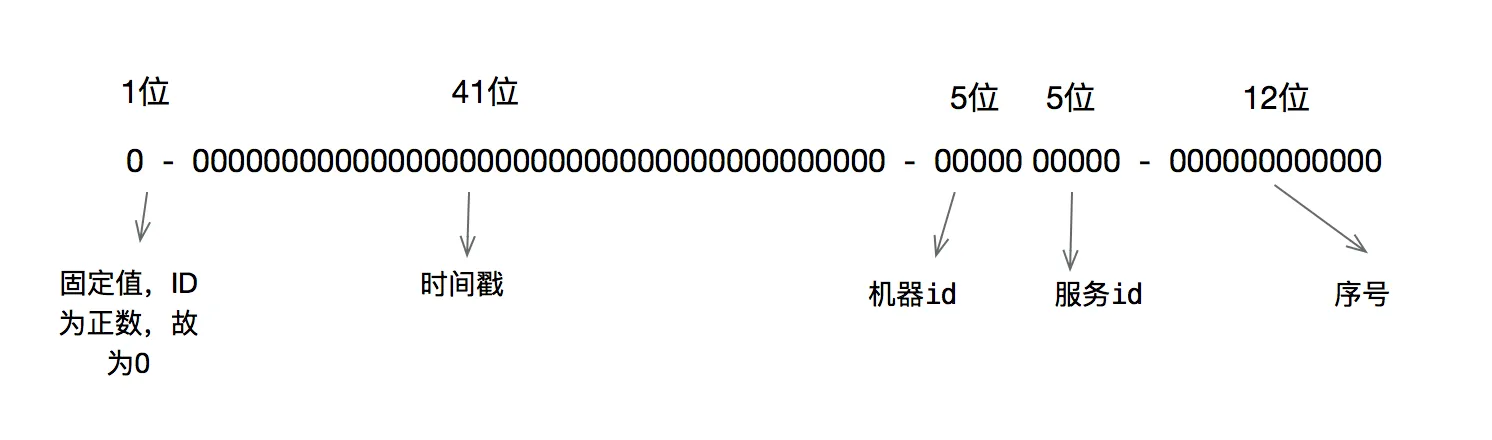
雪花算法原理就是生成一个的64位比特位的 long 类型的唯一 id。
- 最高1位固定值0,因为生成的 id 是正整数,如果是1就是负数了。
- 接下来41位存储毫秒级时间戳,2^41/(1000*60*60*24*365)=69,大概可以使用69年。
- 再接下10位存储机器码,包括5位 datacenterId 和5位 workerId。最多可以部署2^10=1024台机器。
- 最后12位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成2^12=4096个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定10位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的10位比特位的整数值都行。
package com.riotian.mplearn;
import java.util.Set;
import java.util.TreeSet;
public class SnowflakeIdGenerator {
// 初始时间戳(纪年),可用雪花算法服务上线时间戳的值
// 1649059688068:2022-04-04 16:08:08
private static final long INIT_EPOCH = 1649059688068L;
// 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断
private long lastTimeMillis = -1L;
// dataCenterId占用的位数
private static final long DATA_CENTER_ID_BITS = 5L;
// dataCenterId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
// datacenterId
private long datacenterId;
// workId占用的位数
private static final long WORKER_ID_BITS = 5L;
// workId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
// workId
private long workerId;
// 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095
private static final long SEQUENCE_BITS = 12L;
// 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095
// 0000000000000000000000000000000000000000000000000000111111111111
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);
// 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095
private long sequence;
// workId位需要左移的位数 12
private static final long WORK_ID_SHIFT = SEQUENCE_BITS;
// dataCenterId位需要左移的位数 12+5
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
// 时间戳需要左移的位数 12+5+5
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
public SnowflakeIdGenerator(long datacenterId, long workerId) {
// 检查datacenterId的合法值
if (datacenterId < 0 || datacenterId > MAX_DATA_CENTER_ID) {
throw new IllegalArgumentException(
String.format("datacenterId值必须大于0并且小于%d", MAX_DATA_CENTER_ID));
}
// 检查workId的合法值
if (workerId < 0 || workerId > MAX_WORKER_ID) {
throw new IllegalArgumentException(String.format("workId值必须大于0并且小于%d", MAX_WORKER_ID));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 通过雪花算法生成下一个id,注意这里使用synchronized同步
*
* @return 唯一id
*/
public synchronized long nextId() {
long currentTimeMillis = System.currentTimeMillis();
// 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题
if (currentTimeMillis < lastTimeMillis) {
throw new RuntimeException(
String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis,
lastTimeMillis));
}
if (currentTimeMillis == lastTimeMillis) { // 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095
// 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095
// 那么就使用新的时间戳
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
currentTimeMillis = tilNextMillis(lastTimeMillis);
}
} else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095
sequence = 0;
}
// 记录最后一次使用的毫秒时间戳
lastTimeMillis = currentTimeMillis;
// 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行
return ((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT) | (datacenterId
<< DATA_CENTER_ID_SHIFT) | (workerId << WORK_ID_SHIFT) | sequence;
}
/**
* 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒
*
* @param lastTimeMillis 指定毫秒时间戳
* @return 时间戳
*/
private long tilNextMillis(long lastTimeMillis) {
long currentTimeMillis = System.currentTimeMillis();
while (currentTimeMillis <= lastTimeMillis) {
currentTimeMillis = System.currentTimeMillis();
}
return currentTimeMillis;
}
public static void main(String[] args) {
SnowflakeIdGenerator snowflakeIdGenerator = new SnowflakeIdGenerator(1, 2);
// 生成50个id
Set<Long> set = new TreeSet<>();
for (int i = 0; i < 50; i++) {
set.add(snowflakeIdGenerator.nextId());
}
System.out.println(set.size());
System.out.println(set);
// 验证生成100万个id需要多久
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
snowflakeIdGenerator.nextId();
}
System.out.println(System.currentTimeMillis() - startTime);
}
}
在我的笔记本,测试结果如下,生成的50个id是不重复的,而且 id 值是递增的。然后再测试生成100万个 id,只花费了244毫秒,可见是算法是及其高效的。
50
[115701435689213952, 115701435689213953, 115701435689213954, 115701435689213955, 115701435689213956, 115701435689213957, 115701435689213958, 115701435689213959, 115701435689213960, 115701435689213961, 115701435689213962, 115701435689213963, 115701435689213964, 115701435689213965, 115701435689213966, 115701435689213967, 115701435689213968, 115701435689213969, 115701435697602560, 115701435697602561, 115701435701796864, 115701435701796865, 115701435701796866, 115701435701796867, 115701435701796868, 115701435701796869, 115701435701796870, 115701435701796871, 115701435701796872, 115701435701796873, 115701435701796874, 115701435701796875, 115701435701796876, 115701435701796877, 115701435701796878, 115701435701796879, 115701435701796880, 115701435701796881, 115701435701796882, 115701435701796883, 115701435701796884, 115701435701796885, 115701435701796886, 115701435701796887, 115701435701796888, 115701435701796889, 115701435701796890, 115701435701796891, 115701435701796892, 115701435701796893]
244
算法优缺点
雪花算法有以下几个优点:
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
雪花算法有如下缺点:
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
注意事项
其实雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到69年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024台,那么可将减少的位数补充给机器码用。
注意,雪花算法中41位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
在MP中,如何提前获取实体类用雪花算法生成的ID?
Mybatis-plus中,通过设置@TableId可以让Mybatis-plus自动为我们生成雪花算法的ID号,该ID号是一个长整型数据,非常方便。但是雪花算法的ID号是在Insert执行的时候生成的,我们在Insert执行前是不知道Entity会获得一个什么ID号。
但是在某些情况下,我们想提前获取这个ID,这样可以通过一些计算来生成其他字段的值。例如我们用此ID号做秘钥来加密密码。
这种情况下,需要提前生成ID号,手动设置给Entity。在实体类中,通过下面这个注解将自动ID改为有程序控制输入:
@TableId(type=IdType.INPUT)
那么我们需要用雪花算法生成一个ID号。是不是还需要另外自己写一个雪花算法生成类呢?
完全不用。因为 MP 中内置了雪花算法生成功能,我们找出来调用就行了,就是下面这个类:
import com.baomidou.mybatisplus.core.toolkit.IdWorker;
我们可以这样调用:
Long ID=IdWorker.getId(entity);
如果有更高的需求,还可以设置雪花算法的其他参数。
这个类源码如下:
/*
* Copyright (c) 2011-2020, baomidou (jobob@qq.com).
* <p>
* Licensed under the Apache License, Version 2.0 (the "License"); you may not
* use this file except in compliance with the License. You may obtain a copy of
* the License at
* <p>
* https://www.apache.org/licenses/LICENSE-2.0
* <p>
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations under
* the License.
*/
package com.baomidou.mybatisplus.core.toolkit;
import com.baomidou.mybatisplus.core.config.GlobalConfig;
import com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator;
import com.baomidou.mybatisplus.core.incrementer.IdentifierGenerator;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.UUID;
import java.util.concurrent.ThreadLocalRandom;
/**
* id 获取器
*
* @author hubin
* @since 2016-08-01
*/
public class IdWorker {
/**
* 主机和进程的机器码
*/
private static IdentifierGenerator IDENTIFIER_GENERATOR = new DefaultIdentifierGenerator();
/**
* 毫秒格式化时间
*/
public static final DateTimeFormatter MILLISECOND = DateTimeFormatter.ofPattern("yyyyMMddHHmmssSSS");
/**
* 获取唯一ID
*
* @return id
*/
public static long getId() {
return getId(new Object());
}
/**
* 获取唯一ID
*
* @return id
*/
public static long getId(Object entity) {
return IDENTIFIER_GENERATOR.nextId(entity).longValue();
}
/**
* 获取唯一ID
*
* @return id
*/
public static String getIdStr() {
return getIdStr(new Object());
}
/**
* 获取唯一ID
*
* @return id
*/
public static String getIdStr(Object entity) {
return IDENTIFIER_GENERATOR.nextId(entity).toString();
}
/**
* 格式化的毫秒时间
*/
public static String getMillisecond() {
return LocalDateTime.now().format(MILLISECOND);
}
/**
* 时间 ID = Time + ID
* <p>例如:可用于商品订单 ID</p>
*/
public static String getTimeId() {
return getMillisecond() + getIdStr();
}
/**
* 有参构造器
*
* @param workerId 工作机器 ID
* @param dataCenterId ***
* @see #setIdentifierGenerator(IdentifierGenerator)
*/
public static void initSequence(long workerId, long dataCenterId) {
IDENTIFIER_GENERATOR = new DefaultIdentifierGenerator(workerId, dataCenterId);
}
/**
* 自定义id 生成方式
*
* @param identifierGenerator id 生成器
* @see GlobalConfig#setIdentifierGenerator(IdentifierGenerator)
*/
public static void setIdentifierGenerator(IdentifierGenerator identifierGenerator) {
IDENTIFIER_GENERATOR = identifierGenerator;
}
/**
* 使用ThreadLocalRandom获取UUID获取更优的效果 去掉"-"
*/
public static String get32UUID() {
ThreadLocalRandom random = ThreadLocalRandom.current();
return new UUID(random.nextLong(), random.nextLong()).toString().replace(StringPool.DASH, StringPool.EMPTY);
}
}
SnowFlake 雪花算法详解与实现 & MP中的应用的更多相关文章
- 全局唯一iD的生成 雪花算法详解及其他用法
一.介绍 雪花算法的原始版本是scala版,用于生成分布式ID(纯数字,时间顺序),订单编号等. 自增ID:对于数据敏感场景不宜使用,且不适合于分布式场景.GUID:采用无意义字符串,数据量增大时造成 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- vcenter密码设置永不过期
由于机房断电,原本的vcenter重启后web页面出现报错,为尽快恢复vcenter管理机,直接停用了旧的vcenter虚机,重新安装了一台vcenter,两个月后,页面开始报警密码即将到期: 经查阅 ...
- winform datagridview行头添加序号
1.使用datagirdview的RowPostPaint事件 2.datagirdview命名为dgv.(当然这个名字随意,开心就好) 3.贴代码 private void dgv_RowPostP ...
- windows环境变量修改器
软件及源码 前言 我一直再用win7的系统,当更改path环境变量的时候很难受, 就只能看到一段,然后前面有啥后面有啥都看不到,而且来回调整优先级的时候需要剪切粘贴,主要就是来回调节优先级特别麻烦.所 ...
- 关于vlc"编解码器暂不支持: VLC 无法解码格式“MIDI” (MIDI Audio)"解决
解决办法 sudo apt install vlc-plugin-fluidsynth
- uni-ajax使用示例
官网 基于 Promise 的轻量级 uni-app 网络请求库 uni-ajax官网:https://uniajax.ponjs.com 安装 插件市场 在 插件市场 右上角选择 使用 HBuild ...
- 关于 risrqnis
这道题里最有用的( Range Insert Subset Range Query [n?] In Set 破案了 我那五个点是因为维护不知道有什么用的东西炸了 删了就过了 题面 [JRKSJ R4] ...
- JavaScript:操作符:空值合并运算符(??)
这是一个新增的运算符,它的功能是: 对于表达式1 ?? 表达式2,如果表达式1的结果是null或者undefined时,返回表达式b的结果:否则返回表达式a的结果: 它与赋值运算符结合使用,即??=, ...
- 比Sqoop功能更加强大开源数据同步工具DataX实战
@ 目录 概述 定义 与Sqoop对比 框架设计 支持插件 核心架构 核心优势 部署 基础环境 安装 从stream读取数据并打印到控制台 读取MySQL写入HDFS 读取HDFS写入MySQL 执行 ...
- 后疫情办公时代——你需要的多人同步协同编辑Demo(可粘贴可撤销)
新冠病毒的疫情使得在线办公成为了一个常态,这使得在线文档成为了时下的热点.其中在线协同表格是在线文档的重要一个组成部分,纯前端表格在在线协同表格上有着得天独厚的优势:本身已经实现了单人操作在线文档的基 ...
- 10、比较Bigdecimal类型是否相等的方法
一.Bigdecimal.equals()详解: Bigdecimal的equals方法不仅仅比较值的大小是否相等,首先比较的是scale(scale是bigdecimal的保留小数点位数),也就是说 ...