HIVE 数据分析
题目要求:


具体操作:
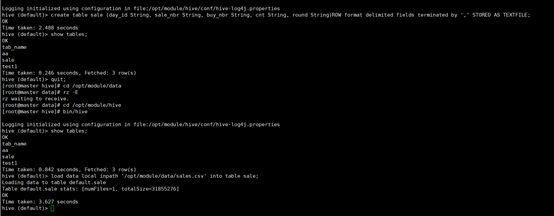
①hive路径下建表:sale
create table sale
(day_id String, sale_nbr String, buy_nbr String, cnt String, round String)
ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
②导入数据:
load data local inpath '/opt/module/data/sales.csv' into table sale;
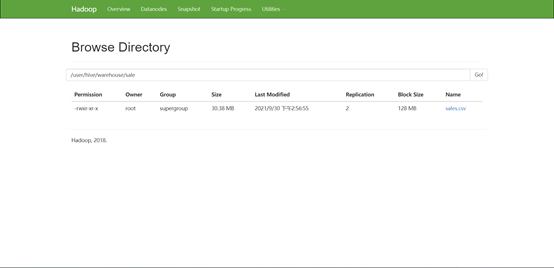
③数据清洗:
3、数据分析处理:
(1)统计每天各个机场的销售数量和销售金额。要求的输出字段 day_id,sale_nbr,,cnt,round 日期编号,卖出方代码,数量,金额。
命令:
查询语句:
select day_id,sale_nbr,sum(cnt),sum(round) from sale where sale_nbr like 'C%' group by day_id,sale_nbr;
创建表table1:
create table table1(day_id String,sale_nbr String, cnt String,round String) ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
将查询语句保存至table1:
insert overwrite table table1 select day_id,sale_nbr,sum(cnt),sum(round) from sale where sale_nbr like 'C%' group by day_id,sale_nbr;
(2)统计每天各个代理商的销售数量和销售金额.要求的输出字段 day_id,sale_nbr,cnt,round 日期编号,卖出方代码,数量,金额
命令:
查询语句:
select day_id,sale_nbr,sum(cnt),sum(round) from sale where sale_nbr like 'O%' or buy_nbr like 'O%' group by day_id,sale_nbr;
创建表table2:
create table table2(day_id String,sale_nbr String, cnt String,round String) ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
将查询结果保存至table2:
insert overwrite table table2 select day_id,sale_nbr,sum(cnt),sum(round) from sale where sale_nbr like 'O%' or buy_nbr like 'O%' group by day_id,sale_nbr;
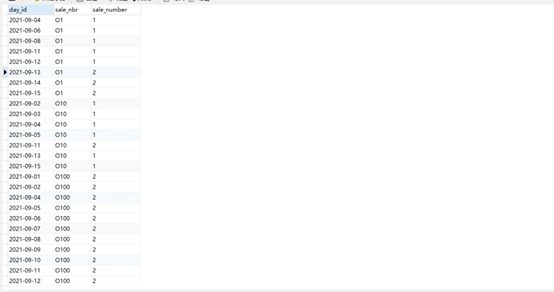
(3)统计每天各个代理商的销售活跃度。 要求的输出字段 day_id,sale_nbr, sale_number 日期编号,卖出方代码,交易次数(买入或者卖出均算交易次数)
命令:
查询语句:
select day_id,sale_nbr,count(sale_nbr)from sale where sale_nbr like "O%" group by sale_nbr,day_id;
创建表table3:
create table table3(day_id String,sale_nbr String, sale_number String) ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
将查询结果保存至表table3:
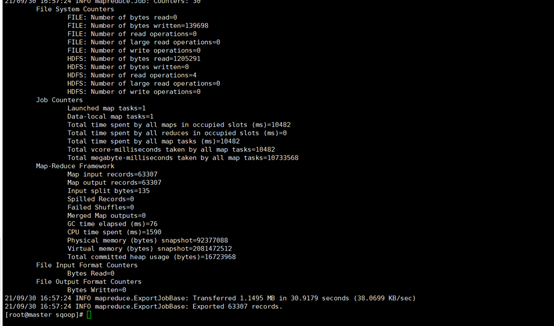
insert overwrite table table3 select day_id,sale_nbr,count(sale_nbr)from sale where sale_nbr like "O%" group by sale_nbr,day_id;

导入mysql:
一
1.建表(可视化建表):
2.sqoop路径下执行命令:
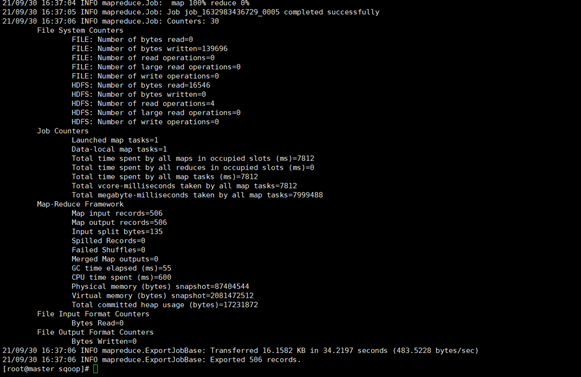
bin/sqoop export \
> --connect jdbc:mysql://master:3306/mysql \
> --username root \
> --password 000000 \
> --table table1\
> --num-mappers 1 \
> --export-dir /user/hive/warehouse/table1 \
> --input-fields-terminated-by ","

二
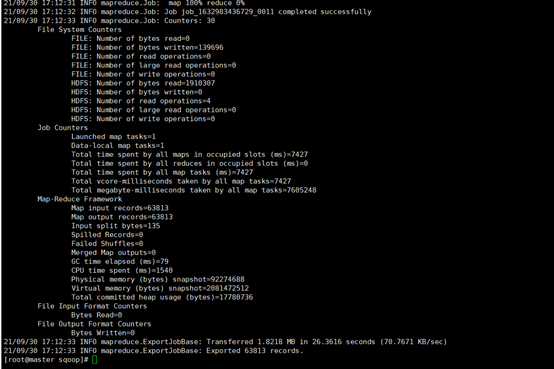
bin/sqoop export \
> --connect jdbc:mysql://master:3306/mysql \
> --username root \
> --password 000000 \
> --table table2\
> --num-mappers 1 \
> --export-dir /user/hive/warehouse/table2 \
> --input-fields-terminated-by ","
三
bin/sqoop export \
> --connect jdbc:mysql://master:3306/mysql \
> --username root \
> --password 000000 \
> --table table3\
> --num-mappers 1 \
> --export-dir /user/hive/warehouse/table3 \
> --input-fields-terminated-by ","
HIVE 数据分析的更多相关文章
- 视频网站数据MapReduce清洗及Hive数据分析
一.需求描述 利用MapReduce清洗视频网站的原数据,用Hive统计出各种TopN常规指标: 视频观看数 Top10 视频类别热度 Top10 视频观看数 Top20 所属类别包含这 Top20 ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
- Hive—学习笔记(一)
主要内容: 1.Hive的基本工能机制和概念 2.hive的安装和基本使用 3.HQL 4.hive的脚本化运行使用方式 5.hive的基本语法--建表语法 6.hive的基本语法--内部表和外部表. ...
- GitBook整理
GitBook整理 ECMAScript 6 -- 中文文档 Apache 2.2 --中文官方文档 Redux --React配套架构 英文 express --Node.js 服务端框架 Hexo ...
- Hadoop学习1(初识hadoop)
Hadoop生态系统的特点 1)源代码开源 2)社区活跃,参与者多 3)涉及分布式存储和计算的各方面 4)已得到企业界的验证 Hadoop构成 1) 分布式文件系统HDFS(Hadoop Distri ...
- 原 荐 使用Spring Boot Actuator、Jolokia和Grafana实现准实时监控
原 荐 使用Spring Boot Actuator.Jolokia和[可视化]Grafana实现准实时监控. 监控系统: 日志- 基础处理 - 表格 - 可视化一体化解决方案. ...
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- 达观数据分析平台架构和Hive实践——TODO
转自: http://www.infoq.com/cn/articles/hadoop-ten-years-part03 编者按:Hadoop于2006年1月28日诞生,至今已有10年,它改变了企业对 ...
- 大数据分析处理框架——离线分析(hive,pig,spark)、近似实时分析(Impala)和实时分析(storm、spark streaming)
大数据分析处理架构图 数据源: 除该种方法之外,还可以分为离线数据.近似实时数据和实时数据.按照图中的分类其实就是说明了数据存储的结构,而特别要说的是流数据,它的核心就是数据的连续性和快速分析性: 计 ...
随机推荐
- circle_clock 简单canvas实现圆弧时钟
渣渣成品图:http://codepen.io/thewindswor... 最近对于圆形有种特别的感情呢...因为写了个cricle_process_bar就像到了用来做时钟大概会比较有趣吧,所以就 ...
- 【译】HTML表单高级样式
系列文章说明 原文 在本文中,我们将了解如何在HTML表单上使用CSS,为那些难于自定义的表单组件加以样式.如前文所述,文本框和按钮很适合使用CSS,而现在我们得来探索HTML表单样式的那些坑了. 在 ...
- 深入理解 flex-grow & flex-shrink & flex-basis
前言 flex 有三个属性值,分别是 flex-grow, flex-shrink, flex-basis,默认值是 0 1 auto. 发现网上详细介绍他们的文章比较少, 今天就详细说说他们,先一个 ...
- 【uniapp 开发】如何给边框添加阴影效果
css的box-shadow是用来添加边框阴影效果的. 属性值详解: 1.inset 可选值,默认阴影在盒子外 使用inset后,阴影在盒子内,即使指定边框或者透明边框,阴影依然存在. 2. 这是头两 ...
- 彻底理解volatile关键字
1. volatile简介 在上一篇文章中我们深入理解了java关键字,我们知道在java中还有一大神器就是关键volatile,可以说是和synchronized各领风骚,其中奥妙,我们来共同探讨下 ...
- box-shadow 阴影的高级用法,多个阴影叠加
box-shadow的这些用法你知道吗? $shadowH: ''; @for $i from 1 through 12 { $shadowH: #{$shadowH}, 0 ($i * 30px) ...
- Blazor组件自做六 : 使用JS隔离封装Baidu地图
1. 运行截图 演示地址 2. 在文件夹wwwroot/lib,添加baidu子文件夹,添加baidumap.js文件 2.1 跟上一篇类似,用代码方式异步加载API,脚本生成新的 body > ...
- [ Linux ] 设置服务器开机自启端口
https://www.cnblogs.com/yeungchie/ 需要用到的工具: crontab iptables crontab.set SHELL=/bin/bash PATH=/sbin: ...
- MySQL 表数据多久刷一次盘?
前言 事情是这样的,在某乎的邀请回答中看到了这个问题: - 然后当时我没多想就啪一下写下来这样的答案: 这个其实要通过 MySQL 后台线程来刷的,在 Buffer Pool 中被修改的过的 Page ...
- Python学习报告及后续学习计划
第一次有学习Python的想法是源于寒假在家的时候,高中同学问我是否学了Python(用于深度学习),当时就到b站收藏了黑马最新的教学视频,但是"收藏过等于我看了",后续就是过完年 ...