手绘模型图带你认识Kafka服务端网络模型
摘要:Kafka中的网络模型就是基于主从Reactor多线程进行设计的。
本文分享自华为云社区《图解Kafka服务端网络模型》,作者:石臻臻的杂货铺 。
Kafka中的网络模型就是基于主从Reactor多线程进行设计的, 在整体讲述Kafka网络模型之前,我们现在按照源码中的相关类来讲解一下他们分别都是用来做什么的。
关键类解析
SocketServer
这个类是网络通信的核心类,它持有这Acceptor和 Processor对象。
ConnectionQuotas
这个是控制连接数配额的类,
涉及到的Broker配置有:

AbstractServerThread
AbstractServerThread 类:这是Acceptor线程和Processor线程的抽象基类,它定义了一个抽象方法wakeup() ,主要是用来唤醒Acceptor 线程和 Processor 对应的Selector的, 当然还有一些共用方法
Acceptor 和 Processor
Acceptor 线程类:继承自AbstractServerThread, 这是接收和创建外部 TCP 连接的线程。每个 SocketServer 实例一般会创建一个 Acceptor 线程(如果listeners配置了多个就会创建多个Acceptor)。它的唯一目的就是创建连接,并将接收到的 SocketChannel(SocketChannel通道用于传输数据) 传递给下游的 Processor 线程处理,Processor主要是处理连接之后的事情,例如读写I/O。
涉及到的Broker配置有:

Processor 线程类:这是处理单个TCP 连接上所有请求的处理线程。每个Acceptor 实例创建若干个(num.network.threads)Processor 线程。Processor 线程负责将接收到的 SocketChannel(SocketChannel通道用于传输数据。), 注册读写事件,当数据传送过来的时候,会立即读取Request数据,通过解析之后, 然后将其添加到 RequestChannel 的 requestQueue 队列上,同时还负责将 Response 返还给 Request 发送方。
涉及到的Broker配置有:

简单画了一张两个类之间的关系图
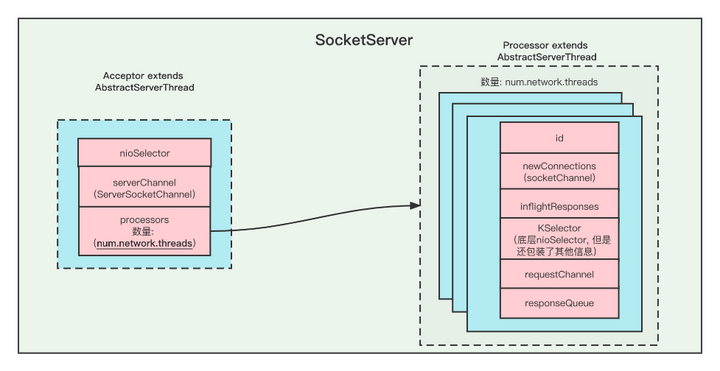
- 这两个类都是 AbstractServerThead的实现类,超类是
Runnable可运行的。 - 每个Acceptor持有
num.network.threads个 Processor 线程, 假如配置了多个listeners,那么总共Processor线程数是listeners*num.network.threads. - Acceptor 创建的是ServerSocketChannel通道,这个通道是用来监听新进来的TCP链接的通道,
通过serverSocketChannel.accept()方法可以拿到SocketChannel通道用于传输数据。 - 每个Processor 线程都有一个唯一的id,并且通过Acceptor拿到的SocketChannel会被暂时放入到
newConnections队列中 - 每个Processor 都创建了自己的Selector
- Processor会不断的从自身的
newConnections队列里面获取新SocketChannel,并注册读写事件,如果有数据传输过来,则会读取数据,并解析成Request请求。
既然两个都是可执行线程,那我们看看两个线程的run方法都做了哪些事情
Acceptor.run
def run(): Unit = {
//将serverChannel 注册到nioSelector上,并且对 Accept事件感兴趣:表示服务器监听到了客户连接,那么服务器可以接收这个连接了
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
try {
var currentProcessorIndex = 0
while (isRunning) {
try {
//返回感兴趣的事件数量 这里是感兴趣的是SelectionKey.OP_ACCEPT,监听到新的链接
val ready = nioSelector.select(500)
if (ready > 0) {
//获取所有就绪通道
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
//遍历所有就绪通道
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
//只处理 Accept事件,其他的事件则抛出异常,ServerSocketChannel是 监听Tcp的链接通道
if (key.isAcceptable) {
//根据Key 拿到SocketChannle = serverSocketChannel.accept(),然后再遍历
accept(key).foreach { socketChannel =>
//将socketChannel分配给我们的 processor来处理,如果有多个socketChannel 则按照轮训分配的原则
//如果一个processor 中能够处理的newconnection 队列满了放不下了,则找下一个
// 如果所有的都放不下,则会一直循环直到有processor能够处理。
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
//轮训每个processors来处理
processor = synchronized {
// adjust the index (if necessary) and retrieve the processor atomically for
// correct behaviour in case the number of processors is reduced dynamically
currentProcessorIndex = currentProcessorIndex % processors.length
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
} else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
catch {
省略
}
}
} finally {
省略
}
}
1、将ServerSocketChannel通道注册到nioSelector 上,并关注事件SelectionKey.OP_ACCEPT
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
2、while循环,持续阻塞监听事件,超时时间500ms
// 阻塞查询Selector是否有监听到新的事件
val ready = nioSelector.select(500)
// 如果有事件,则查询具体的事件和通道
if(ready>0>{
//获取所有就绪事件准备处理
val keys = nioSelector.selectedKeys()
}
3、遍历刚刚监听到的事件, 如果该SelectionKey不包含OP_ACCEPT(建立连接)事件,则抛出异常,通常不会出现这个异常。
Unrecognized key state for acceptor thread
4、如果SelectionKey包含OP_ACCEPT(建立连接)事件,则可以通过这个SelectionKey拿到serverSocketChannel,通过serverSocketChannel 拿到socketChannel,并且将SocketChannel设置为非阻塞模式。
val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]
// 调用accept方法就可以拿到ScoketChannel了。
val socketChannel = serverSocketChannel.accept()
//设置为非阻塞模式 就可以在异步模式下调用connect(), read() 和write()了。
socketChannel.configureBlocking(false)
5、接下来,把上面拿到的SocketChannel以遍历的形式给Acceptor下面的Procesor, 让Processor来执行后面的处理。分配的体现形式是, 将拿到的SocketChannel保存在Processor中的newConnections阻塞队列中,这个newConnections上限是20,在代码里面写死了的,也就是说一个Processor同时最多只能处理20个连接, 那么所有的Processor能处理的最大连接就是Processor数量 * 20;如果你的连接请求并发度很高,可以尝试调大num.network.threads
6、最后,如果newConnections队列放入了一个新的SocketChannel,则会调用一下对应Processor实例的wakeup()方法。
Procesor.run
override def run(): Unit = {
startupComplete()
try {
while (isRunning) {
try {
// setup any new connections that have been queued up
// 将之前监听到的TCP链接(暂时保存在newConnections中) 开始注册监听OP_READ事件到每个Processor的 KSelector选择器中。
configureNewConnections()
// register any new responses for writing
processNewResponses()
//在不阻塞的情况下对每个连接执行任何 I/O 操作。这包括完成连接、完成断开连接、启动新发送或在进行中的发送或接收上取得进展。
// 当此调用完成时,用户可以使用completedSends() 、 completedReceives() 、 connected() 、 disconnected()检查已完成的发送、接收、连接或断开连接。
poll()
// 把请求解析后放到 requestChannels 队列中,异步处理
processCompletedReceives()
//处理已经发送完成的请求
processCompletedSends()
processDisconnected()
closeExcessConnections()
} catch {
// We catch all the throwables here to prevent the processor thread from exiting. We do this because
// letting a processor exit might cause a bigger impact on the broker. This behavior might need to be
// reviewed if we see an exception that needs the entire broker to stop. Usually the exceptions thrown would
// be either associated with a specific socket channel or a bad request. These exceptions are caught and
// processed by the individual methods above which close the failing channel and continue processing other
// channels. So this catch block should only ever see ControlThrowables.
case e: Throwable => processException("Processor got uncaught exception.", e)
}
}
} finally {
debug(s"Closing selector - processor $id")
CoreUtils.swallow(closeAll(), this, Level.ERROR)
shutdownComplete()
}
}
- configureNewConnections(): 之前Acceptor监听到的SocketChannel保存在Procesor中的newConnections阻塞队列中, 现在开始将newConnections阻塞队列一个个取出来,向Procesor的Selector注册SocketChannel通道,并且感兴趣的事件为SelectionKey.OP_READ读事件。
- processNewResponses() : 去Processor里面的无边界阻塞队列responseQueue里面获取RequestChannel.Response数据, 如果有数据并且需要返回Response的话, 则通过channel返回数据. 具体的Channel是根据connectionId 获取之前构建的KafkaChannel, KafkaChannel则会通过监听SelectionKey.OP_WRITE。然后调用writeTo方法。
至于responseQueue这个队列是什么时候入队的,我们后面再分析 - poll(): 这个方法里面执行的就很多了, 这个方法底层调用的是selector.poll(); 将监听到的事件批量处理,它才是执行I/O请求的最终地方, 它正对每个连接执行任何的I/O操作,这包括了 完成连接、完成断开连接、启动新发送等等。
像校验身份信息,还有handshake等等这些也都是在这里执行的。 - processCompletedReceives(): 处理所有completedReceives(已完成接收的请求)进行接下来的处理, 处理的方式是解析一下收到的请求,最终调用了requestChannel.sendRequest(req). 也就是说所有的请求最终通过解析放入到了RequestChannel中的requestQueue阻塞队列中, 这个阻塞队列的大小为queued.max.requests默认500;表示的是在阻塞网络线程之前,数据平面允许的排队请求数
PS: 这个completedReceives 是在 poll()方法中添加的元素。 - processCompletedSends(): 它负责处理 Response 的回调逻辑,通过遍历completedSends(已完成发送)集合 可以从inflightResponses中移除并拿到response对象,然后再调用回调逻辑。
PS: 这个completedSends 是在 poll()方法中添加的元素。 - processDisconnected(): 处理断开链接的情况, connectionQuotas连接限流减掉这个链接,inflightResponses也移除对应连接。
- closeExcessConnections(): 关闭超限连接 ,当总连接数 >max.connections && (inter.broker.listener.name!=listener|| listeners 数量==1) 则需要关闭一些连接.
简单来说就是:就算Broker已经达到了最大连接数的限制了, 也应该允许 broker之间监听器上的连接, 这种情况下,将会关闭另外一个监听器上最近最少使用的连接。broker之间的监听器是配置inter.broker.listener.name 决定的
所谓优先关闭,是指在诸多 TCP 连接中找出最近未被使用的那个。这里“未被使用”就是说,在最近一段时间内,没有任何 Request 经由这个连接被发送到 Processor 线程。
RequestChannel
这个类保存这所有的Processor,还有一个阻塞队列保存这待处理请求。这个队列最大长度由queued.max.requests控制,当待处理请求超过这个数值的时候网络就会阻塞
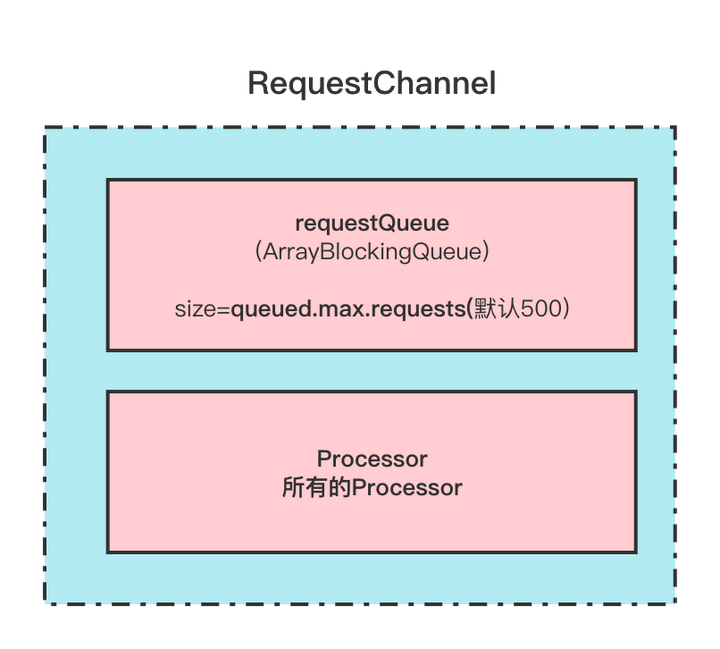 在这里插入图片描述
在这里插入图片描述
涉及到的Broker配置有:

KafkaApis
具体Request的处理类, 所有的请求方法处理逻辑都放在这个里面。
KafkaRequestHandlerPool
KafkaRequestHandler的线程池,KafkaRequestHandler线程的数量由配置num.io.threads决定。
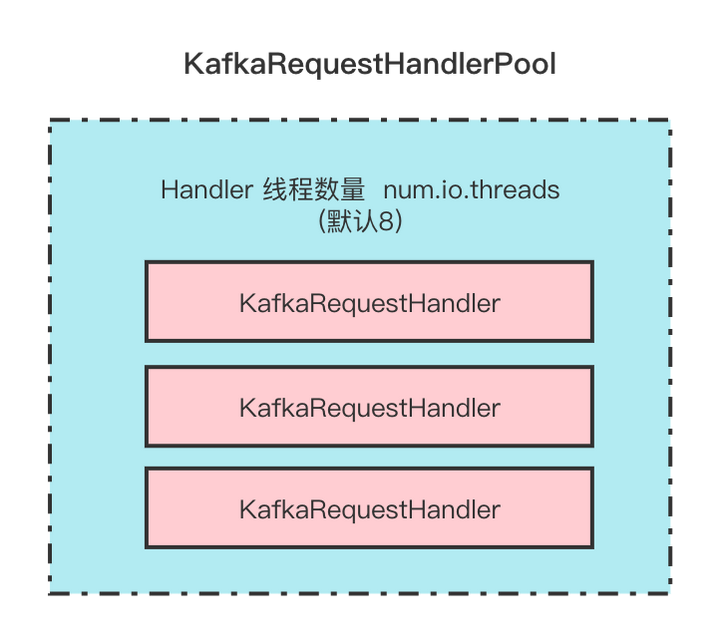 在这里插入图片描述
在这里插入图片描述
涉及到的Broker配置有:

KafkaRequestHandler
请求处理类, 每个Handler都会去 requestChannel的requestQueue队列里面poll请求, 然后去处理,最终调用的处理方法是KafkaApis.handle()
这几个类之间的关系如下
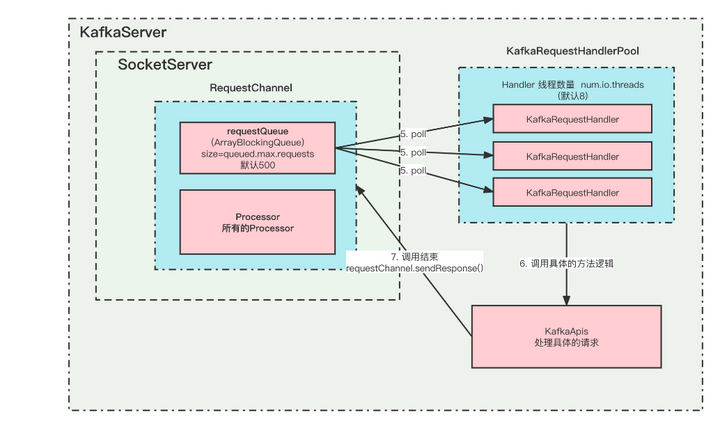 在这里插入图片描述
在这里插入图片描述
通信流程总结
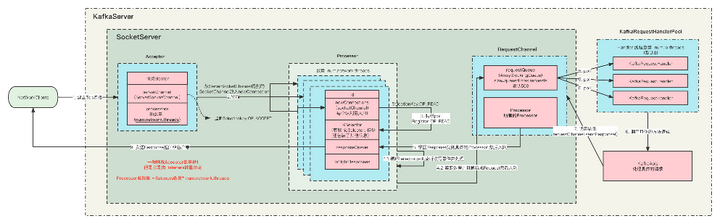 在这里插入图片描述
在这里插入图片描述
- KafkaServer启动的时候,会根据listeners的配置来初始化对应的实例。
- 一个listeners对应一个Acceptor,一个Acceptor持有若干个(num.network.threads)Processor实例。
- Acceptor 中的nioSelector注册的是ServerSocketChannel通道,并监听OP_ACCEPT事件,它只负责 TCP 创建和连接,不包含读写数据。
- 当Acceptor监听到新的连接之后,就会通过调用socketChannel = serverSocketChannel.accept()拿到SocketChannel,然后把SocketChannel保存在Processor里面的newConnection队列中。 那么具体保存在哪个Processor中呢?当然是轮询分配了,确保负载均衡嘛。当然每个Processor的newConnection队列最大只有20,并且是代码写死的。如果一个Processor满了,则会寻找下一个存放,如果所有的都满了,那么就会阻塞。一个Acceptor的所有Processor最大能够并发处理的请求是 20 * num.network.threads。
- Processor会持续的从自己的newConnection中poll数据,拿到SocketChannel之后,就把它注册到自己的Selector中,并且监听事件 OP_READ。 如果newConnection是空的话,poll的超时时间是 300ms。
- 监听到有新的事件,比较READ,则会读取数据,并且解析成Request, 把Request放入到 RequestChannel中的requestQueue阻塞队列中。所有的待处理请求都是临时放在这里面。这个队列也有最大值queued.max.requests(默认500),超过这个大小就会阻塞。
- KafkaRequestHandlerPool中创建了很多(num.io.threads(默认8))的KafkaRequestHandler,用来处理Request, 他们都会一直从RequestChannel中的requestQueue队列中poll新的Request,来进行处理。
- 处理Request的具体逻辑是KafkaApis里面。当Request处理完毕之后,会调用requestChannel.sendResponse()返回Response。
- 当然,请求Request和返回Response必须是一一对应的, 你这个请求是哪个Processor监听到的,则需要哪个Processor返回, 他们通过id来标识。
- Response也不是里面返回的,而是先放到Processor中的ResponseQueue队列中,然后慢慢返回给客户端。
数据面板(DataPlane)
数据面板是用来处理 Broker与Broker/Client之间的网络模型模块, 与之相对的是控制器面板。
控制器面板 是专门用于Controller与Broker之间的网络通信模块。
其实本质上他们都是一模一样的, 但是为了将Controller的通信和普通通信隔离,才有这么两个概念。
上面的网络通信模型就是以数据面板来分析的,因为本质是一样的, 只是有一些配置不一样。
那么,数据面板就不详细讲了,我们主要讲下控制器面板的不一样的地方。
控制器面板(ControllerPlane)
控制器面板是用来专门处理 Controller相关请求的独立通信模块。
大家都知道,Controller是一个很重要的角色,基本上大部分协调整个集群的相关请求都跟它有关系, 比如创建Topic、删除Topic、分区副本重分配、等等。他们都很重要。
但是一般情况下数据面板的请求很多,如果因为请求过多而导致Controller相关请求被阻塞不能执行,那么可能会造成一些影响, 所以我们可以让Controller类的请求有一个单独的通信模块。
首先,要启用控制器面板,必须配置control.plane.listener.name. 并且这个监听器名称必须在listeners里面有配置
否则的话,是不会专用的控制器链接的EndPoint的。
例如:
Broker配置
## 所有的监听器
isteners = INTERNAL://192.1.1.8:9092, EXTERNAL://10.1.1.5:9093, CONTROLLER://192.1.1.8:9094 ## 监听器对应的安全协议
listener.security.protocol.map = INTERNAL: PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL ## 控制器
control.plane.listener.name = CONTROLLER
在启动时,代理将开始使用安全协议“SSL”监听“192.1.1.8:9094”。
在控制器端,当它通过 zookeeper 发现代理发布的端点时,它将使用 control.plane.listener.name 找到端点,它将用于建立与代理的连接。
- 必须配置control.plane.listener.name 才能使用独立的控制器面板
- 控制器面板的RequestChannel中的requestQueue不是由queued.max.requests控制的,而是写死的 20. 因为控制类请求不会有那么大的并发
- 跟DataPlane相关隔离,互不影响。但是连接限流ConnectionQuotas是共享的,限流的时候,两个是算在一起的
- 控制类面板只有一个Acceptor和一个Processor,这个跟数据面板的区别是 DataPlane的Processor可以有多个。
涉及到的Broker配置有:

上面我们主要分析了一下, Kafka中的网络通信模型, 那么聪明的你应该肯定能够看的出来,它是使用线程模型中的 Reactor模式来实现的。
线程模型: Reactor模式
该模块详细请参考Reactor 模型
Reactor 模式,是指通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式。
服务端程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫 Dispatcher 模式。
即 I/O 多路复用统一监听事件,收到事件后分发(Dispatch 给某进程),是编写高性能网络服务器的必备技术之一。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单 Reactor 单线程;
- 单 Reactor 多线程;
- 主从 Reactor 多线程。
我们主要了解一下 主从Reactor 多线程
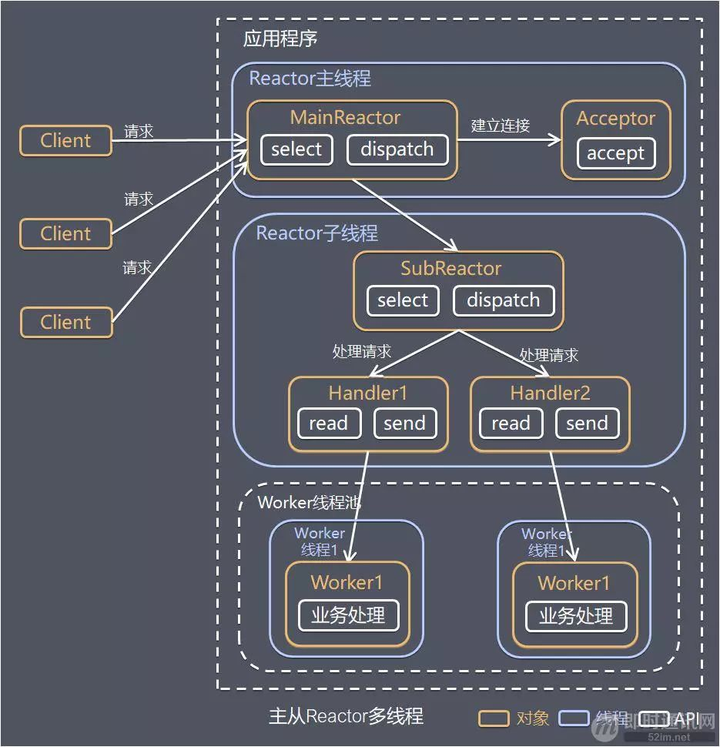 该图来源于网络
该图来源于网络
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
方案说明:
- Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件;
- Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理;
- SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件;
- 当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应;
- Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
- Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
- Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
更详细的介绍可以看 Reactor 模型
问答
(1)Kafka的网络模型使用了Reactor模式的哪种实现方式?
- 单 Reactor 单线程;
- 单 Reactor 多线程;
- 主从 Reactor 多线程。
答案: 3 。 使用了主从Reactor多线程的实现方式.
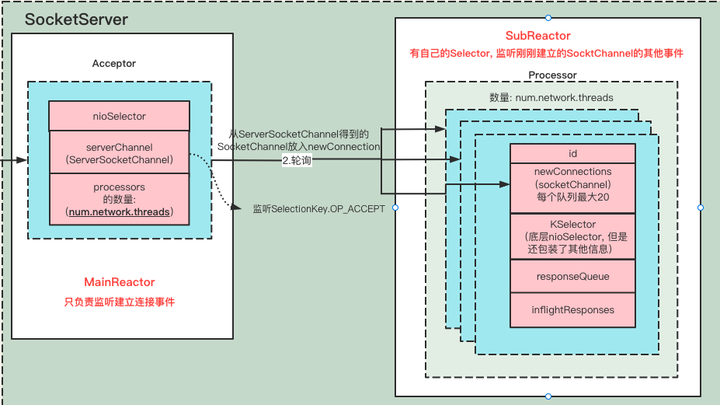 在这里插入图片描述
在这里插入图片描述
MainReactor(Acceptor)只负责监听OP_ACCEPT事件, 监听到之后把SocketChannel 传递给 SubReactor(Processor), 每个Processor都有自己的Selector。SubReactor会监听并处理其他的事件,并最终把具体的请求传递给KafkaRequestHandlerPool。
很典型的主从Reactor多线程模式。
(2)什么是ControllerPlane(控制器面板),什么是DataPlane(数据面板)?
控制器面板: 主要处理控制器类的的请求
数据面板: 主要处理数据类的请求。
让他们隔离,互不影响,比如说普通的请求太多,导致了阻塞, 那么Controller相关的请求也可能被阻塞了,所以让他们隔离,不会互相影响。
但是默认情况下, ControllerPlane是没有设置的,也就是Controller相关的请求还是走的DataPlane。 想要隔离的话必须设置control.plane.listener.name .
- 必须配置control.plane.listener.name
- 控制器面板的RequestChannel中的requestQueue不是由queued.max.requests控制的,而是写死的 20. 因为控制类请求不会有那么大的并发
- 跟DataPlane相关隔离,互不影响。但是连接限流ConnectionQuotas是共享的,限流的时候,两个是算在一起的
- 控制类面板只有一个Acceptor和一个Processor,这个跟数据面板的区别是 DataPlane的Processor可以有多个。
手绘模型图带你认识Kafka服务端网络模型的更多相关文章
- Unity手游之路<二>Java版服务端使用protostuff简化protobuf开发
http://blog.csdn.net/janeky/article/details/17151465 开发一款网络游戏,首先要考虑的是客户端服务端之间用何种编码格式进行通信.之前我们介绍了Unit ...
- Kafka服务端之网络连接源码分析
#### 简介 上次我们通过分析KafkaProducer的源码了解了生产端的主要流程,今天学习下服务端的网络层主要做了什么,先看下 KafkaServer的整体架构图 -服务端实现
一.起航 书接上文->手写MQ框架(一)-准备启程 本着从无到有,从有到优的原则,所以计划先通过web实现功能,然后再优化改写为socket的形式. 1.关于技术选型 web框架使用了之前写的g ...
- kafka服务端实验记录
kafka单机实验: 环境准备: 1.下载kafka,zookeeper,并解压 wget http://mirror.bit.edu.cn/apache/kafka/2.3.0/kafka_2.11 ...
- Kafka技术内幕 读书笔记之(二) 生产者——服务端网络连接
KafkaServer是Kafka服务端的主类, KafkaServer中和网络层有关的服务组件包括 SocketServer.KafkaApis 和 KafkaRequestHandlerPool后 ...
- C#开发BIMFACE系列30 服务端API之模型对比1:发起模型对比
系列目录 [已更新最新开发文章,点击查看详细] 在实际项目中,由于需求变更经常需要对模型文件进行修改.为了便于用户了解模型在修改前后发生的变化,BIMFACE提供了模型在线对比功能,可以利用在 ...
- C#开发BIMFACE系列41 服务端API之模型对比
BIMFACE二次开发系列目录 [已更新最新开发文章,点击查看详细] 在建筑施工图审查系统中,设计单位提交设计完成的模型/图纸,审查专家审查模型/图纸.审查过程中如果发现不符合规范的地方,则流 ...
随机推荐
- JZ-013-调整数组顺序使奇数位于偶数前面
调整数组顺序使奇数位于偶数前面 题目描述 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对 ...
- 『现学现忘』Docker基础 — 12、通过RPM软件包方式安装Docker
CentOS环境下的Docker官方推荐的三种安装方式 yum安装方式 本地RPM安装方式 脚本安装方式 目录 1.下载Docker的RPM安装包 2.安装Docker 3.通过RPM安装包安装Doc ...
- Navicat for MySQL 安装软件和破解补丁
软件 链接:https://pan.baidu.com/s/1e8gpbyWM7ISrWpMwsw-MNg 提取码:fag3 安装好 Navicat 将破解文件放到安装目录下,然后双节运行 是的,你 ...
- tensorflow源码解析之framework-graph
目录 什么是graph 图构建辅助函数 graph_transfer_info 关系图 涉及的文件 迭代记录 1. 什么是graph graph是TF计算设计的载体,如果拿TF代码的执行和Java代码 ...
- linux查看和替换python软连接
linux查看和替换python软连接 查看使用的python版本的路径 # which python 这里是在/usr/bin/python 然后查看链接指向, # ls -l /usr/bin/p ...
- 5种常见的Docker Compose错误
在构建一个容器化应用程序时,开发人员需要一种方法来引导他们正在使用的容器去测试其代码.虽然有几种方法可以做到这一点,但 Docker Compose 是最流行的选择之一.它让你可以轻松指定开发期间要引 ...
- 串和KMP算法
一.串 串是由零个或多个字符串组成的有限序列 (一).串的定义 定长顺序存储 特点:每个串变量分配一个固定长度的存储区,即定长数组 定义: #define MAXLEN 255 typedef str ...
- 配置阿里云RepoForge 镜像
镜像下载.域名解析.时间同步请点击阿里云开源镜像站 一.RepoForge 镜像介绍 Repoforge 是 RHEL 系统下的软件仓库,拥有 10000 多个软件包,被认为是最安全.最稳定的一个软件 ...
- K8S搭建自动化部署环境 Jenkins下载、安装和启动
镜像下载.域名解析.时间同步请点击 阿里云开源镜像站 一.jenkins 下载 jenkins下载地址:https://jenkins.io/zh/download/ 如下图,左边是稳定版本,右边是每 ...
- 模块 序列化模块:json pickle
模块:一个模块就是一个包含了Python定义和声明的文件,文件名就是模块名字加上.py的后缀 模块的形象: 内置模块:安装Python解释器的时候一起安装上的 第三方模块(扩展模块):需要自己安装 自 ...