MapReduce实践
1. 词频统计任务要求
首先,在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。在实际应用中,这两个文件可能会非常大,会被分布存储到多个节点上。但是,为了简化任务,这里的两个文件只包含几行简单的内容。需要说明的是,针对这两个小数据集样本编写的MapReduce词频统计程序,不作任何修改,就可以用来处理大规模数据集的词频统计。
文件wordfile1.txt的内容如下:
I love Spark
I love Hadoop
文件wordfile2.txt的内容如下:
Hadoop is good
Spark is fast
假设HDFS中有一个/user/hadoop/input文件夹,并且文件夹为空,请把文件wordfile1.txt和wordfile2.txt上传到HDFS中的input文件夹下。现在需要设计一个词频统计程序,统计input文件夹下所有文件中每个单词的出现次数,也就是说,程序应该输出如下形式的结果:
fast 1
good 1
Hadoop 2
I 2
is 2
love 2
Spark 2
2. 在Eclipse中创建项目
首先,启动Eclipse,启动以后会弹出如下图所示界面,提示设置工作空间(workspace)。
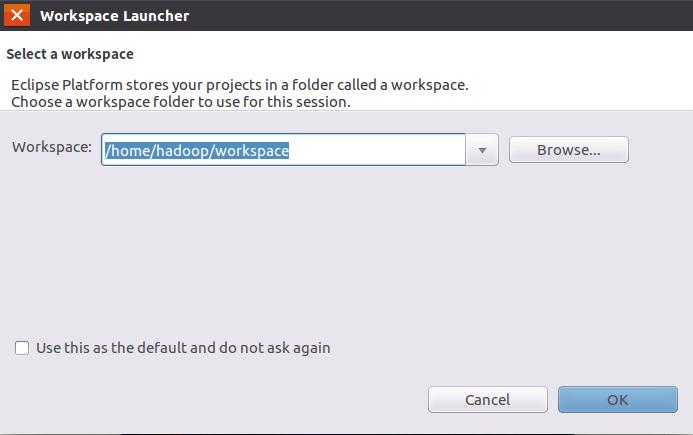
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,呈现的界面如下图所示。

选择“File–>New–>Java Project”菜单,开始创建一个Java工程,弹出如下图所示界面。
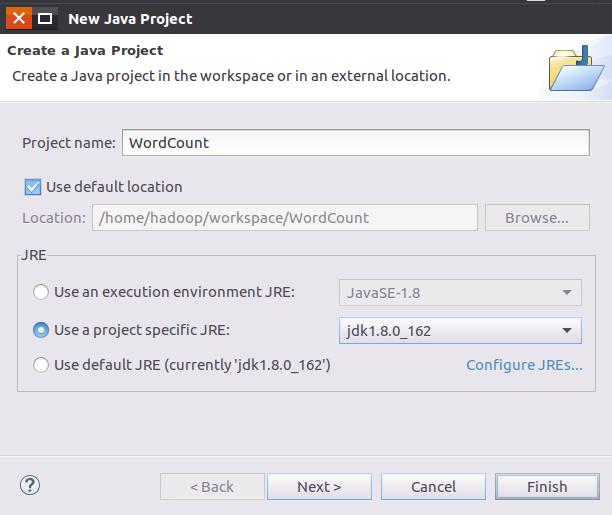
在“Project name”后面输入工程名称“WordCount”,选中“Use default
location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_162。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
3. 为项目添加需要用到的JAR包
进入下一步的设置以后,会弹出如下图所示界面。
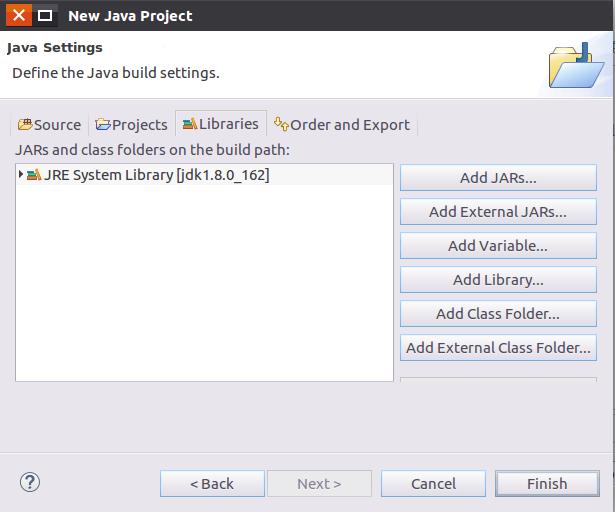
需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了与Hadoop相关的Java
API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add
External JARs…”按钮,弹出如下图所示界面。

在该界面中,上面有一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录,具体如下图所示。
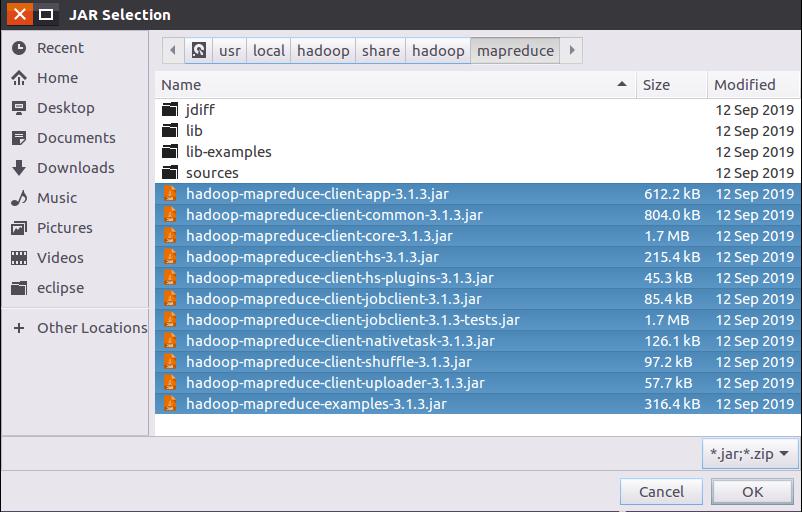
(4)“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar添加到当前的Java工程中,可以在界面中点击相应的目录按钮,进入到common目录,然后,界面会显示出common目录下的所有内容(如下图所示)。
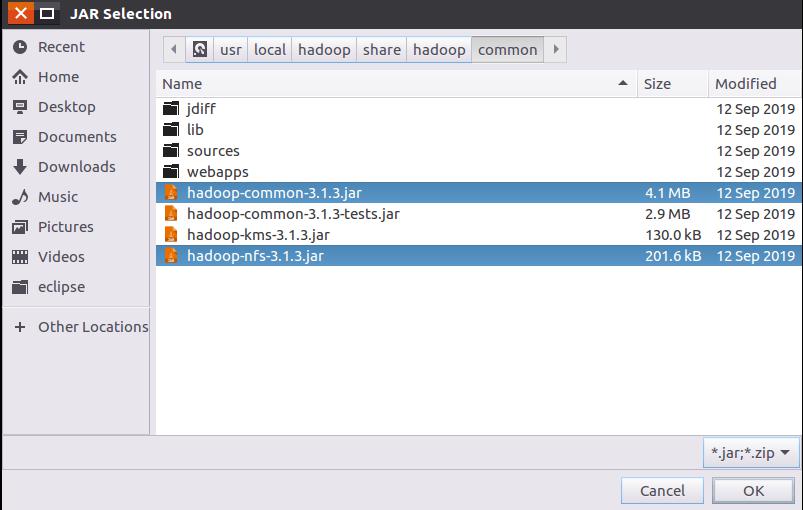
请在界面中用鼠标点击选中hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar,然后点击界面右下角的“确定”按钮,就可以把这两个JAR包增加到当前Java工程中,出现的界面如下图所示。
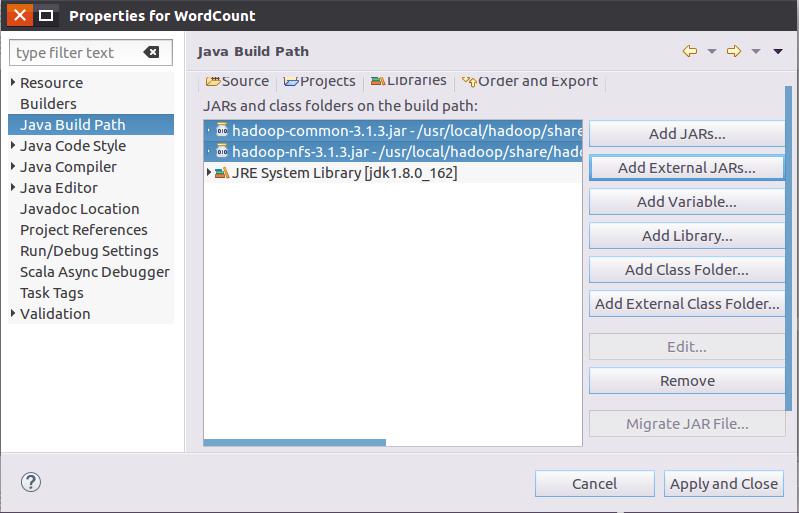
从这个界面中可以看出,hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar已经被添加到当前Java工程中。然后,按照类似的操作方法,可以再次点击“Add
External
JARs…”按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有JAR包时,可以使用“Ctrl+A”组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程WordCount的创建。
4. 编写Java应用程序
下面编写一个Java应用程序,即WordCount.java。请在Eclipse工作界面左侧的“Package
Explorer”面板中(如下图所示),找到刚才创建好的工程名称“WordCount”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New–>Class”菜单。
选择“New–>Class”菜单以后会出现如下图所示界面。
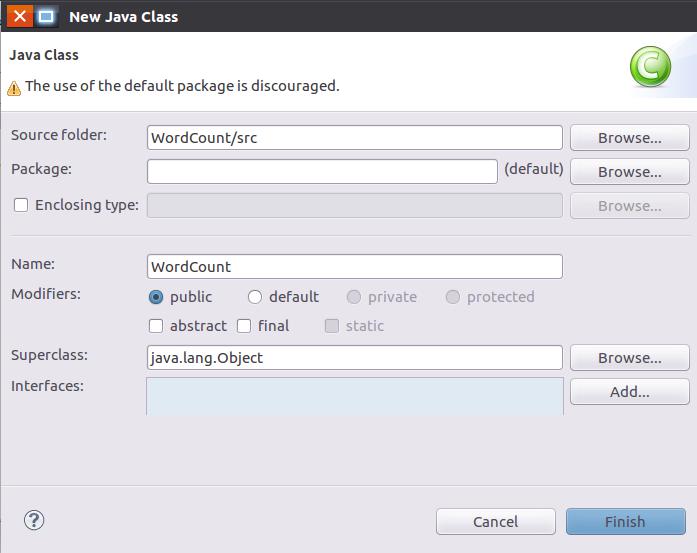
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“WordCount”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现如下图所示界面。

可以看出,Eclipse自动创建了一个名为“WordCount.java”的源代码文件,并且包含了代码“public class WordCount{}”,请清空该文件里面的代码,然后在该文件中输入完整的词频统计程序代码,具体如下:
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- public WordCount() {
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
- if(otherArgs.length < 2) {
- System.err.println("Usage: wordcount <in> [<in>...] <out>");
- System.exit(2);
- }
- Job job = Job.getInstance(conf, "word count");
- job.setJarByClass(WordCount.class);
- job.setMapperClass(WordCount.TokenizerMapper.class);
- job.setCombinerClass(WordCount.IntSumReducer.class);
- job.setReducerClass(WordCount.IntSumReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- for(int i = 0; i < otherArgs.length - 1; ++i) {
- FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
- }
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
- System.exit(job.waitForCompletion(true)?0:1);
- }
- public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
- private static final IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public TokenizerMapper() {
- }
- public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while(itr.hasMoreTokens()) {
- this.word.set(itr.nextToken());
- context.write(this.word, one);
- }
- }
- }
- public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public IntSumReducer() {
- }
- public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
- int sum = 0;
- IntWritable val;
- for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
- val = (IntWritable)i$.next();
- }
- this.result.set(sum);
- context.write(key, this.result);
- }
- }
- }
5. 编译打包程序
现在就可以编译上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,如下图所示。
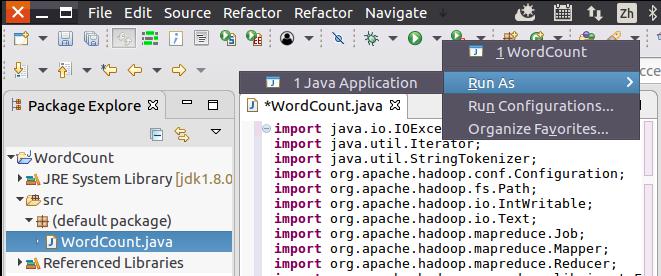
然后,会弹出如下图所示界面。
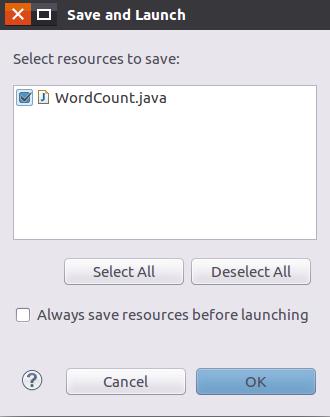
点击界面右下角的“OK”按钮,开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息(如下图所示)。
注意:如果报JDK版本不得低于1.5的错误,则需右键点击java Application 在属性面板中修改jdk版本(默认设置为jdk1.4)

下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
- cd /usr/local/hadoop
- mkdir myapp
首先,请在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。

然后,会弹出如下图所示界面。
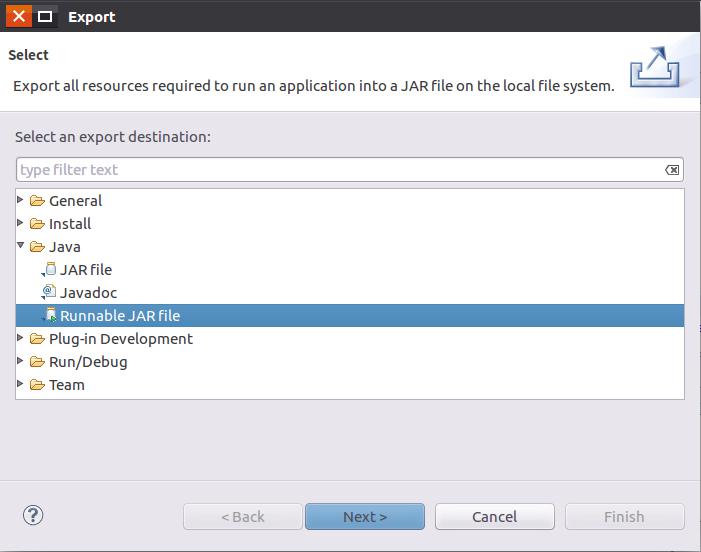
在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示界面。
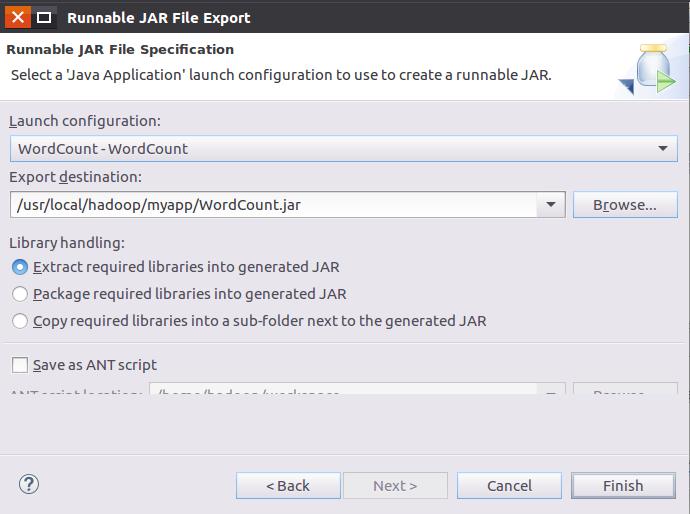
在该界面中,“Launch
configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export
destination”中需要设置JAR包要输出保存到哪个目录,比如,这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library
handling”下面选择“Extract required libraries into generated
JAR”。然后,点击“Finish”按钮,会出现如下图所示界面。
可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示。
可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令:
- cd /usr/local/hadoop/myapp
- ls
可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个WordCount.jar文件。
5. 运行程序
在运行程序之前,需要启动Hadoop,命令如下:
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题,具体命令如下:
- cd /usr/local/hadoop
- ./bin/hdfs dfs -rm -r input
- ./bin/hdfs dfs -rm -r output
然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
- cd /usr/local/hadoop
- ./bin/hdfs dfs -mkdir input
然后,把之前在第7.1节中在Linux本地文件系统中新建的两个文件wordfile1.txt和wordfile2.txt(假设这两个文件位于“/usr/local/hadoop”目录下,并且里面包含了一些英文语句),上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
- cd /usr/local/hadoop
- ./bin/hdfs dfs -put ./wordfile1.txt input
- ./bin/hdfs dfs -put ./wordfile2.txt input
如果HDFS中已经存在目录“/user/hadoop/output”,则使用如下命令删除该目录:
- cd /usr/local/hadoop
- ./bin/hdfs dfs -rm -r /user/hadoop/output
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
- cd /usr/local/hadoop
- ./bin/hadoop jar ./myapp/WordCount.jar input output
上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:
……//这里省略若干屏幕信息
2020-01-27 10:10:55,157 INFO mapreduce.Job: map 100% reduce 100%
2020-01-27 10:10:55,159 INFO mapreduce.Job: Job job_local457272252_0001 completed successfully
2020-01-27 10:10:55,174 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=115463648
FILE: Number of bytes written=117867638
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=283
HDFS: Number of bytes written=40
HDFS: Number of read operations=24
HDFS: Number of large read operations=0
HDFS: Number of write operations=5
Map-Reduce Framework
Map input records=9
Map output records=24
Map output bytes=208
Map output materialized bytes=140
Input split bytes=236
Combine input records=24
Combine output records=12
Reduce input groups=6
Reduce shuffle bytes=140
Reduce input records=12
Reduce output records=6
Spilled Records=24
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=0
Total committed heap usage (bytes)=1291321344
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=113
File Output Format Counters
Bytes Written=40
词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
- cd /usr/local/hadoop
- ./bin/hdfs dfs -cat output/*
上面命令执行后,会在屏幕上显示如下词频统计结果:
Hadoop 2
I 2
Spark 2
fast 1
good 1
is 2
love 2
至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。
声明:文章来源厦门大学林子雨编著的《大数据技术原理与应用(第3版)》经本人实践验证可行运行结果正确,但要注意修改Java Application 的jdk版本到1.7(默认1.4,1.5以下版本会报错),这点原文未提到。
MapReduce实践的更多相关文章
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- 化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- [转] Hadoop MapReduce开发最佳实践(上篇)
前言 本文是Hadoop最佳实践系列第二篇,上一篇为<Hadoop管理员的十个最佳实践>. MapRuduce开发对于大多数程序员都会觉得略显复杂,运行一个WordCount(Hadoop ...
- Mapreduce简要原理与实践
探索Mapreduce简要原理与实践 目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapred ...
随机推荐
- 【转】BIO,NIO和AIO
本文转自:https://blog.csdn.net/qxy_1218/article/details/123941039 BIO,NIO和AIO是Java网络编程的三种模型 BIO:同步并阻塞,服务 ...
- nginx 编译安装支持 upload progress module, upload module
下载地址: wiki.nginx.org/HttpUploadModule wiki.nginx.org/HttpUploadProgressModule 下载后解压至:/usr/src/文件夹下,其 ...
- python学习之路---基础概念扩展:变量,表达式,算法,语句,函数,模块,字符串
对于学过一点编程语言的人,学习python基础知识不难,基本大同小异 本章是根据一本书来学习python的编程(强烈推荐)来记录学习python中的有意思的总结 Python 基础教程(第三版) ...
- Uncaught ReferenceError: Vue is not defined(之一)
报错信息 Uncaught ReferenceError- Vue is not defined 报错代码示例 <body> <div id="app"> ...
- JDK8的异步处理方式-CompletableFuture的使用
一.背景 jdk8中加入了实现类CompletableFuture,用于异步编程.底层做任务使用的是ForkJoin, 顾名思义,是将任务的数据集分为多个子数据集,而每个子集,都可以由独立的子任务来处 ...
- mongoDB日常操作02
db.TABLE_NAME.find({<query>})//普通查询db.TABLE_NAME.find({<query>},{'_id':0,'f1':1,'f2':1}) ...
- ubuntu 20.04 基于kubeadm部署kubernetes 1.22.4集群—报错解决
一.添加node节点,报错1 注:可以提前在各node节点上修改好(无报错无需执行此项) yang@node2:~$ sudo kubeadm join 192.168.1.101:6443 --to ...
- Godot从编辑器创建自定义场景类型对象
Godot的编辑器提供了强大的所见即所得功能,并且,我们可以在不从源码编译的情况下,为编辑器提供新的节点类型. 首先,我们创建一个新场景,然后添加一个Node2D,然后为当前节点(Node2D)添加一 ...
- NTP时钟服务器(时间同步服务器)在大数据时代的重要性
NTP时钟服务器(时间同步服务器)在大数据时代的重要性 NTP时钟服务器(时间同步服务器)在大数据时代的重要性 技术交流:岳峰 15901092122 bjhrkc@126.com 大数据时代众 ...
- shell_Day01
1.判断/etc/inittab文件是否大于100行,如果大于,则显示"/etc/inittab is a big file."否者显示"/etc/inittab is ...