K近邻算法(k-nearest neighbor, kNN)
K近邻算法(K-nearest neighbor, KNN)
KNN是一种分类和回归方法。
- KNN简介
- KNN模型3要素
- KNN优缺点
- KNN应用
- 参考文献
KNN简介
KNN思想
给定一个训练集
T={(x1,y1),(x2,y2),...,(xN,yN)}
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,对新输入的实例
x
x
,在训练集中找到与实例 xx 最近的k个实例,根据k个实例中大多数类所属的类作为实例
x
x
<script type="math/tex" id="MathJax-Element-4">x</script> 所属的类。
KNN算法

KNN模型3要素
K值得选择、距离度量方法选择、分类决策规则选择
-
应用中,一般选择较小的k值,交叉验证可以选择最优的k值。
k值减小,模型变复杂,容易过拟合(原因:选择较小k值时,近似误差减小,估计误差增大)。 -
近似误差:即对现有训练集的训练误差,更关注“训练”。
估计误差:即对测试集的测试误差,更关注“测试”。 -
欧氏距离
曼哈顿距离
切比雪夫距离
等等 - 最常用的是,大多数原则:即由输入实例的k个近邻样本中大多数的类别确定输入实例的类。
K值得选择
距离度量方法选择
分类决策规则选择
KNN优缺点
- 简单、精度高
- 计算时间、空间复杂度高
优点
缺点
KNN应用
使用knn算法识别手写数字数据集,链接:https://pan.baidu.com/s/1rgiGBLTMiybCCSUnzR1lYw 密码:yse7
# -*-coding:utf-8-*-
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # shape[0]读取矩阵第一维的长度
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # numpy.tile(A,B)函数重复A, B次
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#print(type(distances))
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32*i + j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('digits/trainingDigits') # 加载训练集
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] # 提取文件名
classNumStr = int(fileStr.split('_')[0]) # 提取类别标签
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = listdir('digits/testDigits') # 加载测试集
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
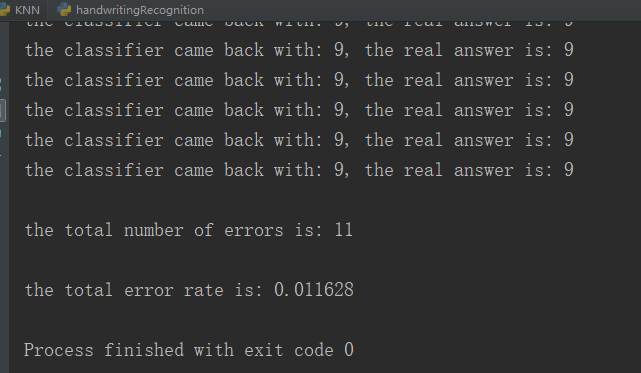
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print ("\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))
if __name__ == '__main__':
handwritingClassTest()程序运行结果:
参考文献
[1]李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2]Peter Harrington. 机器学习实战[M]. 人民邮电出版社, 2013.
K近邻算法(k-nearest neighbor, kNN)的更多相关文章
- k近邻算法(k-nearest neighbor,k-NN)
kNN是一种基本分类与回归方法.k-NN的输入为实例的特征向量,对应于特征空间中的点:输出为实例的类别,可以取多类.k近邻实际上利用训练数据集对特征向量空间进行划分,并作为其分类的"模型&q ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
随机推荐
- Docker 容器默认root账号运行,很不安全!
文章转载自:https://mp.weixin.qq.com/s/AeZoEKZBWFYwyhgicpgD4Q
- redis cluster 6.2集群
redis最新版本:redis-6.2.1.tar.gz 安装的版本是redis-6.0.3 采用的主机: djz-server-001 192.168.2.163 7001,7002,Admin@1 ...
- Docker MySql 查看版本的三种方法
目录 Docker MySql 查看版本的三种方法 1.mysql -V命令查看版本 2.status命令查看版本 3.version命令查看版本 Docker MySql 查看版本的三种方法 1.m ...
- MES系统与ERP系统信息集成有哪些原则?
首先,MES和ERP应该是两个独立的系统,简单的说,ERP与MES有点像公司总部与分厂的关系,ERP向MES发指令,MES向ERP做汇报,所以可以按照这个思维来考虑或类比来处理.从企业的管理来说,ER ...
- 影响 erp 系统实施成功的因素是什么?
影响ERP系统实施成功的因素很多,主要有以下几点:企业一把手是否大力支持.实施顾问是否专业负责.ERP系统是否强大灵活且适用三个方面!没有企业一把手的大力支持,ERP的应用基本上不可能获得成功.ERP ...
- 洛谷P3376 (最大流模板)
1 #include<bits/stdc++.h> 2 #define int long long 3 using namespace std; 4 const int maxn=5005 ...
- 分布式存储系统之Ceph集群RBD基础使用
前文我们了解了Ceph集群cephx认证和授权相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16748149.html:今天我们来聊一聊ceph集群的 ...
- C++ 队列!还是要从 STL 中的说起……
1. 前言 队列和栈一样,都是受限的数据结构. 队列遵循先进先出的存储原则,类似于一根水管,水从一端进入,再从另一端出去.进入的一端称为队尾,出去的一端称为队头. 队列有 2 个常规操作: 入队:进入 ...
- 生产系统CPU飙高问题排查
现状 生产系统CPU占用过高,并且进行了报警 排查方法 执行top命令,查看是那个进程导致的,可以确定是pid为22168的java应用导致的 执行top -Hp命令,查看这个进程的那个线程导致cpu ...
- 经典排序算法之-----选择排序(Java实现)
其他的经典排序算法链接地址:https://blog.csdn.net/weixin_43304253/article/details/121209905 选择排序思想: 思路: 1.从整个数据中挑选 ...