【大数据面试】【框架】Shuffle优化、内存参数配置、Yarn工作机制、调度器使用
三、MapReduce
1、Shuffle及其优化☆
Shuffle是Map方法之后,Reduce方法之前,混洗的过程
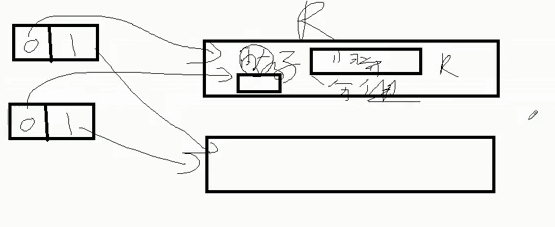
Map-->getPartition(标记数据的分区)-->对应的环形缓冲区(一侧存数据,一侧存索引,默认大小为100M,达到80%时进行反向溢写以提高空间利用率)
(溢写前需要对数据进行排序,默认快排,对key的索引排序,按照字典顺序排)(会产生大量的溢写文件)
【如何对溢写文件进行排序】:按照指定分区进行归并排序
优化:
环形缓冲区调整为200m,反向溢写的比例达到90+%,减少溢写的个数
溢写前进行一次combiner求和,默认一次归并10个,调大其数值(服务器性能可以,不会OOM内存溢出)
对数据进行压缩
【哪些地方能够对数据进行压缩?如何压缩】
Map输入输出端、Reduce的输出端
Map输入:数据量超过128M时,看是否有必要对数据切片,lzo、bzip2支持切片(数据量大时)
Map输出:快的是snappy、lzo
Reduce的输出端:看数据的最终流向(下一个MR看是否支持切片)(永久保存考虑压缩比最高)
【100个分区的数据,默认一次拉取5个,增大每批次拉取的个数,和reduce阶段的内存】
2、NodeManager的默认内存
企业服务器默认内存是128G
NodeManager的默认内存:8G【通常需要调整】
Map Task
Reduce Task
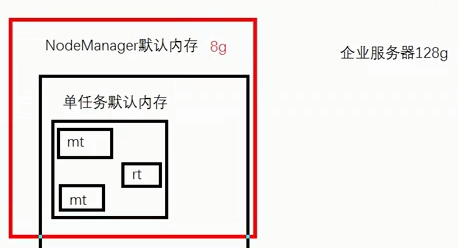
16G的任务,OOM
默认不配置就是8G内存,生产环境下需要配置到90-100G左右,给其他服务器资源留10G左右
3、配置单任务的默认内存
单任务的默认内存:8G
如果有1G/1T/10T的数据
如何调整其内存
估计,128M数据,对应1G内存
1G数据,对应8G内存左右
2G数据量,对应16G内存左右
4、其他默认
Map Task:1G
Reduce Task:1G
如果数据量是128M,不用调整
如果数据量大,且不支持切片,如500M,就需要根据比例调整,配置4G的内存
进入reduce的数据量比较大,适当增大内存
5、配置参数的等级优先级
defaul==》site.xml==》Idea的配置文件==》代码
6、Hadoop命令行如何提交文件
maven打包
hadoop jar wc.jar Class类名 输入路径 输出路径
7、内存设置

8、其他
Spark Shuffle和Hadoop Shuffle的区别
各讲一下其原理
四、Yarn
1、Yarn工作机制(笔试题)【客户端和集群】
客户端
集群:ResourceManager
集群模式(xml是参数的等级,切片影响MapTask的个数)
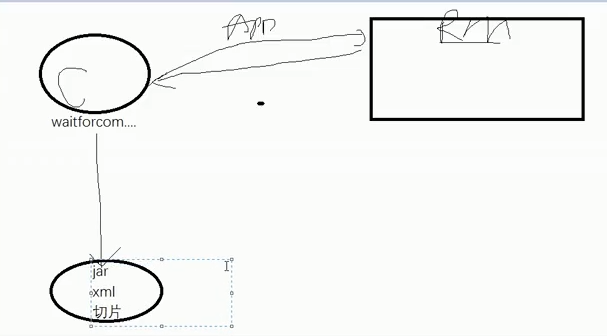
任务在队列中排队,nodemanager接收并执行任务
ApplicationMasterr负责执行,内部container容器拉取指定分区数据
Map按照分区存储在磁盘上-》reduce阶段,拉取完指定数据后释放
2、Yarn的调度器(与生产环境相关)
常见调度器:FIFO、容量、公平调度器
默认调度器是?Apache和CDH
FIFO调度器:支持单队列、先进先出(生产环境不会用)
容量调度器(Apache消耗资源少):支持多个队列,优先保证先进来的资源执行
公平调度器(CDH,占用资源多,需要内存大):保证所有任务公平享有资源,每个任务都分配2G,新进入任务,其他任务释放一定资源。保证每个任务公平享有资源
3、生产环境下如何选择
如果对并发度要求比较高,选择公平调度器,要求服务器性能必须好【大公司】
中小公司一般使用容量调度器,集群服务器资源不太充裕
4、容量调度器默认几个队列
默认只有一个default队列
5、生产环境下如何创建队列
两种方式
可以按照框架:hive/spark/flink放入指定的队列中【企业不常用】
也可以按照业务模块划分:登录队列、注册、购物车、下单、业务部门1、业务部门2
原因:怕新员工写递归死循环代码,导致所有资源全部耗尽
切记,不要使用rm -rf /*
也可以对任务队列划分优先级,集群资源不够用,只留重点资源的执行,对其他资源进行降级
【大数据面试】【框架】Shuffle优化、内存参数配置、Yarn工作机制、调度器使用的更多相关文章
- MySQL性能优化-内存参数配置
Mysql对于内存的使用,可以分为两类,一类是我们无法通过配置参数来配置的,如Mysql服务器运行.解析.查询以及内部管理所消耗的内存:另一类如缓冲池所用的内存等. Mysql内存参数的配置及重要,设 ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- JAVA JVM常见内存参数配置简析
JVM常见内存参数配置简析 常见参数 -Xms .-Xmx.-XX:newSize.-XX:MaxnewSize.-Xmn(-XX:newSize.-XX:MaxnewSize) 简析 1.-Xm ...
- mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置
mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置 转载自勤奋的小青蛙 mongodb占用内存非常高,这是因为官方为了提升存储的效率,设计就这么设计的. 但是大部分的个人 ...
- 一条SQL在内存结构与后台进程工作机制
oracle服务器由数据库以及实例组成,数据库由数据文件,控制文件等物理文件组成,实例是由内存结构+后台进程组成,实例又可以看做连接数据库的方式,在我看来就好比一家公司,实例就是一个决策的办公室,大大 ...
随机推荐
- 一条命令查看docker容器的ip地址
docker inspect --format='{{.NetworkSettings.IPAddress}}' ID/container_name
- AlertManager企业微信报警,时间是UTC时间,错8个小时的两种解决办法
第一种 {{ (.StartsAt.Add 28800e9).Format "2020-01-02 15:04:05" }} 或者是 {{ ($alert.StartsAt.Add ...
- 使用scrapy爬取长安有妖气小说
目标网站:https://www.snwx3.com/txt/434282.html 第一章地址:https://www.snwx3.com/book/434/434282/92792998.html ...
- 关于vmware虚拟机的ova/ovf转换成aws上的AMI镜像
很多时候,我们会有这样的需求,需要将DC中vmware虚拟化的服务器,迁移到aws上,我们就得先将vmware虚拟机导出,然后转换 关于vmvare虚拟的导出备份,一般有ova(Open Virtua ...
- 洛谷P1640 SCOI2010 连续攻击游戏 (并查集/匹配)
本题介绍两种做法: 1 并查集 1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N=1000005; 4 int ...
- python 运行错误收集
目录 global全局声明错误 global全局声明错误 SyntaxError: name 'is_login' is used prior to global declaration 解决办法:g ...
- 2022网刃杯ics
目录 easyiec Ncsubj 喜欢移动的黑客 xyp07 ICS6-LED_BOOM 根据大佬的wp后,自己做了一遍 这次学到很多东西 ICS easyiec tcp追踪流直接能看到 编辑 ...
- 齐博x1会员中心如何加标签
点击查看大图 轻松几步,你可以做会员中心的界面 这是调用文章的 代码如下:会员中心的标签跟前台使用方法是一模一样的, 关键之处就是多了一项动态参数 union="uid" 在以往, ...
- 【Kubernetes】K8s笔记(十一):Ingress 集群进出流量总管
目录 0. Ingress 解决了什么问题 1. Ingress Controller 2. 指定 Ingress Class 使用多个 Ingress Controller 3. 使用 YAML 描 ...
- Python基础部分:11、文件和光标移动
目录 一.文件操作 1.文件的概念 2.代码打开文件的方式 二.文件读写模式 1.'r' 只读模式 read 2.'w' 只写模式 write 3.'a' 尾部追写模式 add 三.文件操作模式 1. ...