【实时数仓】Day04-DWS层业务:DWS设计、访客宽表、商品主题宽表、流合并、地区主题表、FlinkSQL、关键词主题表、分词
一、DWS层与DWM设计
1、思路
之前已经进行分流
但只需要一些指标进行实时计算,将这些指标以主题宽表的形式输出
2、需求
访客、商品、地区、关键词四层的需求(可视化大屏展示、多维分析)
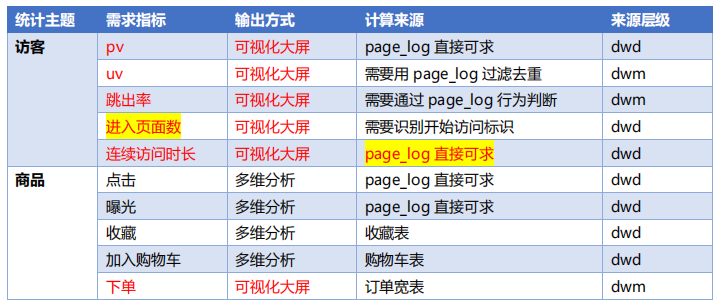

3、DWS层定位
轻度聚合、主题中管理
二、DWS层-访客主题宽表的计算

DWS表主要包含维度表和事实表
维度表主要包括渠道、地区、版本、新老用户等
事实表主要包括PV、UV、跳出次数、进入页面数(session_count)、连续访问时长等
1、需求分析
合并接收到的数据流,按时间窗口聚合,并将聚合结果写入数据库
2、实现
(1)读取kafka各个流的数据
page_log、dwm_uv、dwm_jump_user跳出用户
(2)合并读取到的数据流
使用union合并两个结构相同的数据流
需要提前调整数据结构封装主题宽表实体类(两个待合并的流也都要是这样的结构)
userJumpDStream.map实现转换
合并4条输入的流:
uniqueVisitStatsDstream.union(
pageViewStatsDstream,
sessionVisitDstream,
userJumpStatDstream
);
(3)根据维度进行聚合
设置时间标记及水位线
4个维度作为key,使用tuple4组合,进行分组,.keyBy(new KeySelector
reduce窗口内聚合,并补充时间字段
(4)写入OLAP数据库ClickHouse
专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度
先建表,使用 ReplacingMergeTree 引擎来保证幂等性
将日期变为数字作为分区类型
编写ClickhouseUtils工具类
创建 TransientSink 注解,标记不需要保存的字段
配置连接地址类,并增加写入OLAP的sink
查看控制台输出及表中数据 visitor_stats_2021
三、商品主题宽表

把多个事实表的明细数据汇总起来组合成宽表
1、需求及思路
获取数据流并转换为统一的数据对象格式
将统一数据结构合并为一个流
设定事件时间与水位线,分组、开窗、聚合
关联维度表补充数据
写入ClickHouse
2、功能实现
建商品统计实体类(各种业务数据的统计),并给必要字段添加@Builder.Default注解,各类添加@Builder注解(构造方法)
kafka中获取指定的流:FlinkKafkaConsumer<String> pageViewSource = MyKafkaUtil.getKafkaSource(pageViewSourceTopic,groupId);
对各种流数据进行结构转换,转换为构建的实体类
创建电商业务常量类 GmallConstant,类似维度表,用一个数字表示一个字符串
将统一的数据结构合并为一个流
设定事件时间与水位线
按商品id分组,10秒的窗口进行开窗window(TumblingEventTimeWindows.of(Time.seconds(10)))
补充商品维度、SKU维度、品类维度、品牌维度等信息
- SingleOutputStreamOperator<ProductStats> productStatsWithTmDstream =
- AsyncDataStream.unorderedWait(productStatsWithCategory3Dstream,
- new DimAsyncFunction<ProductStats>("DIM_BASE_TRADEMARK") {
- @Override
- public void join(ProductStats productStats, JSONObject jsonObject) throws
- Exception {
- productStats.setTm_name(jsonObject.getString("TM_NAME"));
- }
- @Override
- public String getKey(ProductStats productStats) {
- return String.valueOf(productStats.getTm_id());
- }
- }, 60, TimeUnit.SECONDS);
- productStatsWithTmDstream.print("to save");
ClickHouse中创建商品主题宽表,添加写入ch的sink
- //TODO 7.写入到 ClickHouse
- productStatsWithTmDstream.addSink(
- ClickHouseUtil.<ProductStats>getJdbcSink(
- "insert into product_stats_2021 values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"));
查看ClickHouse表中的数据
四、地区主题表(Flink SQL)

1、需求分析
定义 Table 流环境,把数据源定义为动态表
通过 SQL 查询出结果表并转换为数据流
将数据流写入目标数据库
2、功能实现
(1)添加FlinkSQL依赖
(2)定义 Table 流环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
(3)将数据源topic定义为动态表WITH (" + MyKafkaUtil.getKafkaDDL(orderWideTopic, groupId) + ")");
WATERMARK FOR rowtime AS rowtime 是把某个虚拟字段设定为 EVENT_TIME
(4)拼接 Kafka 相关属性到 DDL
(5)做聚合运算
Env.sqlQuery("select " +……并将其转换为数据流
DataStream<ProvinceStats> provinceStatsDataStream =
tableEnv.toAppendStream(provinceStateTable, ProvinceStats.class);
(6)定义地区统计宽表实体类并写入到ClickHouse(addSink)
五、关键词主题表(Flink SQL)
1、需求分析
维度聚合决定关键词的大小
来源:用户在搜索框中的搜索、以商品为主题的统计中获取
2、搜索关键词的实现
(1)使用IK分词器对字符串进行分词
(2)编写自定义函数,将分词器加入FlinkSQL中
Flink的自定义函数包括:Scalar Function(相当于 Spark 的 UDF)、Table Function(相当于 Spark 的 UDTF)、Aggregation Functions (相当于 Spark 的 UDAF)
由于分词是一对多的拆分,应该选择TableFunction
封装 KeywordUDTF 函数,自定义UDTF,继承TableFunction
(3)定义Table流环境
(4)注册自定义函数,将数据源定义为动态表
(5)过滤非空数据 tableEnv.sqlQuery
(6)利用 UDTF 进行拆分(SQL内部)LATERAL TABLE(ik_analyze(fullword)) as T(keyword)");
(7)聚合,根据各个关键词出现次数进行 ct
(8)转换为流并写入 ClickHouse
建表、封装实体类、添加sink
六、总结
1、DWS 层主要是基于 DWD 和 DWM 层的数据进行轻度聚合统计
2、利用 union 操作实现多流的合并
3、窗口聚合操作
4、对 clickhouse 数据库的写入操作
5、FlinkSQL 实现业务
6、分词器的使用
7、在 FlinkSQL 中自定义函数的使用
【实时数仓】Day04-DWS层业务:DWS设计、访客宽表、商品主题宽表、流合并、地区主题表、FlinkSQL、关键词主题表、分词的更多相关文章
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
随机推荐
- acme.sh官方中文说明文档
转载自:https://github.com/acmesh-official/acme.sh/wiki/说明 acme.sh 实现了 acme 协议, 可以从 letsencrypt 生成免费的证书. ...
- 字符串反码A
while True: try: string=input() if string!="!": res="" for i in string: if i.isu ...
- cmd常用命令介绍
一.cdm命令介绍:CMD命令是一种命令提示符,CMD是command的缩写,即命令提示符(CMD),位于C:\Windows\System32的目录下,是在OS/2,Win为基础的操作系统(包括Wi ...
- docker搭建个人云盘可道云kodbox
1.拉取kodbox镜像 (文章最后有自己编写yml文件可直接搭建) docker pull tznb/kodbox:1.15 2. 创建并启动kodbox docker run -d -it --n ...
- MergeOption.NoTracking的使用
前两天项目维护出现一个bug,报错信息是提交出错:AcceptChanges 无法继续,因为该对象的键值与 ObjectStateManager 中的另一个对象冲突.请在调用 AcceptChange ...
- 关于click和onclick的区别
click()和onclick()的区别: 1.onclick是绑定事件,告诉浏览器在鼠标点击时候要做什么 click本身是方法作用是触发onclick事件,只要执行了元素的click()方法,就会触 ...
- 斗鱼 H5 直播原理解析,它是如何省了 80% 的 CDN 流量?
斗鱼直播相信大家都听说过,打开斗鱼官网就可以直接在浏览器中观看直播.那么斗鱼是如何实现浏览器视频直播的呢?本篇文章就来解析斗鱼是如何实现直播的,以及它是如何节省 80% 的 CDN 流量,要知道视频直 ...
- 知识图谱-生物信息学-医学顶刊论文(Briefings in Bioinformatics-2021):生物信息学中的图表示学习:趋势、方法和应用
4.(2021.6.24)Briefings-生物信息学中的图表示学习:趋势.方法和应用 论文标题: Graph representation learning in bioinformatics: ...
- 【UML】统一建模语言
如果是准备学习设计模式的同学,可以只了解类图相关的知识 而如果是在准备软件设计师考试的同学,或许会对你有点帮助 正在施工...... 参考博客:https://blog.csdn.net/unique ...
- wpf下的图片放大缩小
WPF下实现图片的放大缩小移动 在windows 7里面有自带的图片查看器,这个软件可以打开一张图片然后以鼠标在图片中的焦点为原点来进行缩放,并且放大后可以随意拖动.下面我们在WPF中实现这个功能 ...