如何用WebGPU流畅渲染千万级2D物体:基于光追管线
大家好~我们已经实现了百万级2D物体的流畅渲染,不过是基于计算管线实现的。本文在它的基础上,改为基于光追管线实现,主要进行了CPU和GPU端内存的优化,成功地将渲染的2D物体数量由4百万提高到了2千万
相关文章如下:
如何用WebGPU流畅渲染百万级2D物体?
本文不需要实现构建和遍历BVH,而是直接使用光追管线提供的加速结构
本文的重点工作在于对CPU内存和GPU内存的优化,突破内存限制(如突破加速结构最大大小限制),使其支持千万级物体的数据
本文使用WebGPU Node项目,作者的介绍在这里。它在底层封装了Vulkan SDK,在上层提供了WebGPU API,实现了在Nodejs环境中使用WebGPU API和光追管线来实现硬件加速的光线追踪(需要使用nvdia的RTX显卡)!
我在2020年就已经基于该项目实现了3D场景渲染,相关介绍如下:
WebGPU+光线追踪Ray Tracing 开发三个月总结
需求
跟百万级的Demo的需求是一样的,除了提高渲染的2D物体数量到千万级,目的是为了探索基于硬件的光追管线的实现能带来的优化极限
成果
我们最终能够流畅渲染2千万个圆环
性能指标:
- 跟百万级的Demo的FPS一样,为45左右,也就是每帧花费21毫秒
硬件:
- Win10操作系统
- Nodejs环境+Vulkan驱动
- RTX2060s显卡
跟百万级Demo的性能比较
提高的地方:
- 渲染的物体数量多了4倍
降低的地方:
- 构造加速结构的时间多了1.5倍
不过相信随着RTX显卡的升级,会越来越快
下面让我们从0开始,介绍实现和优化的步骤:
1、选择渲染的算法
跟百万级的Demo一样,选择光线追踪算法
不过这里需要发送Primary Ray去计算射线与物体的相交,这样才能触发光追管线中关于相交的着色器
2、实现内存需求
跟百万级的Demo一样,场景依然使用ECS架构
3、渲染1个圆环
光追管线支持两种geometry的类型:
三角形和AABB包围盒
因为圆环是参数化的(参数化为圆点坐标、半径、圆环宽度),所以geometry类型使用AABB包围盒
这种类型geometry被称为“Procedural Geometry”
光追管线的加速结构跟百万级Demo的TopLevel、BottomLevel类似,分为TLAS(top level acceleration structure)和BLAS(bottom level acceleration structure),如下图所示:
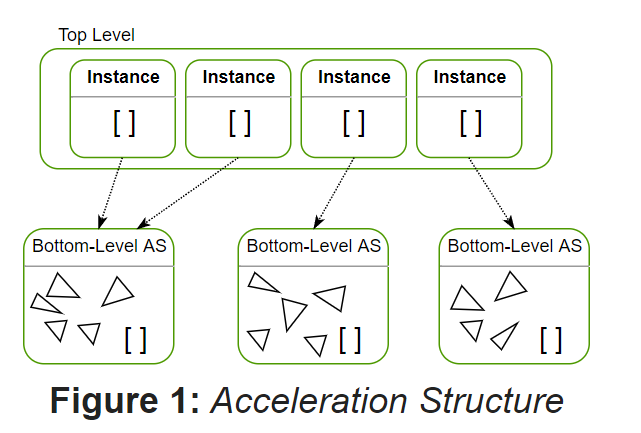
因为场景只有1个Geometry和1个Instance,所以在BLAS中加入1个aabb(根据Geometry的参数计算aabb,其中aabb的min.z和max.z设为0),在TLAS中加入1个Instance的数据(主要包括该圆环的transform matrix、instanceId)
现在介绍下光追管线通常包含哪些着色器:
- .rgen
每个像素会执行一次着色器,分别产生一条Primary Ray - .rint
该着色器用于AABB包围盒的geometry类型,当Primary Ray与AABB相交时被触发 - .rchit
该着色器用来处理Primary Ray与第一个圆环相交的情况 - .rmiss
该着色器用来处理Primary Ray与所有圆环都没有相交的情况 - rahit
Primary Ray与第一个圆环相交后继续传播,当与第二个及以后的圆环相交时触发该着色器(本Demo没用到该着色器)
渲染的步骤为:
1、在.rgen着色器中逐个像素产生Primary Ray
2、如果Primary Ray与AABB相交,则执行.rint着色器;否则执行.rmiss着色器,将像素设置为黑色
在执行.rint着色器时:
- 根据gl_LaunchIDEXT、gl_LaunchSizeEXT得到像素坐标,即为Primary Ray与AABB的相交点
- 如果该像素坐标在圆环内,则通过reportIntersectionEXT来触发.rchit着色器
在执行.rchit着色器时:
- 根据material设置像素颜色(为红色)
关于Procedural Geometry渲染的参考资料如下:
Vulkan->Intersection Shader - Tutorial
D3D12 Raytracing Procedural Geometry sample
4、渲染10个圆环
场景中创建10个圆环,它们的ECS数据为:
10个gameObject
10个transform
1个geometry
1个material
geometry仍然只有1个,但instance变为10个,所以在TLAS中改为加入10个Instance的数据,BLAS不变
渲染结果如下图所示:

5、显示FPS
我们使用“平均采样法”来计算FPS。这个方法跟我之前实现的深度学习->优化算法->动量法->指数加权移动平均类似,并且那里还做了数学证明。
这个方法的基本思想就是计算多个相邻帧的平均值,但又不需要额外的空间来保存多帧
参考资料如下:
帧率(FPS)计算的六种方法总结
6、实现剔除
实现思路如下:
将TLAS中每个instance的层设为transform matrix中的position.z;
将Primary Ray的flag设为gl_RayFlagsOpaqueEXT,这样的话Primary Ray与最大层的圆环相交时会触发.rchit着色器,然后就停止传播,从而实现只渲染最大层的圆环
注:这里的层不再是从1开始的正整数,而是为0.00001, 0.00002这样的小数。这是因为为了性能考虑,将Primary Ray的最大距离设为一个很小的值(如1.0),所以层的值不能超过1.0
7、测试渲染极限
当尝试跟百万级Demo一样渲染4百万个圆环时,报了下面的错误:
Error: Out of memory Error: vkAllocateMemory failed with VK_ERROR_OUT_OF_DEVICE_MEMORY
这是因为WebGPU Node项目底层使用Vulkan来渲染,它申请的单个TLAS的内存容纳不了4百万个instance数据
所以我们减少圆环数量,发现当其为3百50万个时,能够成功渲染。其中构造加速结构的时间为25秒,FPS为1000(因为这里使用setInterval而不是requestAnimationFrame启动主循环,所以FPS可以大于60)
8、拆分加速结构
如果要渲染4百万个甚至更多的圆环,就需要将1个TLAS拆成多个TLAS(BLAS还是不变,只有一个)
这样的话,如果每个TLAS都有3百50万个Instance数据,那么3个TLAS就可以有超过1千万个Instance数据了
如何拆分TLAS呢?
首先,我们可以根据Instance的层,按照下面的方法将所有Instance分为3组:
- 每组有最小层和最大层这两个数据,将层在其中的Instance放在该组中
- 每组按照层的大小从大到小排列,使得下一组的最大层小于等于上一组的最小层
然后,将每组的Instance数据分别传入1个TLAS中;
然后,创建3个bindGroup,每个bindGroup分别使用1个TLAS;
最后,在begin ray tracing pass时,绑定对应的bindGroup,traceRays3次,代码如下:
...
let commandEncoder = device.createCommandEncoder({});
let passEncoder = commandEncoder.beginRayTracingPass({});
passEncoder.setPipeline(pipeline);
bindGroups.forEach(bindGroup => {
passEncoder.setBindGroup(0, bindGroup);
passEncoder.traceRays(
0, // sbt ray-generation offset
1, // sbt ray-hit offset
2, // sbt ray-miss offset
window.width, // query width dimension
window.height, // query height dimension
1 // query depth dimension
);
})
passEncoder.endPass();
queue.submit([commandEncoder.finish()]);
这里我们先对层最大的一组Instance做遍历,然后再对层小一点的一组Instance做遍历,然后再对层更小一点的一组Instance做遍历。。。。。。
这是一个优化的方法,因为每个像素只渲染最大层的圆环的颜色,所以如果在遍历1个TLAS时Primary Ray与圆环相交而得到了像素的颜色,那么就不再对后面的TLAS进行遍历了!
9、拆分Instance Buffer
Instance Buffer存储了所有Instance的组件数据,是一个storage buffer。当Instance的数量大于1千万后,它的大小会超过buffer的最大大小:128MB,会报错
所以,跟拆分加速结构TLAS一样,我们把Instance Buffer也对应拆分,使得3个bindGroup分别使用1个TLAS和1个Instance Buffer
10、优化CPU端的内存占用
之前是在优化GPU端的内存占用,现在要优化CPU端的内存占用
当Instance数量超过1千6百万时,在CPU端设置TLAS的instances数据时会超出内存大小,报下面的错误:
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
现在的实现思路为:
我们有5组Instance,对应5个TLAS,每个TLAS最多有3百50万个Instance
首先现在创建了5个数组,每个数组最多保存3百50万个Instance数据;
然后将对应的数组设置为对应的TLAS的instances数据
因为这5个数组共包含了1千6百万个Instance数据,超出了CPU端v8的内存限制,所以会报错
可以做下面两个优化来解决问题:
- 因为每个数组的最大容量都是一样的(3百50万),所以只创建1个容量为3百50万的数组,通过"arr[index]=instance数据"来保存一个组的Instance数据,然后将其设置给对应的TLAS;然后重复使用该数组,保存下一组的Instance数据,将其设置给对应的TLAS,依次类推。。。。。。
经过这样的优化, CPU端就只需要分配3百50万个Instance数据的内存了,大大减少了内存占用 - 使用ArrayBuffer而不是数组来存储每组的Instance数据,这样可以提高速度并且减少内存占用
11、测试渲染极限
现在我们来渲染2千万个圆环,测试下FPS
渲染结果如下图所示:

性能指标如下:
- FPS为1000以上
- 构造加速结构的时间为150秒
为什么FPS跟渲染3百50万个圆环时一样?
因为第一个TLAS包含的3百50万个圆环为最高层,它们已经填满了屏幕,所以遍历第一个TLAS后就停止遍历了!
我们希望测试下最坏的情况,所以强制遍历所有的TLAS,此时FPS为45左右
当我们尝试渲染大于2千万个圆环时,报了下面的错误:
Error: Out of memory Error: vkAllocateMemory failed with VK_ERROR_OUT_OF_DEVICE_MEMORY
这说明虽然每个TLAS没有超过最大限制(3百50万个Instance数据),但是应该是超过了总的大小限制,也就是所有TLAS包含的总的Instance数据(大于2千万个)超过了限制!
除非能够修改WebGPU Node项目中的Vulkan关于TLAS内存分配的代码,否则我们通过WebGPU API无法修改该限制(因为WebGPU Node没有提供相关的WebGPU API)
12、尝试优化构造加速结构
在创建BLAS和TLAS时,可以指定为下面几个flag:
NONE
ALLOW_UPDATE
PREFER_FAST_TRACE
PREFER_FAST_BUILD
LOW_MEMORY
当修改为PREFER_FAST_BUILD而不是PREFER_FAST_TRACE,并没有效果!不知道是因为WebGPU Node在Vulkan这层没有处理这个flag还是显卡RTX2060s不支持这个flag?
其它的优化思路包括:
- 不需要一次性构造所有TLAS,而是按需构造对应的TLAS
- 在worker中构造TLAS和BLAS,使其不阻塞主线程
目前虽然构造加速结构比较慢,但随着RTX显卡的升级,相信会有改善!毕竟这个是由显卡完成的,我们这边能优化的余地较小
更多分析
我们来分析下面几个情况:
为什么“增大圆环geometry的半径,FPS会明显下降”?
这是因为:
这会增大圆环的AABB->增加重叠的AABB数量->增大遍历的开销->最终降低FPS
如果BLAS加入两个圆环的AABB,是否就能渲染4千万个圆环了?
这样是可以的。之前实现的渲染是渲染2千万个Instance,而每个Instance对应的BLAS只有一个圆环,所以就只渲染了2千万个圆环。
实际上可以像这样增加渲染的圆环数量,但是因为总的AABB的数量增加了一倍,导致遍历开销增大一倍,所以FPS也会下降一倍
能不能在相邻的两帧分别绘制不同的2千万个Instance,这样就可以渲染4千万个Instance了?
这样子的话不仅FPS会下降一倍,而且也是不可行的,因为不管分成几次draw call,都需要把所有Instance数据载入到TLAS中(因为所有的Instance数据只创建一次,除非每帧都创建对应的Instance数据并且把之前的Instance数据销毁!但这样的话CG开销应该会比较大),这样所有的TLAS包含的Instance数据大小一样不能超过2千万个
可以在相邻的两帧分别绘制不同的1千万个Instance,但这样还不如在一帧中绘制2千万个Instance省事
总结
感谢大家的支持和学习~
本文主要使用光追管线,优化了内存占用,将2D物体数量提升到了千万级
使用光追管线相比使用计算管线的优点是:
- 不需要实现BVH,实现和维护更加简单
- 因为是硬件加速射线相交计算,遍历的性能更好
缺点是:
- 兼容性更差
需要Nodejs环境和RTX显卡 - 不能使用最新的WebGPU标准
WebGPU Node项目使用的是2020年版本的WebGPU标准,不是最新的标准
所以,我们可以考虑在Web版产品中使用浏览器的WebGPU标准(基于计算管线)来实现,而在桌面版产品中基于光追管线来实现
后续的改进方向
目前已达到加速结构的内存限制(2千万个Instance),不容易继续增加Instance数量
后面可以考虑优化基于计算管线的Demo,从百万级提升到千万级;
另外可以考虑GPU LOD,在计算着色器中替换geometry,从而减少BLAS的占用
参考资料
如何用WebGPU流畅渲染百万级2D物体?
WebGPU+光线追踪Ray Tracing 开发三个月总结
Vulkan->Intersection Shader - Tutorial
帧率(FPS)计算的六种方法总结
WebGPU Ray-Tracing Spec
GLSL_NV_ray_tracing
Node.js heap out of memory
Node.js Default Memory Settings
如何用WebGPU流畅渲染千万级2D物体:基于光追管线的更多相关文章
- 如何用WebGPU流畅渲染百万级2D物体?
大家好~本文使用WebGPU和光线追踪算法,从0开始实现和逐步优化Demo,展示了从渲染500个2D物体都吃力到流畅渲染4百万个2D物体的优化过程和思路 目录 需求 成果 1.选择渲染的算法 2.实现 ...
- 千万级SQL Server数据库表分区的实现
千万级SQL Server数据库表分区的实现 2010-09-10 13:37 佚名 数据库 字号:T | T 一般在千万级的数据压力下,分区是一种比较好的提升性能方法.本文将介绍SQL Server ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 一次千万级别的SQL查询简单优化体验
背景:从两张有关联的表查询数据,A表数据量1400万,B表数据量8000万.A与B通过ID逻辑关联,没有实际的外键.B表是后来扩展出来的. 问题:根据某个ID查询时超时,运行时跑不出结果. 原因:使用 ...
- 在mysql数据库中制作千万级测试表
在mysql数据库中制作千万级测试表 前言: 最近准备深入的学一下mysql,包括各种引擎的特性.性能优化.分表分库等.为了方便测试性能.分表等工作,就需要先建立一张比较大的数据表.我这里准备先建一张 ...
- 单机千万级MQTT连接服务器测试报告
目标:测试创建1000万客户端连接到服务器端,服务器操作系统 Linux(任意一款发行版服务器版本).分别在两台硬件一样的服务器,其中一台用于服务器端运行,另一台用于创建千万客户端连接客户端机器.在硬 ...
- dotnet core使用IO合并技巧轻松实现千万级消息推送
之前讲述过多路复用实现单服百万级别RPS吞吐,但在文中有一点是没有说的就是消息IO合并,如果缺少了消息IO合并即使怎样多路复用也很难达到百万级别的请求响毕竟所有应用层面的网络IO读写都是非常损耗性能的 ...
- mysql循环插入千万级数据
mysql使用存储过程循环插入大量数据,简单的一条条循环插入,效率会很低,需要考虑批量插入. 测试准备: 1.建表: CREATE TABLE `mysql_genarate` ( `id` ) NO ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
随机推荐
- hexo + typora 图片插入解决办法
Typora 是一款知名的 Markdown 编辑器,简单好用,体验良好.使用 hexo 搭建好博客后,主要是用 Markdown 来编写博客,typora 便是我的首选编辑器.但直接使用 typor ...
- 深度学习可视化工具--tensorboard的使用
tensorboard的使用 官方文档 # writer.add_scalar() # 添加标量 """ Args: tag (string): Data identif ...
- nginx https证书配置
1. Nginx配置 server { listen 443; #指定ssl监听端口 server_name www.example.com; ssl on; #开启ssl支持 ssl_certifi ...
- Idea创建文件夹自动合成一个
在idea中创建文件夹时,它们总是自动合成一个,如下图: 文件夹自动折叠真的很影响效率,可能会引发一些不经意的失误 解决方法: 取消这个地方的勾选 这样就可以正常创建文件夹了
- SAP OOALV 添加状态灯
*&---------------------------------------------------------------------* INCLUDE <icon>. T ...
- bat-进程与服务
进程 tasklist 查看进程表 关闭进程 taskkill /PID xxx taskkill -f -im unm* taskkill -f -im ice* 服务 **net** net命令不 ...
- jenkins页面一直在Please wait while Jenkins is getting ready to work ...
原因:因为访问官网太慢.我们只需要换一个源,不使用官网的源即可. 1.找到jenkins工作目录 find / -name *.UpdateCenter.xml 2.修改文件中的url,随后重启就行了 ...
- 攻防世界pwn题:Recho
0x00:查看文件信息 一个64位二进制文件,canary和PIE保护机制没开. 0x01:用IDA进行静态分析 分析:主程序部分是一个while循环,判断条件是read返回值大于0则循环.函数ato ...
- Tapdata 等40余家行业知名企业,应邀参与共建 NextArch Foundation
日前,Linux 基金会执行董事 Jim Zemlin 于 Linux 基金会会员峰会(The Linux Foundation Member Summit)上宣布,Linux 基金会正式成立 N ...
- java-Stream的总结
JAVA中的Stream 01.什么是Stream Stream是JDK8中引入,Stream是一个来自数据源的元素序列并支持聚合操作.可以让你以一种声明的方式处理数据,Stream 使用一种类似用 ...