netty系列之:HashedWheelTimer一种定时器的高效实现
简介
定时器是一种在实际的应用中非常常见和有效的一种工具,其原理就是把要执行的任务按照执行时间的顺序进行排序,然后在特定的时间进行执行。JAVA提供了java.util.Timer和java.util.concurrent.ScheduledThreadPoolExecutor等多种Timer工具,但是这些工具在执行效率上面还是有些缺陷,于是netty提供了HashedWheelTimer,一个优化的Timer类。
一起来看看netty的Timer有何不同吧。
java.util.Timer
Timer是JAVA在1.3中引入的。所有的任务都存储在它里面的TaskQueue中:
private final TaskQueue queue = new TaskQueue();
TaskQueue的底层是一个TimerTask的数组,用于存储要执行的任务。
private TimerTask[] queue = new TimerTask[128];
看起来TimerTask只是一个数组,但是Timer将这个queue做成了一个平衡二叉堆。
当添加一个TimerTask的时候,会插入到Queue的最后面,然后调用fixup方法进行再平衡:
void add(TimerTask task) {
// Grow backing store if necessary
if (size + 1 == queue.length)
queue = Arrays.copyOf(queue, 2*queue.length);
queue[++size] = task;
fixUp(size);
}
当从heap中移出运行的任务时候,会调用fixDown方法进行再平衡:
void removeMin() {
queue[1] = queue[size];
queue[size--] = null; // Drop extra reference to prevent memory leak
fixDown(1);
}
fixup的原理就是将当前的节点和它的父节点进行比较,如果小于父节点就和父节点进行交互,然后遍历进行这个过程:
private void fixUp(int k) {
while (k > 1) {
int j = k >> 1;
if (queue[j].nextExecutionTime <= queue[k].nextExecutionTime)
break;
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}
fixDown的原理是比较当前节点和它的子节点,如果当前节点大于子节点,则将其降级:
private void fixDown(int k) {
int j;
while ((j = k << 1) <= size && j > 0) {
if (j < size &&
queue[j].nextExecutionTime > queue[j+1].nextExecutionTime)
j++; // j indexes smallest kid
if (queue[k].nextExecutionTime <= queue[j].nextExecutionTime)
break;
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}
二叉平衡堆的算法这里不做详细的介绍。大家可以自行查找相关的文章。
java.util.concurrent.ScheduledThreadPoolExecutor
虽然Timer已经很好用了,并且是线程安全的,但是对于Timer来说,想要提交任务的话需要创建一个TimerTask类,用来封装具体的任务,不是很通用。
所以JDK在5.0中引入了一个更加通用的ScheduledThreadPoolExecutor,这是一个线程池使用多线程来执行具体的任务。当线程池中的线程个数等于1的时候,ScheduledThreadPoolExecutor就等同于Timer。
ScheduledThreadPoolExecutor中进行任务保存的是一个DelayedWorkQueue。
DelayedWorkQueue和DelayQueue,PriorityQueue一样都是一个基于堆的数据结构。
因为堆需要不断的进行siftUp和siftDown再平衡操作,所以它的时间复杂度是O(log n)。
下面是DelayedWorkQueue的shiftUp和siftDown的实现代码:
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
private void siftDown(int k, RunnableScheduledFuture<?> key) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
RunnableScheduledFuture<?> c = queue[child];
int right = child + 1;
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
if (key.compareTo(c) <= 0)
break;
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
HashedWheelTimer
因为Timer和ScheduledThreadPoolExecutor底层都是基于堆结构的。虽然ScheduledThreadPoolExecutor对Timer进行了改进,但是他们两个的效率是差不多的。
那么有没有更加高效的方法呢?比如O(1)是不是可以达到呢?
我们知道Hash可以实现高效的O(1)查找,想象一下假如我们有一个无限刻度的钟表,然后把要执行的任务按照间隔时间长短的顺序分配到这些刻度中,每当钟表移动一个刻度,即可以执行这个刻度中对应的任务,如下图所示:
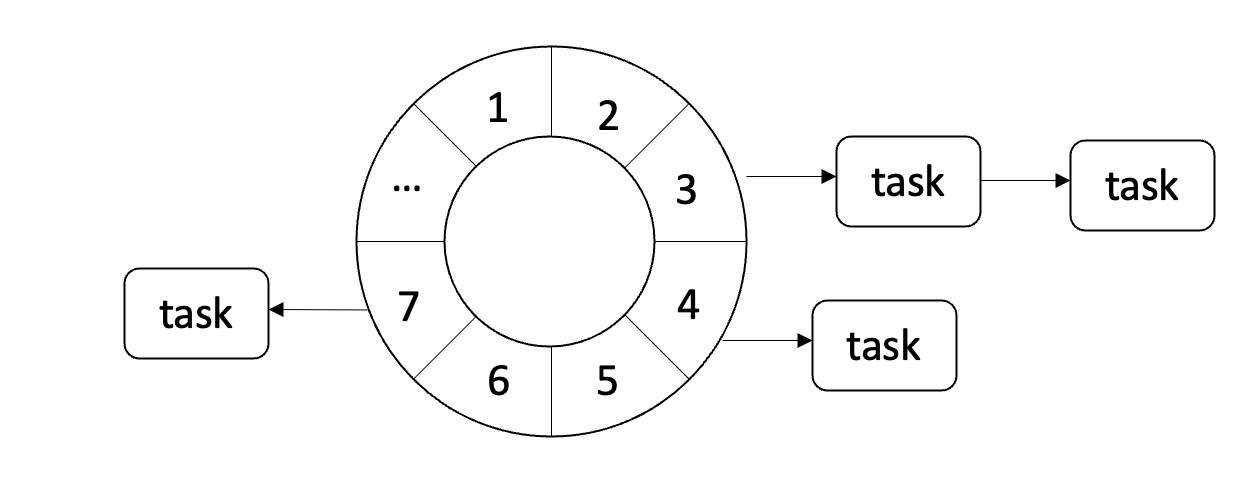
这种算法叫做Simple Timing Wheel算法。
但是这种算法是理论上的算法,因为不可能为所有的间隔长度都分配对应的刻度。这样会耗费大量的无效内存空间。
所以我们可以做个折中方案,将间隔时间的长度先用hash进行处理。这样就可以缩短间隔时间的基数,如下图所示:
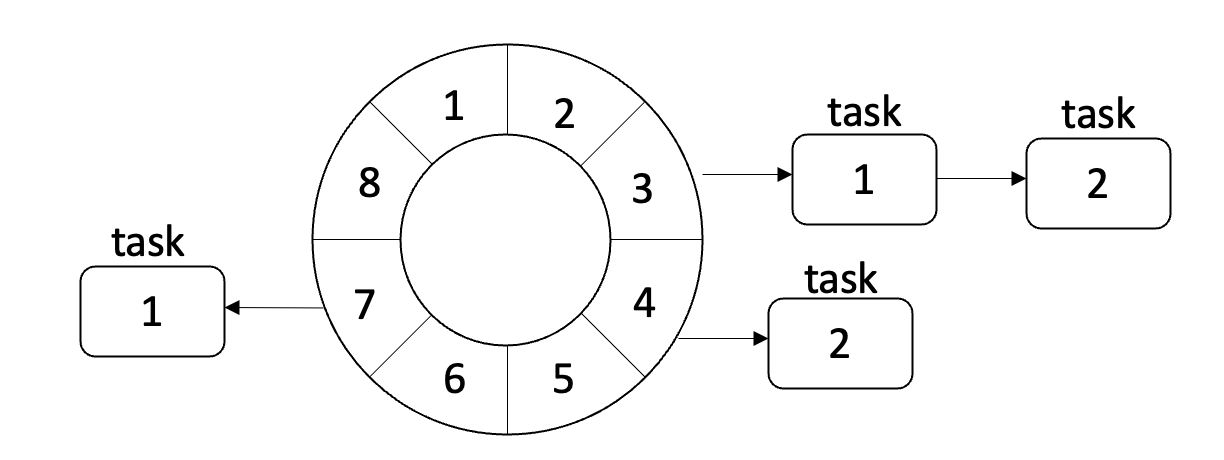
这个例子中,我们选择8作为基数,间隔时间除以8,余数作为hash的位置,商作为节点的值。
每次遍历轮询的时候,将节点的值减一。当节点的值为0的时候,就表示该节点可以取出执行了。
这种算法就叫做HashedWheelTimer。
netty提供了这种算法的实现:
public class HashedWheelTimer implements Timer
HashedWheelTimer使用HashedWheelBucket数组来存储具体的TimerTask:
private final HashedWheelBucket[] wheel;
首先来看下创建wheel的方法:
private static HashedWheelBucket[] createWheel(int ticksPerWheel) {
//ticksPerWheel may not be greater than 2^30
checkInRange(ticksPerWheel, 1, 1073741824, "ticksPerWheel");
ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);
HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];
for (int i = 0; i < wheel.length; i ++) {
wheel[i] = new HashedWheelBucket();
}
return wheel;
}
我们可以自定义wheel中ticks的大小,但是ticksPerWheel不能超过2^30。
然后将ticksPerWheel的数值进行调整,到2的整数倍。
然后创建ticksPerWheel个元素的HashedWheelBucket数组。
这里要注意,虽然整体的wheel是一个hash结构,但是wheel中的每个元素,也就是HashedWheelBucket是一个链式结构。
HashedWheelBucket中的每个元素都是一个HashedWheelTimeout. HashedWheelTimeout中有一个remainingRounds属性用来记录这个Timeout元素还会在Bucket中保存多久。
long remainingRounds;
总结
netty中的HashedWheelTimer可以实现更高效的Timer功能,大家用起来吧。
更多内容请参考 http://www.flydean.com/50-netty-hashed-wheel-timer/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
netty系列之:HashedWheelTimer一种定时器的高效实现的更多相关文章
- 2. 彤哥说netty系列之IO的五种模型
你好,我是彤哥,本篇是netty系列的第二篇. 欢迎来我的公从号彤哥读源码系统地学习源码&架构的知识. 简介 本文将介绍linux中的五种IO模型,同时也会介绍阻塞/非阻塞与同步/异步的区别. ...
- Netty系列(四)TCP拆包和粘包
Netty系列(四)TCP拆包和粘包 一.拆包和粘包问题 (1) 一个小的Socket Buffer问题 在基于流的传输里比如 TCP/IP,接收到的数据会先被存储到一个 socket 接收缓冲里.不 ...
- 【读后感】Netty 系列之 Netty 高性能之道 - 相比 Mina 怎样 ?
[读后感]Netty 系列之 Netty 高性能之道 - 相比 Mina 怎样 ? 太阳火神的漂亮人生 (http://blog.csdn.net/opengl_es) 本文遵循"署名-非商 ...
- 1. 彤哥说netty系列之开篇(有个问卷调查)
你好,我是彤哥,本篇是netty系列的第一篇. 欢迎来我的公从号彤哥读源码系统地学习源码&架构的知识. 简介 本文主要讲述netty系列的整体规划,并调查一下大家喜欢的学习方式. 知识点 ne ...
- 3. 彤哥说netty系列之Java BIO NIO AIO进化史
你好,我是彤哥,本篇是netty系列的第三篇. 欢迎来我的公从号彤哥读源码系统地学习源码&架构的知识. 简介 上一章我们介绍了IO的五种模型,实际上Java只支持其中的三种,即BIO/NIO/ ...
- 5. 彤哥说netty系列之Java NIO核心组件之Channel
你好,我是彤哥,本篇是netty系列的第五篇. 简介 上一章我们一起学习了如何使用Java原生NIO实现群聊系统,这章我们一起来看看Java NIO的核心组件之一--Channel. 思维转变 首先, ...
- 6. 彤哥说netty系列之Java NIO核心组件之Buffer
--日拱一卒,不期而至! 你好,我是彤哥,本篇是netty系列的第六篇. 简介 上一章我们一起学习了Java NIO的核心组件Channel,它可以看作是实体与实体之间的连接,而且需要与Buffer交 ...
- 7. 彤哥说netty系列之Java NIO核心组件之Selector
--日拱一卒,不期而至! 你好,我是彤哥,本篇是netty系列的第七篇. 简介 上一章我们一起学习了Java NIO的核心组件Buffer,它通常跟Channel一起使用,但是它们在网络IO中又该如何 ...
- Netty 系列之 Netty 高性能之道 高性能的三个主题 Netty使得开发者能够轻松地接受大量打开的套接字 Java 序列化
Netty系列之Netty高性能之道 https://www.infoq.cn/article/netty-high-performance 李林锋 2014 年 5 月 29 日 话题:性能调优语言 ...
随机推荐
- Java实现单链表的合并(保证数据的有序性)
一.思路 1.比较两个链表的大小 2.将小链表插入到大链表中 3.使用插入保证链表数据的有序性 二.核心代码 /** * 合并两个链表,并且按照有序合并 * @param singleLinkedLi ...
- Java基础之详谈IO流
Java基础知识.IO流详细讲解.你所要的IO这里都有
- Gitlab图床配置
注意,使用图床,如果文件在外网打开,图片不会正常显示,因为图片存储在内部的Gitlab服务器上 自行搜索Picgo安装配置,需要安装node.js 项目链接:D-W-X/picgo-plugin- ...
- Ubu18.0-NVIDIA显卡驱动重装
//图片仅供参考,请勿代入 问题情况:电脑装了双系统,WIN10+Ubu,Ubu分辨率不稳定,经常发生变化 显卡型号:打开设备管理器进行查看 解决方法:重装NVIDIA显卡驱动 1.去英伟达官网下载自 ...
- HTML5有哪些新特性
(一) 语义标签 <header>表示页面中一个内容区块或整个页面的标题. <section>页面中的一个内容区块,如章节.页眉.页脚或页面的其他地方,可以和h1.h2--元 ...
- 《Streaming Systems》第二章: 数据处理中的 What, Where, When, How
本章中,我们将通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌. What:计算什么结果? 也就是我们进行数据处理的目的,答案是转换(transforma ...
- mask-image实现聚光灯效果
大家好,我是半夏,一个刚刚开始写文的沙雕程序员.如果喜欢我的文章,可以关注 点赞 加我微信:frontendpicker,一起学习交流前端,成为更优秀的工程师-关注公众号:搞前端的半夏,了解更多前端知 ...
- 【ACM程序设计】前缀和
前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和 作用: 一种预处理,求出的前缀和数组可以使得,输出原序列中从第l个数到第r个数和的时间复杂度变成了O(1) . 一维前缀和 ...
- 老生常谈系列之Aop--前言
老生常谈系列之Aop--前言 前言 既然是前言,那么这一篇就不会写具体的技术问题.这篇文章主要记录我一些个人的思考以及为什么要写文章的缘由.前不久在跟朋友的交流中偶然聊到了Aop,Aop全称为 Asp ...
- vue - Vue中的ajax
只有在ajax才能找回一点点主场了,vue中的ajax一天整完,内容还行,主要是对axios的运用. 明天按理说要开始vuex了,这个从来都是只耳闻没有眼见过,明天来看看看看是个什么神奇的东西. 一. ...