聊聊 Redis 是如何进行请求处理
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/674
本文使用的Redis 5.0源码
感觉这部分的代码还是挺有意思的,我尽量用比较通俗的方式进行讲解
概述
我记得我在 一文说透 Go 语言 HTTP 标准库 这篇文章里面解析了对于 Go 来说是如何创建一个 Server 端程序的:
- 首先是注册处理器;
- 开启循环监听端口,每监听到一个连接就会创建一个 Goroutine;
- 然后就是 Goroutine 里面会循环的等待接收请求数据,然后根据请求的地址去处理器路由表中匹配对应的处理器,然后将请求交给处理器处理;
用代码表示就是这样:
func (srv *Server) Serve(l net.Listener) error {
...
baseCtx := context.Background()
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
// 接收 listener 过来的网络连接
rw, err := l.Accept()
...
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew)
// 创建协程处理连接
go c.serve(connCtx)
}
}
对于 Redis 来说就有些不太一样,因为它是单线程的,无法使用多线程处理连接,所以 Redis 选择使用基于 Reactor 模式的事件驱动程序来实现事件的并发处理。
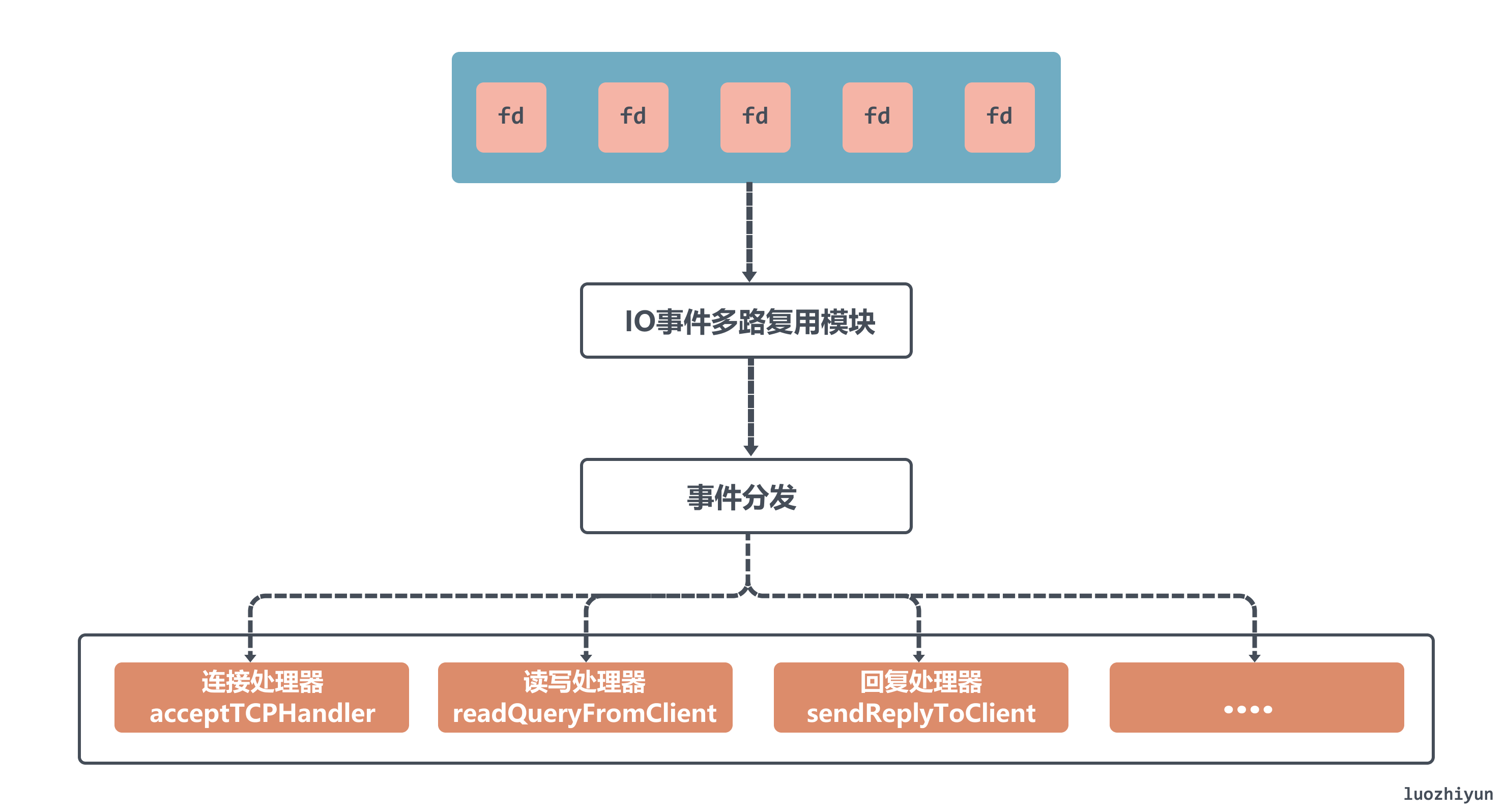
在 Redis 中所谓 Reactor 模式就是通过 epoll 来监听多个 fd,每当这些 fd 有响应的时候会以事件的形式通知 epoll 进行回调,每一个事件都有一个对应的事件处理器。
如: accept 对应 acceptTCPHandler 事件处理器、read & write 对应readQueryFromClient 事件处理器等,然后通过事件的循环派发的形式将事件分配给事件处理器进行处理。
所以说上面的这个 Reactor 模式都是通过 epoll 来实现的,对于 epoll 来说主要有这三个方法:
//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
int epoll_create(int size);
/*
* 可以理解为,增删改 fd 需要监听的事件
* epfd 是 epoll_create() 创建的句柄。
* op 表示 增删改
* epoll_event 表示需要监听的事件,Redis 只用到了可读,可写,错误,挂断 四个状态
*/
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/*
* 可以理解为查询符合条件的事件
* epfd 是 epoll_create() 创建的句柄。
* epoll_event 用来存放从内核得到事件的集合
* maxevents 获取的最大事件数
* timeout 等待超时时间
*/
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
所以我们可以根据这三个方法实现一个简单的 server:
// 创建监听
int listenfd = ::socket();
// 绑定ip和端口
int r = ::bind();
// 创建 epoll 实例
int epollfd = epoll_create(xxx);
// 添加epoll要监听的事件类型
int r = epoll_ctl(..., listenfd, ...);
struct epoll_event* alive_events = static_cast<epoll_event*>(calloc(kMaxEvents, sizeof(epoll_event)));
while (true) {
// 等待事件
int num = epoll_wait(epollfd, alive_events, kMaxEvents, kEpollWaitTime);
// 遍历事件,并进行事件处理
for (int i = 0; i < num; ++i) {
int fd = alive_events[i].data.fd;
// 获取事件
int events = alive_events[i].events;
// 进行事件的分发
if ( (events & EPOLLERR) || (events & EPOLLHUP) ) {
...
} else if (events & EPOLLRDHUP) {
...
}
...
}
}
调用流程
所以根据上面的介绍,可以知道对于 Redis 来说一个事件循环无非也就这么几步:
- 注册事件监听及回调函数;
- 循环等待获取事件并处理;
- 调用回调函数,处理数据逻辑;
- 回写数据给 Client;
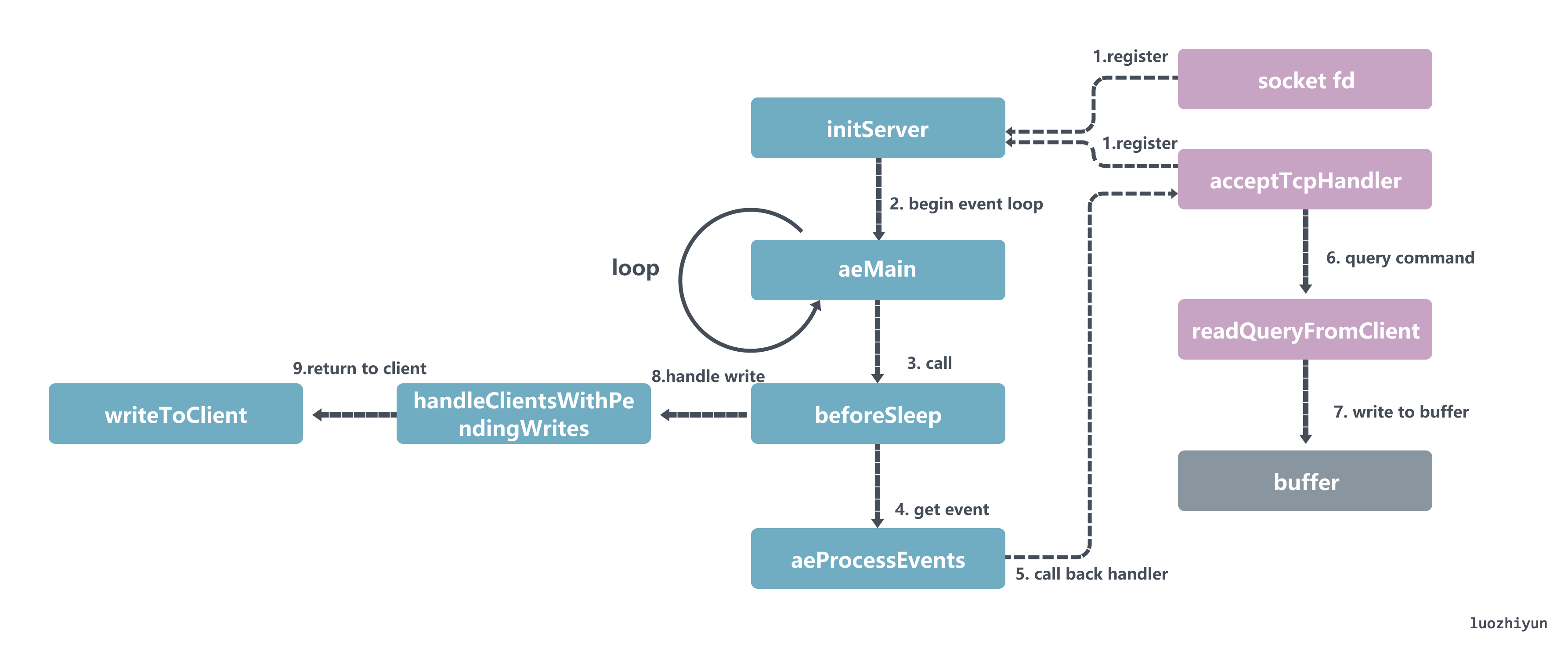
- 注册 fd 到 epoll 中,并设置回调函数 acceptTcpHandler,如果有新连接那么会调用回调函数;
- 启动一个死循环调用 epoll_wait 等待并持续处理事件,待会我们回到 aeMain 函数中循环调 aeProcessEvents 函数;
- 当有网络事件过来的时候,会顺着回调函数 acceptTcpHandler 一路调用到 readQueryFromClient 进行数据的处理,readQueryFromClient 会解析 client 的数据,找到对应的 cmd 函数执行;
- Redis 实例在收到客户端请求后,会在处理客户端命令后,将要返回的数据写入客户端输出缓冲区中而不是立马返回;
- 然后在 aeMain 函数每次循环时都会调用 beforeSleep 函数将缓冲区中的数据写回客户端;
上面的整个事件循环的过程实际上代码步骤已经写的非常清晰,网上也有很多文章介绍,我就不多讲了。
命令执行过程 & 回写客户端
命令执行
下面我们讲点网上很多文章都没提及的,看看 Redis 是如何执行命令,然后存入缓存,以及将数据从缓存写回 Client 这个过程。

在前一节我们也提到了,如果有网络事件过来的时候会调用到 readQueryFromClient 函数,它是真正执行命令的地方。我们也就顺着这个方法一直往下看:
- readQueryFromClient 里面会调用 processInputBufferAndReplicate 函数处理请求的命令;
- 在 processInputBufferAndReplicate 函数里面会调用 processInputBuffer 以及判断一下如果是集群模式的话,是否需要将命令复制给其他节点;
- processInputBuffer 函数里面会循环处理请求的命令,并根据请求的协议调用 processInlineBuffer 函数,将 redisObject 对象后调用 processCommand 执行命令;
- processCommand 在执行命令的时候会通过 lookupCommand 去
server.commands表中根据命令查找对应的执行函数,然后经过一系列的校验之后,调用相应的函数执行命令,调用 addReply 将要返回的数据写入客户端输出缓冲区;
server.commands会在 populateCommandTable 函数中将所有的 Redis 命令注册进去,作为一个根据命令名获取命令函数的表。
比如说,要执行 get 命令,那么会调用到 getCommand 函数:
void getCommand(client *c) {
getGenericCommand(c);
}
int getGenericCommand(client *c) {
robj *o;
// 查找数据
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)
return C_OK;
...
}
robj *lookupKeyReadOrReply(client *c, robj *key, robj *reply) {
//到db中查找数据
robj *o = lookupKeyRead(c->db, key);
// 写入到缓存中
if (!o) addReply(c,reply);
return o;
}
在 getCommand 函数中查找到数据,然后调用 addReply 将要返回的数据写入客户端输出缓冲区。
数据回写客户端
在上面执行完命令写入到缓冲区后,还需要从缓冲区取出数据返回给 Client。对于数据回写客户端这个流程来说,其实也是在服务端的事件循环中完成的。
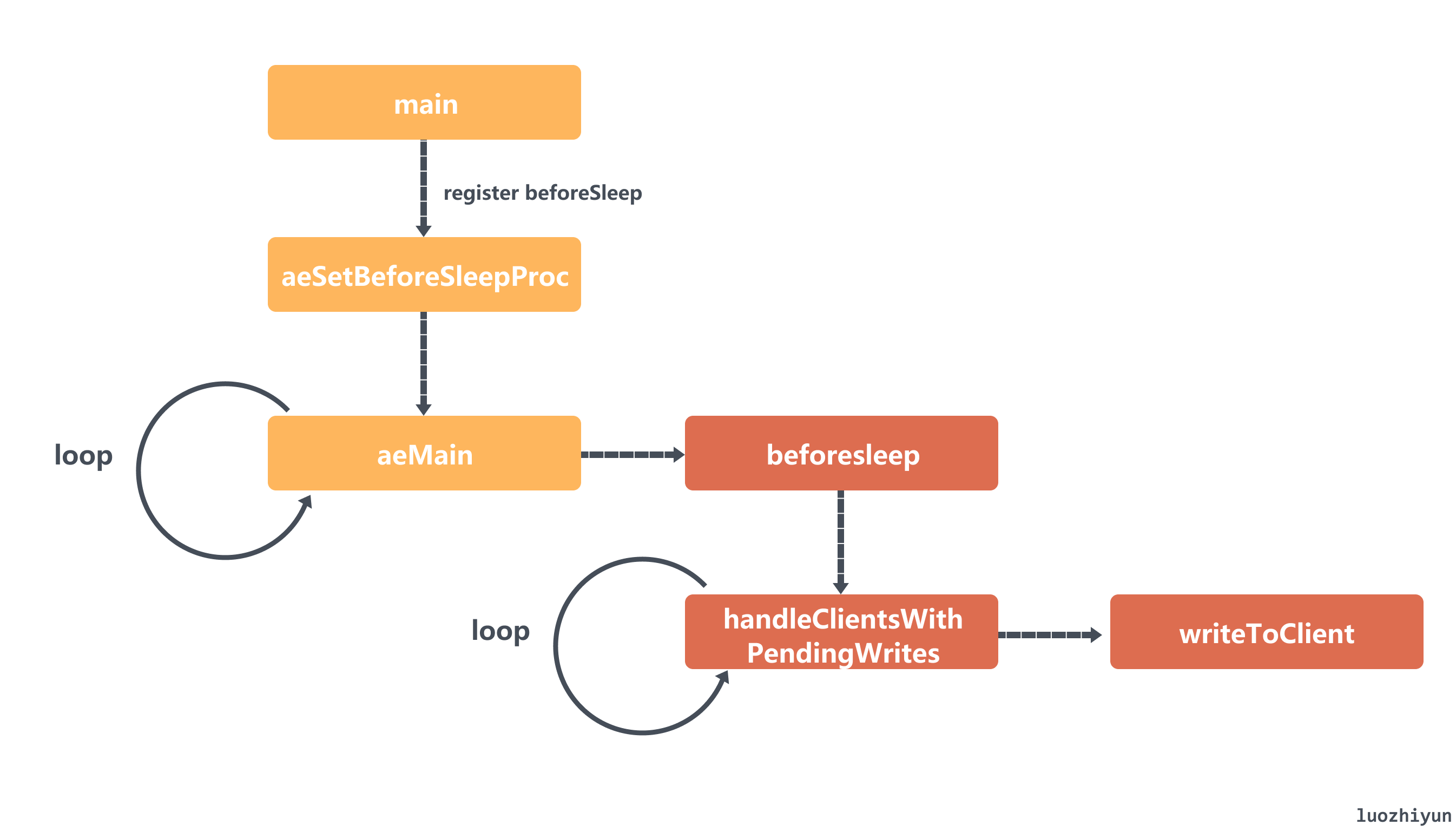
- 首先 Redis 会在 main 函数中调用 aeSetBeforeSleepProc 函数将回写包的函数 beforeSleep 注册到 eventLoop 中去;
- 然后 Redis 在调用 aeMain 函数进行事件循环的时候都会判断一下 beforesleep 有没有被设值,如果有,那么就会进行调用;
- beforesleep 函数里面会调用到 handleClientsWithPendingWrites 函数,它会调用 writeToClient 将数据从缓冲区中回写给客户端;
总结
这篇文章介绍了整个 Redis 的请求处理模型到底是怎样的。从注册监听 fd 事件到执行命令,到最后将数据回写给客户端都做了个大概的分析。当然这篇文章也和我以往的文章有点不同,没有长篇大论的贴代码,主要我觉得也没啥必要,感兴趣可以顺着流程图去看看代码。
Reference
http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf
https://time.geekbang.org/column/article/408491
http://remcarpediem.net/article/1aa2da89/
https://github.com/Junnplus/blog/issues/37
https://www.cnblogs.com/neooelric/p/9629948.html

聊聊 Redis 是如何进行请求处理的更多相关文章
- 聊聊redis实际运用及骚操作
前言 聊起 redis 咱们大部分后端猿应该都不陌生,或多或少都用过.甚至大部分前端猿都知道. 数据结构: string. hash. list. set (无序集合). setsorted(有序集合 ...
- 阿里面试官:HashMap 熟悉吧?好的,那就来聊聊 Redis 字典吧!
最近,小黑哥的一个朋友出去面试,回来跟小黑哥抱怨,面试官不按套路出牌,直接打乱了他的节奏. 事情是这样的,前面面试问了几个 Java 的相关问题,我朋友回答还不错,接下来面试官就问了一句:看来 Jav ...
- 聊聊redis的主从复制吧
聊聊基础概念 主从复制与主从替换 主从复制不同于主从替换,主从复制是正常情况下主节点同步数据到从节点:主从替换是主节点挂了之后,把从节点替换为主节点: 从节点存在的意义:备份主节点数据+负载均衡(对外 ...
- 服务端指南 数据存储篇 | 聊聊 Redis 使用场景(转)
作者:梁桂钊 本文,是升级版,补充部分实战案例.梳理几个场景下利用 Redis 的特性可以大大提高效率. 随着数据量的增长,MySQL 已经满足不了大型互联网类应用的需求.因此,Redis 基于内存存 ...
- java架构之路-(Redis专题)简单聊聊redis分布式锁
这次我们来简单说说分布式锁,我记得过去我也过一篇JMM的内存一致性算法,就是说拿到锁的可以继续操作,没拿到的自旋等待. 思路与场景 我们在Zookeeper中提到过分布式锁,这里我们先用redis实现 ...
- 聊聊redis的监控工具
序 本文主要研究一下redis的监控工具 redis-stat redis-stat是一个比较有名的redis指标可视化的监控工具,采用ruby开发,基于redis的info命令来统计,不影响redi ...
- 聊聊Redis的持久化
两种持久化策略 1.AOF:记录每一次的写操作到日志上,重启时重放日志以重建数据2.RDB:每隔一段时间保存一次当前时间点上的数据快照 快照就是一次又一次地从头开始创造一切3.可以关闭持久化4. ...
- 聊聊redis单线程为什么能做到高性能和io多路复用到底是个什么鬼
1:io多路复用epoll io多路复用简单来说就是一个线程处理多个网络请求 我们知道epoll in 的事件触发是可读了,这个比较好理解,比如一个连接过来,或者一个数据发送过来了,那么in事件就触 ...
- Redis - 2 - 聊聊Redis的RDB和AOF持久化 - 更新完毕
1.RDB 1.1).RDB是什么? RDB,全称Redis Database RDB是Redis进行持久化的一种方式,当然:Redis默认的持久化方式也是RDB 1.2).Redis配置RDB 1. ...
随机推荐
- 老生常谈系列之Aop--AspectJ
老生常谈系列之Aop--AspectJ 这篇文章的目的是大概讲解AspectJ是什么,所以这个文章会花比较长的篇幅去解释一些概念(这对于日常开发来说没一点卵用,但我就是想写),本文主要参考Aspect ...
- java实现空心金字塔
前言 最近在学习java,遇到了一个经典打印题目,空心金字塔,初学者记录,根据网上教程,有一句话感觉很好,就是先把麻烦的问题转换成很多的简单问题,最后一一解决就可以了,然后先死后活,先把程序写死,后面 ...
- 小数据池,is和==的区别,id()
小数据池 概念 存放数据缓存的地方 目的 节省内存,提高效率 什么数据会被缓存(什么数据会放在小数据池中) 数字 字符串 布尔 优点: 可以帮我们快速的创建对象.节省内存. 缺点: ...
- HCNP Routing&Switching之RSTP保护
前文我们了解了RSTP相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16240348.html:今天我们来聊一聊RSTP保护相关话题: 我们知道RST ...
- 使用WebDriverManager实现自动获取浏览器驱动程序
原理: 自动到指定的地址下载相应的浏览器驱动保存到缓存区 ~/.cache/selenium 痛点: 解决因Chrome浏览器升级,driver需要同步升级,要重新下载驱动的问题 区别: 传统方式 需 ...
- 羽夏 MakeFile 简明教程
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.该文章根据 GNU Make Manual 进行汉化处理并作出自己的整理,一是我对 Make 的学习记录,二是对大家学习 MakeF ...
- Svelte3.x网页聊天实例|svelte.js仿微信PC版聊天svelte-webchat
基于Svelte3+SvelteKit+Sass仿微信Mac界面聊天实战项目SvelteWebChat. 基于svelte3+svelteKit+sass+mescroll.js+svelte-lay ...
- Tmux常用命令总结
会话 # 创建会话 tmux new -s work -s是session # 查看tmux进程 ps aux | grep tmux # 连接会话 tmux attach -t work # 会话分 ...
- Python3 filter()函数和map()函数
filter(function or None,iterable) 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换. 该接收两个参数,第 ...
- Node.js精进(2)——异步编程
虽然 Node.js 是单线程的,但是在融合了libuv后,使其有能力非常简单地就构建出高性能和可扩展的网络应用程序. 下图是 Node.js 的简单架构图,基于 V8 和 libuv,其中 Node ...