云原生时代顶流消息中间件Apache Pulsar部署实操-上
@
安装
运行时Java版本推荐

Locally Standalone集群
启动
# 下载最新版本为2.11.0,需要Java 17
wget https://archive.apache.org/dist/pulsar/pulsar-2.11.0/apache-pulsar-2.11.0-bin.tar.gz
# 解压
tar xvfz apache-pulsar-2.11.0-bin.tar.gz
# 进入根目录
cd apache-pulsar-2.11.0
# 目录结构
ls -1F
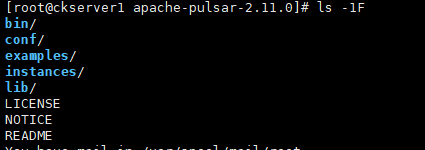
- bin:pulsar入口点脚本,以及许多其他命令行工具。
- conf:配置文件,包括pulsar示例pulsar函数示例实例使用的broker.conf
- examples:函数示例。
- lib:使用的jar。
- instances:函数的实例。
# 启动
bin/pulsar standalone
# 要将服务作为后台进程运行,可以使用下面命令
bin/pulsar -daemon start standalone
查看日志可以看到本地的pulsar standalone 集群启动成功日志
Pulsar集群启动时,会创建以下目录
- data:BookKeeper和RocksDB创建的所有数据。
- logs:所有服务日志。
公共/默认名称空间是在启动Pulsar集群时创建的。此名称空间用于开发目的。所有Pulsar主题都在名称空间中管理。
验证
- 创建主题
bin/pulsar-admin topics create persistent://public/default/test-topic1
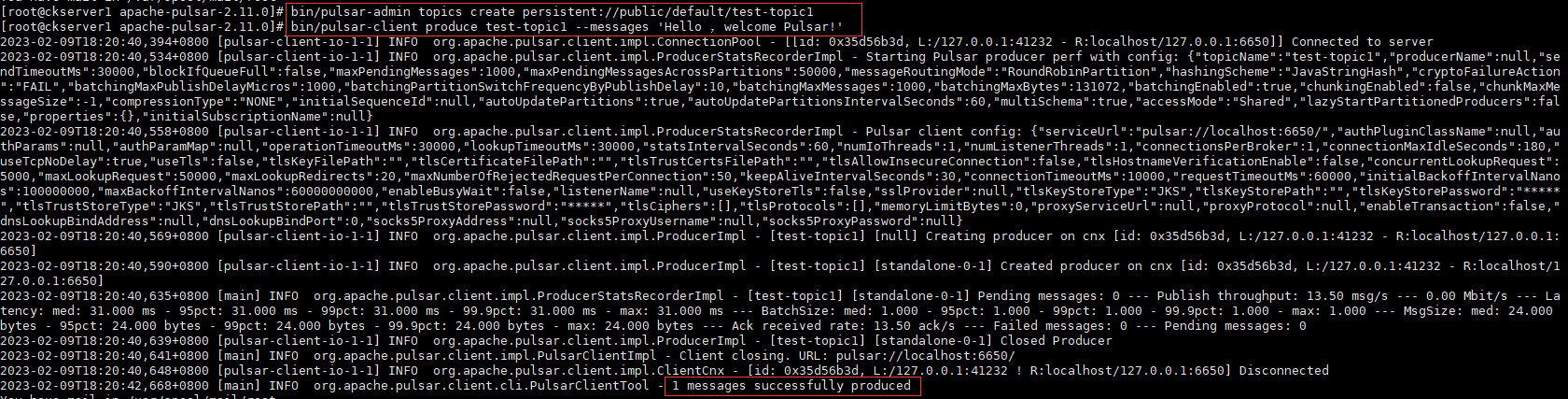
- 写入消息
bin/pulsar-client produce test-topic1 --messages 'Hello ,welcome Pulsar!'
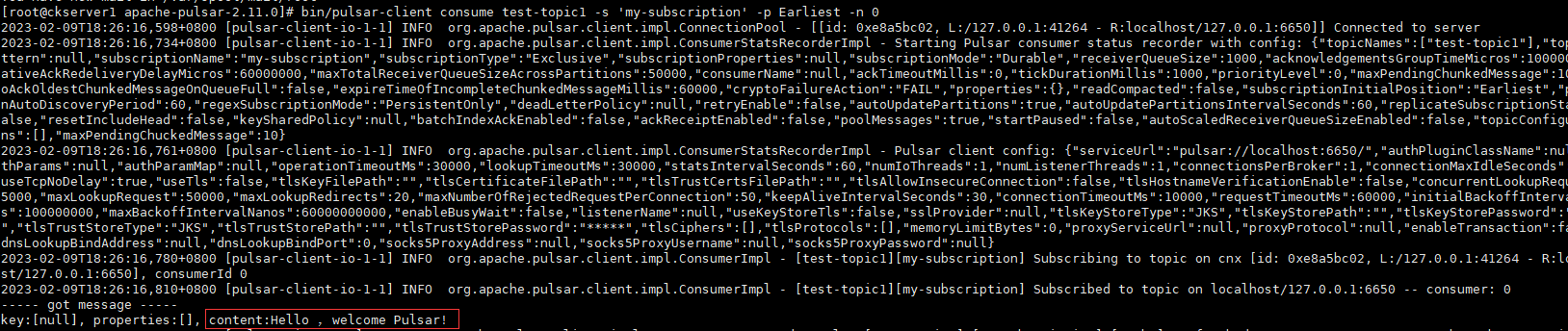
- 读消息
bin/pulsar-client consume test-topic1 -s 'my-subscription' -p Earliest -n 0
部署分布式集群
部署说明
这里使用Pulsar二进制包部署,不同于K8S部署集群,为了可以更好理解Pulsar架构。Pulsar实例由多个Pulsar 集群共同工作组成。可以跨数据中心或地理区域分布集群,并使用地理复制在它们之间复制集群。搭建Pulsar集群至少需要3个组件:ZooKeeper集群、BookKeeper集群、Broker集群。
- 3个节点ZooKeeper集群。建议生产部署两个独立的ZooKeeper集群,一个Local用于实例中的每个集群,另一个Configuration Store用于实例级任务。如果部署单集群实例,则不需要配置存储的单独集群。但如果部署了一个多集群实例,应该为配置任务建立一个单独的ZooKeeper集群。
- Local ZooKeeper运行在集群级别,提供特定于集群的配置管理和协调。每个Pulsar集群需要一个专用的ZooKeeper集群。
- Configuration Store在实例级上操作,并为整个系统(因此跨集群)提供配置管理。一个独立的机器集群或本地ZooKeeper使用的相同的机器可以提供配置存储仲裁。
- 3个节点BookKeeper集群。
- 3个节点Pulsar节点集群(Broker是Pulsar自身的实例)。
Pulsar的安装包已经包含搭建分布式集群所需的组件库,无需单独下载ZooKeeper和BookKeeper的安装包。但在实际中,zookeeper并不仅仅应用在pulsar上,之前介绍很多大数据组件依赖zookeeper,因此我们也使用外置的zookeeper环境。需要apache-zookeeper-3.8.0以上版本,我这里是apache-zookeeper-3.8.1。下面使用上面Standalone的下载的apache-pulsar-2.11.0-bin.tar.gz来部署分布式集群。
初始化集群元数据
只需要初始化一次接口,可以使用pulsar CLI工具的initialize-cluster-metadata命令初始化该元数据
bin/pulsar initialize-cluster-metadata \
--cluster pulsar-cluster \
--metadata-store zk1:2181,zk2:2181,zk3:2181 \
--configuration-metadata-store zk1:2181,zk2:2181,zk3:2181 \
--web-service-url http://hadoop1:8080/ \
--web-service-url-tls https://hadoop1:8443/ \
--broker-service-url pulsar://hadoop1:6650/ \
--broker-service-url-tls pulsar+ssl://hadoop1:6651/
bin/pulsar initialize-cluster-metadata \
--cluster pulsar-cluster \
--metadata-store hadoop1:2181 \
--configuration-metadata-store hadoop1:2181 \
--web-service-url http://hadoop1:8080/ \
--web-service-url-tls https://hadoop1:8443/ \
--broker-service-url pulsar://hadoop1:6650/ \
--broker-service-url-tls pulsar+ssl://hadoop1:6651/
初始化命令的参数说明
- 集群的名称
- 本地元数据存储集群的连接字符串
- 整个实例的配置存储连接字符串
- 集群的web服务URL
- 支持与集群中的代理交互的代理服务URL
初始化成功日志如下
部署BookKeeper
BookKeeper为Pulsar提供持久消息存储。每个pulsar broker 都需要自己的bookies集群。BookKeeper集群与Pulsar集群共享一个本地ZooKeeper仲裁。
bookies主机负责在磁盘上存储消息数据。为了让bookie提供最佳的性能,拥有合适的硬件配置对bookie来说是必不可少的。以下是bookies硬件容量的关键维度。
- 磁盘I/O读写容量
- 存储容量
通过配置文件conf/bookeeper.conf配置BookKeeper bookies。配置每个bookie最重要的方面是确保zkServers参数被设置为Pulsar集群的本地ZooKeeper的连接字符串。vim conf/bookkeeper.conf
# 修改本地地址
advertisedAddress=hadoop1
zkServers=zk1:2181,zk2:2181,zk3:2181
# 可以以两种方式启动一个bookie:在前台或作为后台守护进程启动。使用pulsar-daemon命令行工具在后台启动一个bookie:
bin/pulsar-daemon start bookie
# 你可以使用BookKeeper shell的bookiesanity命令来验证bookie是否正常工作,.这个命令在本地bookie上创建一个新的分类账,写一些条目,读回来,最后删除分类账。
bin/bookkeeper shell bookiesanity
# 在您启动了所有的bookie之后,可以在任何bookie节点上使用BookKeeper shell的simpletest命令,以验证集群中的所有bookie都在运行。
bin/bookkeeper shell simpletest --ensemble <num-bookies> --writeQuorum <num-bookies> --ackQuorum <num-bookies> --numEntries <num-entries>


其他bookie服务器也是同样配置(但需修改本地地址)和启动。
部署Broker
设置了ZooKeeper,初始化了集群元数据,并启动了BookKeeper bookie,就可以部署代理了。
修改配置文件 vi conf/broker.conf
clusterName=pulsar-cluster
advertisedAddress=hadoop1
zookeeperServers=zk1:2181,zk2:2181,zk3:2181
configurationStoreServers=zk1:2181,zk2:2181,zk3:2181
# 启动broker,bin/pulsar broker为前台启动
./bin/pulsar-daemon start broker
其他broker服务器也是同样配置(但需修改本地地址)和启动。查看broker的列表
./bin/pulsar-admin brokers list pulsar-cluster

Admin客户端和验证
# 可以配置客户端机器,这些客户端机器可以作为每个集群的管理客户端。可以使用conf/client.conf配置文件配置admin客户端。
serviceUrl=http://hadoop1:8080/
- 创建租户
bin/pulsar-admin tenants create itxs-tenant \
--allowed-clusters pulsar-cluster \
--admin-roles test-admin-role

- 创建namespace命名空间
bin/pulsar-admin namespaces create itxs-tenant/myns
- 测试生产者和消费者
# 启动一个消费者,在主题上创建一个订阅并等待消息:
bin/pulsar-perf consume persistent://itxs-tenant/myns/test-topic1
# 启动一个生产者,以固定的速率发布消息,并每10秒报告一次统计数据:
bin/pulsar-perf produce persistent://itxs-tenant/myns/test-topic1
# 报告主题统计信息:
bin/pulsar-admin topics stats persistent://itxs-tenant/myns/test-topic1
生产者的日志如下

消费者的日志如下
主题统计信息的日志如下
Tiered Storage(层级存储)
概述
Pulsar的分层存储特性允许将旧的积压数据从BookKeeper转移到长期和更便宜的存储中,同时允许客户端访问积压数据。
以流的方式永久保留原始数据,分区容量不再限制,充分利用云存储或现在廉价存储(例如HDFS),数据统一,客户端无需关心数据究竟存在哪里。
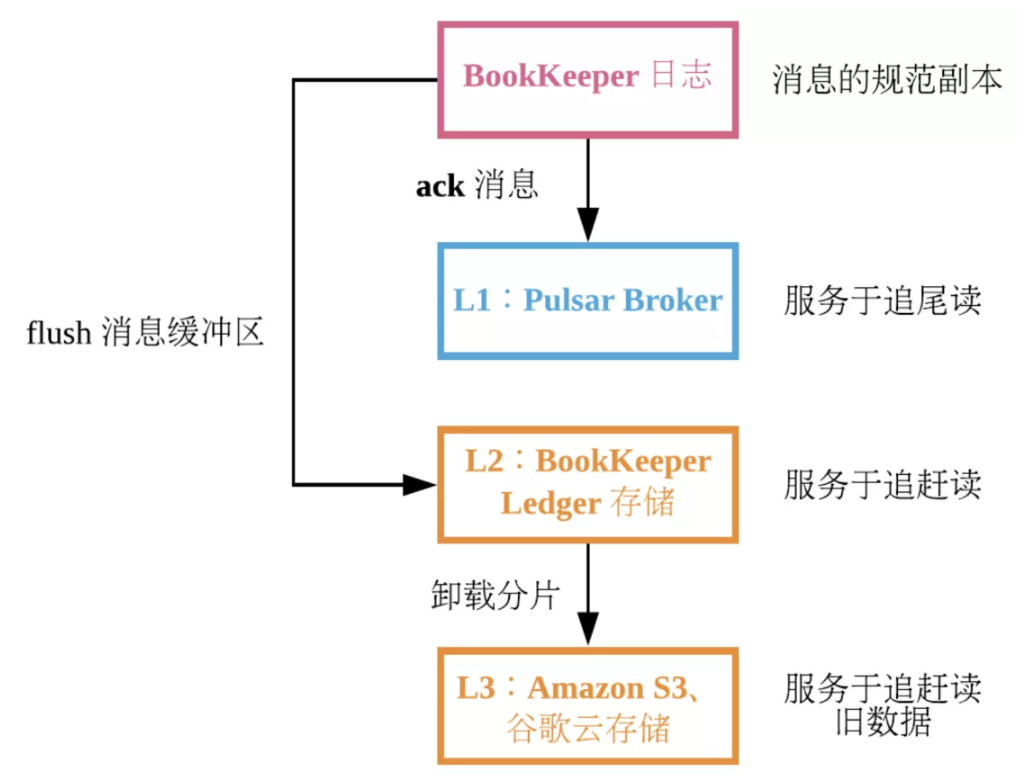
- 第一级:通过BookKeeper 预写日志
- 第二级: Pulsar broker,可用于追尾读。提交消息后,可以直接将消息发给所有与此 topic 相关的订阅者,而不必使用磁盘。
- 第三级: BookKeeper 节点上的 ledger 存储磁盘。将消息写入 BookKeeper 节点上的日志时,同时也写入到定期 flush 的 ledger 存储磁盘的内存缓冲区。BookKeeper 节点使用此磁盘提供读操作。
- 在 Pulsar 中,从内存缓冲区读消息很少见。追尾 consumer 通常直接从 Pulsar 的缓存中读消息。追赶 consumer 通常请求很早之前的消息,因此这些消息一般不存储在内存缓冲区。Ledger 存储磁盘服务于追赶读。Ledger 存储磁盘采用的存储消息的格式不仅保证在同一 topic 上尽可能按顺序读取,还优化了在同一磁盘上存储多个不同 topic 的能力。由于 ledger 存储磁盘与日志磁盘相互隔离,读操作不会影响日志磁盘中按顺序写入的性能。
- 如果为 Pulsar 配置了“分层存储”,则最后一级缓存为长期存储。分层存储允许用户对 topic backlog 中的较旧部分采用更节约成本的存储形式。分层存储利用了消息的不可变性,但粒度更大,因为在长期存储中单独存储每条消息会很浪费空间。Pulsar topic 日志由分片组成,每个分片默认对应一个包含 50000 条消息的序列。活跃分片只有一个,活跃分片之前的分片将关闭。当分片关闭时,无法继续添加新消息。假定分片中的单条消息不可变,并且单条消息的偏移量不可变,则此分片不可变。因此可以复制不可变对象到想要的任何位置。
- 要在 Pulsar 中使用分层存储,用户必须使用基于时间或基于大小的策略来配置 topic 命名空间以卸载分片。当命名空间中的 topic 达到策略中定义的阈值时,Pulsar broker 将 topic 日志中最旧的分片复制到长期存储中,直到该 topic 低于策略阈值。经过一段时间后,Pulsar 从 BookKeeper 中删除原来的分片,以释放磁盘空间。
- 第四级:Pulsar 支持将 Amazon S3 和 S3 兼容的对象存储用于长期存储,也支持 Azure 存储,并且从 Pulsar 2.2.0 起支持谷歌云存储。
支持分级存储
- 分级存储使用Apache jclouds支持Amazon S3、GCS(谷歌云存储)、Azure和阿里云OSS进行长期存储。
- 分级存储使用Apache Hadoop支持文件系统进行长期存储
何时使用
当你有一个主题,并且你想要在很长一段时间内保持一个很长的待办事项列表时,应该使用分层存储。例如,如果有一个包含用于训练推荐系统的用户操作的主题,希望长时间保留该数据,以便在更改推荐算法时可以根据完整的用户历史重新运行它。
工作原理
Pulsar中的主题由日志支持,称为托管分类账。这个日志由一个有序的段列表组成。脉冲星只写入日志的最后一段。所有之前的片段都是密封的。段内的数据是不可变的。这被称为面向段的体系结构。
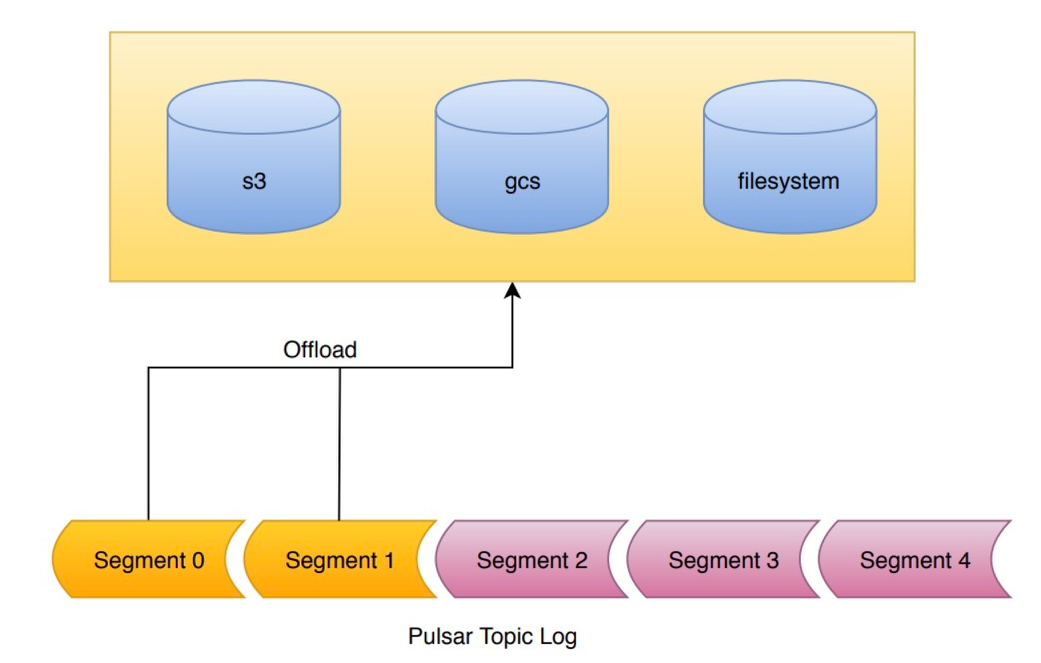
- 分层存储卸载机制利用了面向段的架构。当请求卸载时,日志段被逐个复制到分级存储中。写入分级存储的日志的所有段(除了当前段)都可以卸载。
- 写入BookKeeper的数据默认复制到3台物理机上。然而,一旦一个段被密封在BookKeeper中,它就变得不可变,可以复制到长期存储中。长期储存有潜力实现显著的成本节约。
- 在将分类帐卸载到长期存储之前,您需要为云存储服务配置桶、凭据和其他属性。此外,Pulsar使用多部分对象上传分段数据,代理可能会在上传数据时崩溃。建议为bucket添加一个生命周期规则,使其在一天或两天后过期未完成的多部分上传,以避免为未完成的上传收取费用。此外,可以手动(通过REST API或CLI)或自动(通过CLI)触发卸载操作。
- 在将分类账卸载到长期存储后,仍然可以使用Pulsar SQL查询卸载的分类账中的数据。
了解层级存储的基础知识后本篇先到此,下一篇将实战介绍层级存储、Pulsar IO、Pulsar Functions、Pulsar SQL、Transactions的操作和示例演示。
本人博客网站IT小神 www.itxiaoshen.com
云原生时代顶流消息中间件Apache Pulsar部署实操-上的更多相关文章
- [转帖]从 SOA 到微服务,企业分布式应用架构在云原生时代如何重塑?
从 SOA 到微服务,企业分布式应用架构在云原生时代如何重塑? 2019-10-08 10:26:28 阿里云云栖社区 阅读数 54 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权 ...
- CODING —— 云原生时代的研发工具领跑者
本文为 CODING 创始人兼 CEO 张海龙在腾讯云 CIF 工程效能峰会上所做的分享. 文末可前往峰会官网,观看回放并下载 PPT. 大家上午好,很高兴能有机会与大家分享 CODING 最近的一些 ...
- 🏆【JVM深层系列】「云原生时代的Java虚拟机」针对于GraalVM的技术知识脉络的重塑和探究
GraalVM 背景 新.旧编程语言的兴起躁动,说明必然有其需求动力所在,譬如互联网之于JavaScript.人工智能之于Python,微服务风潮之于Golang等等.大家都清楚不太可能有哪门语言能在 ...
- 阿里云弹性容器实例产品 ECI ——云原生时代的基础设施
阿里云弹性容器实例产品 ECI ——云原生时代的基础设施 1. 什么是 ECI 弹性容器实例 ECI (Elastic Container Instance) 是阿里云在云原生时代为用户提供的基础计算 ...
- 进击的 Java ,云原生时代的蜕变
作者| 易立 阿里云资深技术专家 导读:云原生时代的来临,与Java 开发者到底有什么联系?有人说,云原生压根不是为了 Java 存在的.然而,本文的作者却认为云原生时代,Java 依然可以胜任&qu ...
- 进击的.NET 在云原生时代的蜕变
你一定看过这篇文章 <进击的 Java ,云原生时代的蜕变>, 本篇文章的灵感来自于这篇文章.明天就将正式发布.NET Core 3.0, 所以写下这篇文章让大家全面认识.NET Cor ...
- 开放下载 | 《Knative 云原生应用开发指南》开启云原生时代 Serverless 之门
点击下载<Knative 云原生应用开发指南> 自 2018 年 Knative 项目开源后,就得到了广大开发者的密切关注.Knative 在 Kubernetes 之上提供了一套完整的应 ...
- .NET 在云原生时代的蜕变,让我在云时代脱颖而出
.NET 生态系统是一个不断变化的生态圈,我相信它正在朝着一个伟大的方向发展.有了开源和跨平台这两个关键优先事项,我们就可以放心了.云原生对应用运行时的不同需求,说明一个.NET Core 在云原生时 ...
- 【转】.NET 在云原生时代的蜕变,让我在云时代脱颖而出
原创:张善友 原文:https://www.cnblogs.com/shanyou/p/12198741.html .NET 生态系统是一个不断变化的生态圈,我相信它正在朝着一个伟大的方向发展.有了开 ...
- 云原生时代 给予.NET的机会
.NET诞生于与Java的竞争,微软当年被罚款20亿美元. Java绝不仅仅是一种语言,它是COM的替代者! 而COM恰恰是Windows的编程模型.而Java编程很多时候比C++编程要容易的多,更致 ...
随机推荐
- perl匹配特殊写法
my $name='4'; #找匹配4 for($name) { if(/^4$/) { print "success\n"; } else { print "faile ...
- C#一个16进制数用二进制数表示是几位?
1个字节是8位,二进制8位:xxxxxxxx 范围从00000000-11111111,表示0到255.一位16进制数(用二进制表示是xxxx) 最多只表示到15(即对应16进制的F),要表示到255 ...
- Dockerfile 使用 SSH docker build
如果在书写 Dockerfile 时,有些命令需要使用到 SSH 连接,比如从私有仓库下载文件等,那么我们应该怎么做呢? Dockerfile 文件配置 为了使得 Dockerfile 文件中的命令可 ...
- 并发bug之源(二)-有序性
什么是有序性? 简单来说,假设你写了下面的程序: int a = 1; int b = 2; System.out.println(a); System.out.println(b); 但经过编译器/ ...
- 基于python的数学建模---差分方程
一.递推关系--酵母菌生长模型 代码: import matplotlib.pyplot as plt time = [i for i in range(0,19)] number = [9.6,18 ...
- ARM MMU架构 -- CPU如何访问MMU及DRAM
<ARM Architecture Reference Manual ARMv8-A>里面有Memory层级框架图,从中可以看出L1.L2.DRAM.Disk.MMU之间的关系,以及他们在 ...
- Linux 使用打印机
前言 在 deepin 上打印机好使,在我的mint上不好使,简单的查看一下deepin上驱动及软件.安装上就行了. 软件及驱动 ii hpijs-ppds 3.18.12+dfsg0-2 all H ...
- Springboot整合thymeleaf报错whitelabel page
1.SpringBootApplication未放在最外层 2.application.properties未配置spring.thymeleaf.check-template-location=tr ...
- 记一次在CentOS上安装GitLab的流程
1.本次环境说明 系统:Centos7.6 IP地址:http://192.168.3.213: 最低配置要求:2核心CPU和4G内存,这是因为[GitLab]的整体运行包含了多个进程 2.自行安装 ...
- 有意思,小程序还可以一键生成App!
小程序≠微信小程序 说到小程序,大部分同学的第一反应,可能是微信小程序.支付宝小程序,确实,小程序的概念深入人心,并且已经被约定俗成的绑定到某些互联网公司的 APP 上. 但是,"小程序&q ...