[1] Multi-View Transformer for 3D Visual Grounding 论文精读
参考:
https://zhuanlan.zhihu.com/p/467913475
3D Visual Grounding小白调研笔记
https://zhuanlan.zhihu.com/p/34656727
zero-shot learning 入门
https://blog.csdn.net/rtygbwwwerr/article/details/50778098
交叉熵
https://zhuanlan.zhihu.com/p/388504127
Visual grounding系列--领域初探
很有可能Visual Grounding就是我的大方向了,目前打算好好读读这篇文章的所有引用。这是我当前对它的理解:https://www.cnblogs.com/loveandninenine/p/17131672.html
可能有很多不正确的地方,但是大概率博士课题就是这个方向了,好,言归正传,讲讲这篇文章。
题目
简单明确,就像这篇文章写的清晰、优雅一样。这是一篇基于Transformer的使用Multi-View来解决3D Visual Grounding问题的文章,是香港中文大学的huangshijia同学的工作,综合度非常高。
背景
3D的visual grounding与2D相比,多了一个非常严重的问题:视角,举个例子:

论文中的FIg 1,face the bad的视角只有一个,但是不在这个视角下,the pillow on the far right却不是同一个,那么如何解决这个视角的问题呢?这是本文所面对的主要挑战——模型预测与视角相关,因此如果学习单一视角下的数据,切换视角后模型很可能完全无法工作。因此本文给到的第一个解决方案——切换视角训练模型,希望能够得到一个对视角鲁棒的模型。
另外,其实我是第一次接触Visual Grounding这个工作,我其实很不理解这个工作有啥实际价值,但是文章把它的意义写的非常明确,如下:

本文的创新点在于,从3d数据的深层次的特点出发,考虑了多视图,其实本质就是用了多视角下的场景数据进行训练,从而得到一个对视图鲁棒的模型。
Related work
惭愧,related work我基本没有看懂,主要分为三部分,3d视觉定位、有监督的自然语言学习、以及多视图学习。挺吃力的其实,因为这三个领域的文章我都没读过,除了NLP的《Attention is all you need》、
因此在这不做过多介绍,接下来我会从这三个领域分别入手,读一些文章。
Method
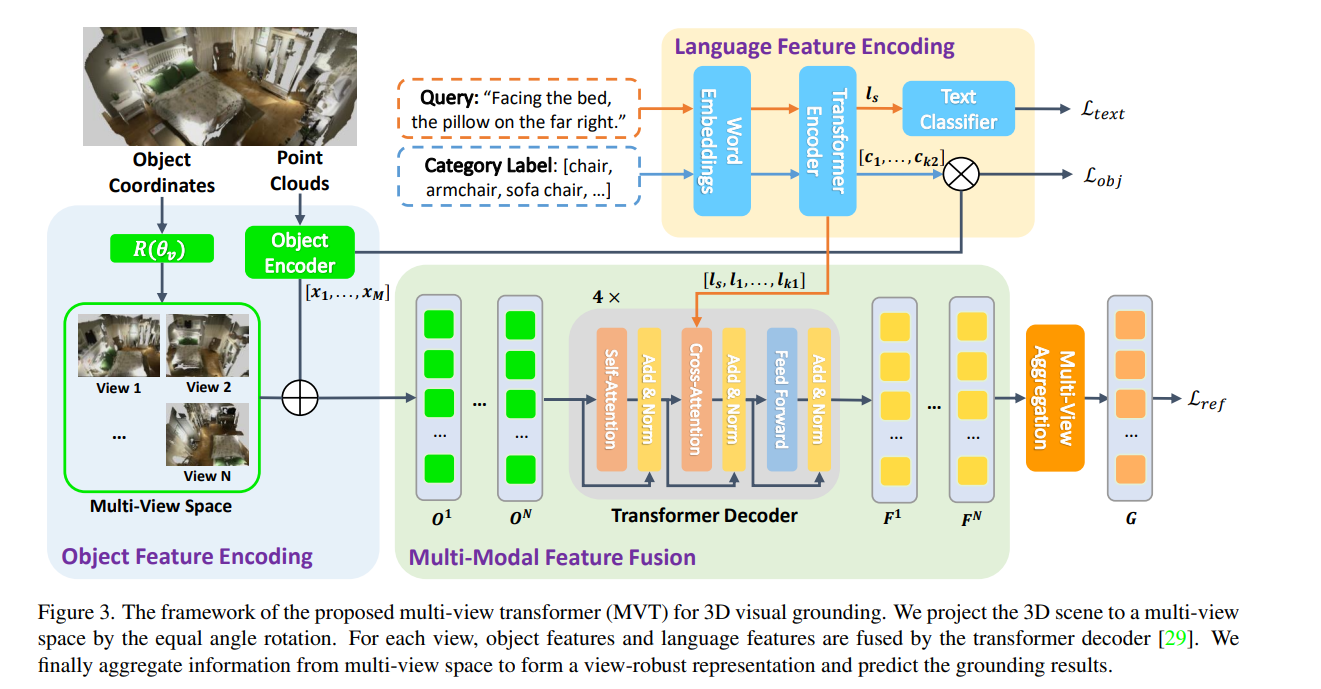
这就是整个MVT的架构了。
整个图画的还算不错,可以对着图完整地清晰讲出整个工作。图总共分为四个部分,咱们一点一点讲。
物体特征编码
首先,为什么会有物体特征编码这个工作?
因为在之前的工作中,基本都是没有考虑多视图问题的工作,而物体的特征提取是算力的主要瓶颈,因此如果计算多个视图下的object feature,将是一件非常costly的事情,这便是本文面临的第二个挑战——算力和效率上的不允许。本文给出的解决方案是——将物体的特征独立进行编码,而位置编码随着视角的切换进行编码。
这便是本部分右边的Object Encoder做的工作,x1到xm是这个场景中M个物体的特征,其使用PointNet++作为特征提取器,公式为: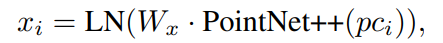
而左边输入的则是场景坐标,随后对其进行旋转,得到N个视图下的场景,具体的旋转方式非常容易描述,只沿着Z轴旋转,均匀地转一圈,比如如果是想得到四个视图,N=4,那么就是这个样子:
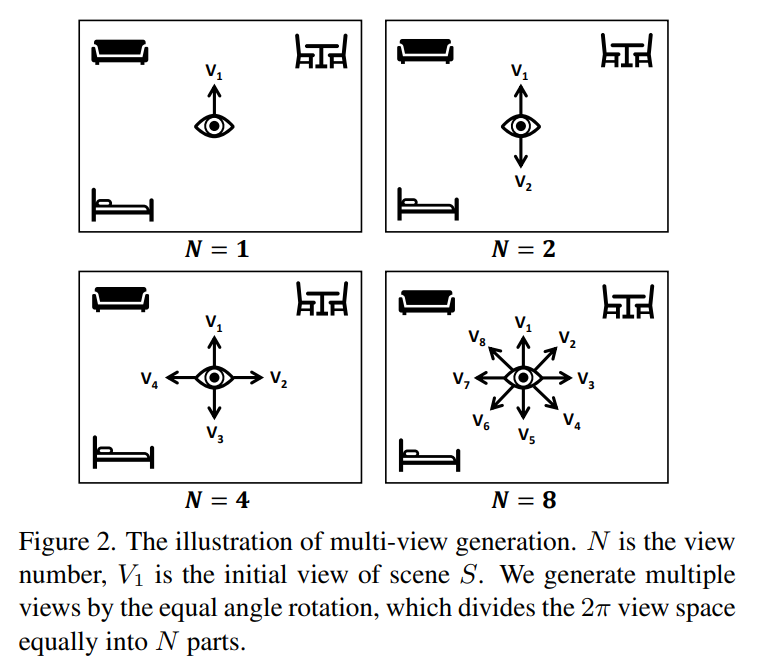
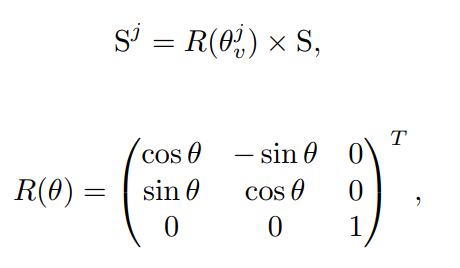
随后我们就得到了一个S序列,即不同视角下的S场景。
然后,开始做PE。
首先,将object使用box的中心点进行表示,然后对这些点进行旋转,旋转的方式也非常简单,就是让这个点乘以上面那个旋转矩阵,对得到的内容乘以一个权重矩阵,再过一层Normalization,就得到了最终次物体的PE。随后,将每个视角下的每个物体的PE直接加到上述得到的物体特征x上,就完成了对物体的位置编码。
语言特征编码
这里我现在其实不是很懂,简单说说吧,等我看了Bert之后,了解一些常用的NLP架构之后,再反过头来看这个。
首先看上面一行,输入的就是所谓的“文本描述”,也是作为Query存在的,对它过了一层Word Embedding,本文使用的是Bert,随后过了一层Transformer,并用来做cross-Attention,因为这里提取到的特征本质上已经是语言的特征了,可以直接和物体做跨注意力了。
除此之外,作者还在后面用了一个Text Classfier,本质上其实就是两个FC,用于预测文本所描述的具体物体,从而形成一个loss用来增强Bert,这个在NLP中好像挺有名的,李沐老师也讲过Bert 微调。
与此同时,为了让物体编码器增强,本文还使用Bert对物体标签进行了处理,利用句子级别的标签文本特征,对Object进行有监督的训练,于是就有了第二个loss。
多视图特征融合
接下来,作者用了一个非常简单但是让人拍案叫绝的操作——引入对称函数。这不得不让我想起当年祁芮中台的PointNet的壮举。作者是这么做的,如下:
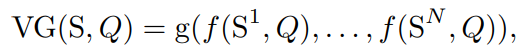
S是场景,Q是Query,也就是所谓的“描述文本”,f是一个特征提取的共享网络,可以理解成大概就是中间的Transformer这个部分了,它分别将不同视角下的描述文本感兴趣的场景信息找出来。
随后,g是一个顺序不依赖函数,换句话说,g是一个对称函数,它聚合了所有视图下的信息,并做了输出预测。
整个过程和Pointnet的灵感可以说是如出一辙,唯一不同的大概就是PointNet使用max函数,而MVT使用的确实Avg函数。
首先,将分别做PE的物体特征输入到网络,对其做自注意力,进一步对他们的特征进行抽象,随后于文本编码器产生的query文本做跨注意力,意图让模型找到文本所描述的内容,这就是经典的Transformer模型了,一共循环四次,最后输出了不同视图下的学习的结果——即面对这个query在不同视图下产生的预测。随后,就是将这些特征融合了。这里就是求平均后过了两层FC,最后输出的就是最终结果,这里也和ground truth做了一个loss。
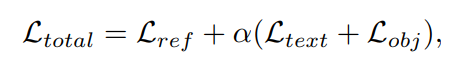
结果

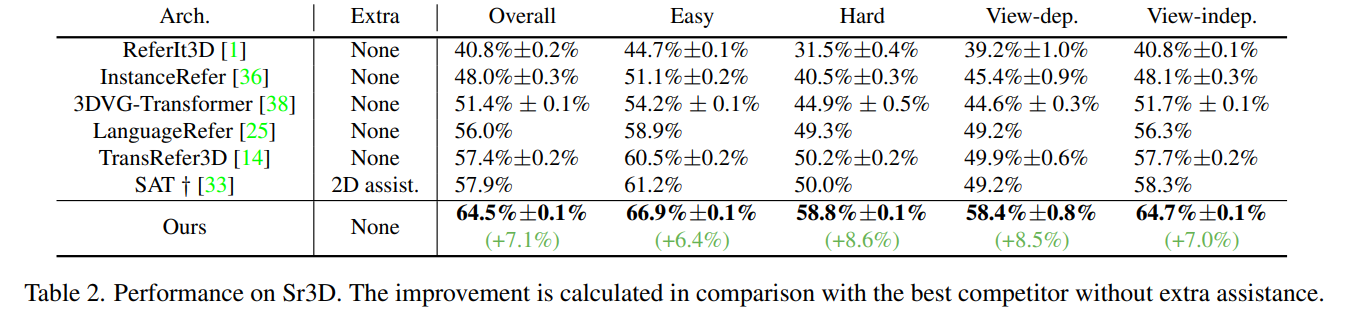
可以看到,这个提升是一个非常骇人的提升,所以对多视角的鲁棒性非常有必要。
感受
本文提出了一个基于视图鲁棒性的模型,非常新颖。、
但是本文解决的也是一个非常简单的问题,因为输入的场景和Query本身,并不受限制于视图。就像第一幅图那样,文本描述是面向床,比较远的右侧的枕头。而不是“我右侧的枕头”。这是一个非常简单的问题。最初我打算读这篇文章的时候觉得是它解决了随着视图变换ground truth也会跟着变换的工作,但其实不是,想想都很难。“我右侧的枕头”,如果我的视角旋转90度,那将变成“我左侧的枕头”,答案是完全相反的。显然这个问题目前没有人去研究,当然了,也没有数据集。3D数据集好像也就这么三个?看本文的意思是这样,本文将数据集进行了旋转而已。而至于我说的那个十分困难的问题,即ground truth要依赖于视角的问题,我觉得还有很长的一段路要走,这也是我想做这个方向的主要原因。
[1] Multi-View Transformer for 3D Visual Grounding 论文精读的更多相关文章
- Wordpress Calendar Event Multi View < 1.4.01 反射型xss漏洞(CVE-2021-24498)
简介 WordPress是Wordpress基金会的一套使用PHP语言开发的博客平台.该平台支持在PHP和MySQL的服务器上架设个人博客网站.WordPress 插件是WordPress开源的一个应 ...
- CVPR2019:无人驾驶3D目标检测论文点评
CVPR2019:无人驾驶3D目标检测论文点评 重读CVPR2019的文章,现在对以下文章进行点评. Stereo R-CNN based 3D Object Detection for Autono ...
- [读论文]Shading-aware multi view stereo
如何实现refine的? 几何误差和阴影误差如何加到一起? 为了解决什么问题? 弱纹理或无纹理:单纯的多视图立体算法在物体表面弱纹理或者无纹理区域重建完整度不够高,精度也不够高,因此结合阴影恢复形状来 ...
- 3d图像识别基础论文:pointNet阅读笔记
PointNet 论文阅读: 主要思路:输入独立的点云数据,进行变换不变性处理(T-net)后,通过pointNet网络训练后,最后通过最大池化和softMax分类器,输出评分结果. 摘要: 相较于之 ...
- Attribute2Image --- Conditional Image Generation from Visual Attributes 论文笔记
Attribute2Image --- Conditional Image Generation from Visual Attributes Target: 本文提出一种根据属性生成图像的产生式模 ...
- 基本3D变换之World Transform, View Transform and Projection Transform
作者:i_dovelemon 来源:CSDN 日期:2014 / 9 / 28 主题:World Transform, View Transform , Projection Transform 引言 ...
- 三维重建7:Visual SLAM算法笔记
VSLAM研究了几十年,新的东西不是很多,三维重建的VSLAM方法可以用一篇文章总结一下. 此文是一个好的视觉SLAM综述,对视觉SLAM总结比较全面,是SLAM那本书的很好的补充.介绍了基于滤波器的 ...
- [摘抄] SFM 和 Visual SLAM
来自知乎: SFM和vSLAM基本讨论的是同一问题,不过SFM是vision方向的叫法,而vSLAM是robotics方向的叫法. vSLAM所谓的mapping,vision方向叫structure ...
- Posterior visual bounds retrieval for the Plato framework
Plato is a MVVM compliant 2D on-canvas graphics framework I've been designing and implementing for d ...
- [转](四)unity4.6Ugui中文教程文档-------概要-UGUI Visual Components
转自孙广东. 转载请注明出处:http://write.blog.csdn.net/postedit/38922399 更全的内容请看我的游戏蛮牛地址:http://www.unitymanual ...
随机推荐
- 企业级GitLab在Docker部署使用
一.部署gitlab 这里使用的是Centos8,安装Docker环境 ,这里不说了,参考:https://www.cnblogs.com/wei325/p/15139701.html gitlab有 ...
- 网关与网络地址(网络号)以及IP地址、广播地址
转载新浪博客: http://blog.sina.com.cn/s/blog_406127500101i8bp.html
- vs修改默认端口
1.右键项目属性进去修改 2.,用txt打开sln解决方案,框框中的就是你当前的端口号
- Java语言输出菱形图型
package fuxi;public class Diamond { public static void main(String[] args) { printHollowRh ...
- Linux新手渣渣上路史
Linux新手渣渣上路史 时至2022年,IT行业的迅速发展大家也有目共睹,IT行业在社会的发展中起着举足轻重的作用.其中一角Linux系统,从诞生到开源,再到现在受大众的欢迎,是一个很好的例子.Li ...
- ISE_14.7_Windows10安装
直接下载安装会报如下错误: There was an unexpected error executing Import ISE Virtual Appliance 解决方案 1.阅读xilinx手册 ...
- wsl安装和使用
1.安装wsl的版本 1.使用管理员身份打开powershell,执行 wsl --list --online 2.安装相应的版本 wsl --install -d Ubuntu-20.04 2.更改 ...
- axios 进行同步请求(async+await+promise)
axios 进行同步请求(async+await+promise) 遇到的问题介绍 将axios的异步请求改为同步请求想到了async 和await.Promise axios介绍 Axios 是一个 ...
- div溢出横向滚动
需求:div在一行内需要溢出滚动 方案: 1:父类元素需要设置 overflow-x: auto; //横向方向溢出元素 white-space: nowrap; //溢出的元素不换行 2:子元素需 ...
- 【FPGA学习】MATLAB与FPGA实现FIR滤波器
本篇博客记录一下在matlab设计和在FPGA平台实现FIR滤波器的方法,平台是Xilinx的ZYNQ 参考: AMBA AXI-Stream Protocol Specification 使用mat ...