python代码统计核酸检测结果截图
#QQ:502440275@qq.com
#本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系
#1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg
#2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果
文件夹目录样式
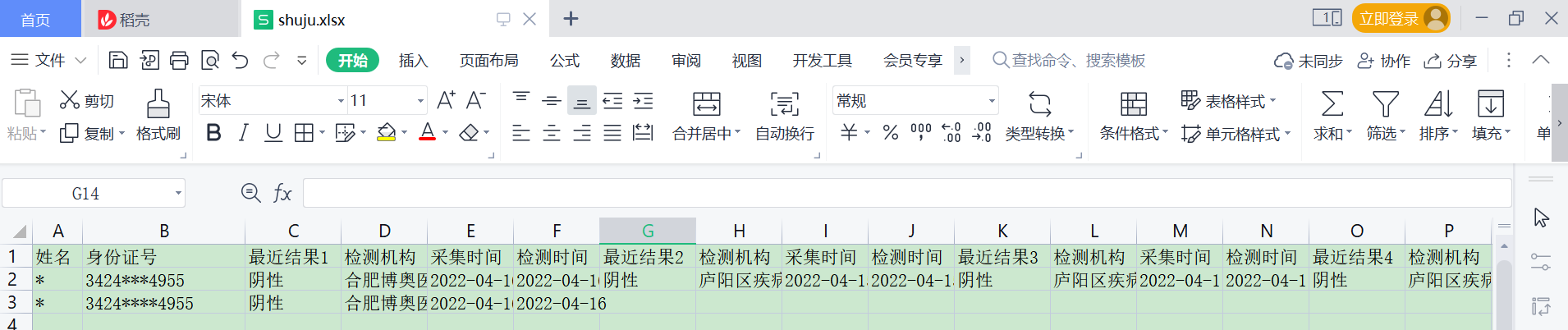
统计结果Excel样式
具体代码如下:
# @Time : 2022/4/19 22:00 # @Author : CFang # @File : hesuan_results.py # @Software: PyCharm
#QQ:502440275@qq.com
#本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系
#1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg
#2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果 #获得截图结果
def get_hesuan_res(path):
#获得API的access_token
import requests
AK = '*******'#输入自己的百度智能云的AK和SK
SK = '*******'
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AK+'&client_secret='+SK
response = requests.get(host)
if response:
print(response.json())
print(response.json()['access_token']) # encoding:utf-8
#文字识别接口,可自己调整不同接口获得不同精度要求
import requests
import base64 '''
通用文字识别
''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open(path, 'rb')
img = base64.b64encode(f.read()) params = {"image":img}
access_token = response.json()['access_token']
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
# print (response.json())
# print(response.json()['words_result'])
all_res = response.json()['words_result']
return all_res
# for i in range(len(all_res)):
# print(i,all_res[i]) # 对图片识别结果的数据清洗
all_lists_deals = []
def deal_datas(all_lists):
all_lists_deal = []
if all_lists[5]['words'].split(":")[0] == "姓名":
for i in range(5, len(all_lists)):
print(i, all_lists[i]['words']) # ,all_lists_display[i]['words']
if all_lists[i]['words'] != '>' and all_lists[i]['words'] != '身份证件号码:':
all_lists_deal.append(all_lists[i]['words'])
all_lists_deal[0] = all_lists_deal[0].split(":")[1][:-1]
# print(all_lists_deal)
else:
for i in range(6, len(all_lists)):
print(i, all_lists[i]['words']) # ,all_lists_display[i]['words']
if all_lists[i]['words'] != '>':
all_lists_deal.append(all_lists[i]['words'])
all_lists_deal[0] = all_lists_deal[0].split(":")[1]
all_lists_deal[1] = all_lists_deal[1].split(":")[1]
# print(all_lists_deal) print(all_lists_deal)
all_lists_deals.append(all_lists_deal) #获取文件夹imgs内的所有图片
import os
def get_imlist(path):
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')] img_path = get_imlist("imgs")
print(img_path) for path in img_path:
all_lists = get_hesuan_res(path)
deal_datas(all_lists) #保存识别清洗后的数据结果到“shuju.xlsx”表中
# -*- coding: UTF-8 -*-
from openpyxl import load_workbook wb = load_workbook('shuju.xlsx')
ws = wb['Sheet1'] row = ws.max_row+1
for j in range(len(all_lists_deals)):
for i in range(len(all_lists_deals[j])):
if len(all_lists_deals[j][i].split(":")) == 1:
ws.cell(row+j,i+1).value = all_lists_deals[j][i]
elif all_lists_deals[j][i].split(":")[0] == "检测机构" or all_lists_deals[j][i].split(":")[0] == "身份证件号码":
ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1]
else:
ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1][:10]
wb.save('shuju.xlsx')
python代码统计核酸检测结果截图的更多相关文章
- 30行Python代码实现人脸检测
参考OpenCV自带的例子,30行Python代码实现人脸检测,不得不说,Python这个语言的优势太明显了,几乎把所有复杂的细节都屏蔽了,虽然效率较差,不过在调用OpenCV的模块时,因为模块都是C ...
- Python代码统计工具
目录 Python代码统计工具 声明 一. 问题提出 二. 代码实现 三. 效果验证 Python代码统计工具 标签: Python 代码统计 声明 本文将对<Python实现C代码统计工具(一 ...
- python代码统计
代码统计 修改filename为文件夹or文件地址,然后统计所有python文件代码 import os import sys def count_code_lines(filename): res ...
- 10行Python代码实现目标检测
要知道图像中的目标是什么? 或者你想数一幅图里有多少个苹果? 在本文中,我将向你展示如何使用Python在不到10行代码中创建自己的目标检测程序. 如果尚未安装python库,你需要安装以下pytho ...
- 25行 Python 代码实现人脸检测——OpenCV 技术教程
这是篇是利用 OpenCV 进行人脸识别的技术讲解.阅读本文之前,这是注意事项: 建议先读一遍本文再跑代码——你需要理解这些代码是干什么的.成功跑一遍不是目的,能够举一反三.在新任务上找出 bug 才 ...
- Python实现代码统计工具——终极加速篇
Python实现代码统计工具--终极加速篇 声明 本文对于先前系列文章中实现的C/Python代码统计工具(CPLineCounter),通过C扩展接口重写核心算法加以优化,并与网上常见的统计工具做对 ...
- Python实现C代码统计工具(二)
目录 Python实现C代码统计工具(二) 声明 一. 问题提出 二. 代码实现 三. 效果验证 Python实现C代码统计工具(二) 标签: Python 代码统计 声明 本文将对<Pytho ...
- Python实现C代码统计工具(一)
目录 Python实现C代码统计工具(一) 声明 一. 问题提出 二. 代码实现 三. 效果验证 四. 后记 Python实现C代码统计工具(一) 标签: Python 代码统计 声明 本文将基于Py ...
- 看完复旦博士用Python统计核酸结果后,我照着也写了一个
前几天,人民日报公众号报道了复旦博士生自己写代码,通过OCR和正则表达式统计核酸截图结果.具体文章见:https://mp.weixin.qq.com/s/l8u9JifKDlRDoz32-jZWQg ...
随机推荐
- 如何做一个网站 (C# + MVC Web+ easyUI )
如何做一个网站 小编想做一个网站,采用技术为:C# + MVC Web+ easyUI 小编经过几天的学习,以及指了几位大神指导,初见效果.建立网站的思路:先列举需要用到了几个知识点,然后逐一攻克,然 ...
- 如何使用双重检查锁定在 Java 中创建线程安全的单例?
这个 Java 问题也常被问: 什么是线程安全的单例,你怎么创建它.好吧,在Java 5之前的版本, 使用双重检查锁定创建单例 Singleton 时,如果多个线程试图同时创建 Singleton 实 ...
- 什么是 Netflix Feign?它的优点是什么?
Feign 是受到 Retrofit,JAXRS-2.0 和 WebSocket 启发的 java 客户端联编程序. Feign 的第一个目标是将约束分母的复杂性统一到 http apis,而不考虑其 ...
- Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,首先它得是一个配置文件,其次根据类路径下是否有这个 ...
- oracle.i18n.text.convert.CharacterConverterOGS.getInstance(I)Loracle/i18n/text/converter/CharacterConver;
看看项目是不是同时包含ojdbc系列jar包和nls_charset12.jar包.如果同时包含,则删除nls_charset12.jar.因为低版本的nls_charset12和ojdbc包冲突.
- 什么是通用 SQL 函数?
1.CONCAT(A, B) – 连接两个字符串值以创建单个字符串输出.通常用于将两个 或多个字段合并为一个字段. 2.FORMAT(X, D)- 格式化数字 X 到 D 有效数字. 3.CURRDA ...
- java-网络通信--socket实现多人聊天(基于命令行)
先编写最简答的服务器 思路 1编写一个实现Runnable接口的静态内部类 ServerC,便于区分每个客户端 1.1 获取客户端数据函数 public String remsg() 1.2 转发消息 ...
- Java Lambda详解
Lambda表达式是JDK 8开始后的一种新语法形式. 作用:简化匿名内部类的代码写法 简化格式 (匿名内部类被重写方法的形参列表) -> { 重写方法 } Lambda表达式只能简化函数式接口 ...
- docker 容器简单使用
文章目录 docker简介 docker容器简单使用 1.HelloWorld 2.运行交互式的容器 3.启动容器(后台模式) 安装docker容器的博文有很多这里就不做过多赘述了,另外如果不想安装d ...
- JavaScript正则进阶之路——活学妙用奇淫正则表达式
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴. 有些童鞋肯定 ...