字节跳动构建Data Catalog数据目录系统的实践(上)
一、背景
1. 元数据与 Data Catalog
元数据,一般指描述数据的数据,对数据及信息资源的描述性信息。在当前大数据的上下文里,通常又可细分为技术元数据和业务元数据。Data Catalog,是一种元数据管理的服务,会收集技术元数据,并在其基础上提供更丰富的业务上下文与语义,通常支持元数据编目、查找、详情浏览等功能。元数据是 Data Catalog 系统的基础,而 Data Catalog 使元数据更好的发挥业务价值。
2. Data Catalog 的业务价值
Data Catalog 系统主要服务于两类用户的两种核心场景。
对于数据生产者来说,他们利用 Data Catalog 系统来组织、梳理自己负责的各类元数据。生产者大部分是大数据开发的同学。通常,生产者会将某一批相关的元数据以目录等形式编排到一起,方便维护。另外,生产者会持续的在技术元数据的基础上,丰富业务相关的属性,比如打业务标签,添加应用场景描述,字段解释等。
对于数据消费者来说,他们通过 Data Catalog 查找和理解他们需要的数据。在用户数量和角色上看,消费者远多于生产者,涵盖了数据分析师、产品、运营等多种角色的同学。通常,消费者会通过关键字检索,或者目录浏览,来查找解决自己业务场景的数据,并浏览详情介绍,字段描述,产出关系等,进一步的理解和信任数据。
另外,Data Catalog 系统中的各类元数据,也会向上服务于数据开发、数据治理两大类产品体系。
在大数据领域,各类计算和存储系统百花齐放,概念和原理又千差万别,对于元数据的采集、组织、理解、信任等,都带来了很大挑战。因此,做好一个 Data Catalog 产品,本身是一个门槛低、上限高的工作,需要有一个持续打磨提升的过程。
3. 旧版本痛点
字节跳动 Data Catalog 产品早期为能较快解决 Hive 的元数据收集与检索工作,是基于 LinkedIn Wherehows 进行二次改造 。Wherehows 架构相对简单,采用 Backend + ETL 的模式。初期版本,主要利用 Wherehows 的存储设计和 ETL 框架,自研实现前后端的功能模块。
随着字节跳动业务的快速发展, 公司内各类存储引擎不断引入,数据生产者和消费者的痛点都日益明显。之前系统的设计问题,也到了需要解决的阶段。具体来说:
用户层面痛点:
数据生产者: 多引擎环境下,没有便捷、友好的数据组织形式,来一站式的管理各类存储、计算引擎的技术与业务元数据。数据消费者: 各种引擎之间找数难,元数据的业务解释零散造成理解数难,难以信任。
技术痛点:
扩展性:新接入一类元数据时,整套系统伤筋动骨,开发成本月级别。
可维护性:经过一段时间的修修补补,整个系统显的很脆弱,研发人员不敢随便改动;存储依赖重,同时使用了 MySQL、ElasticSearch、图数据库等系统存储元数据,维护成本很高;接入一种元数据会增加 2~3 个 ETL 任务,运维成本直线上升。**4. 新版本目标 **基于上述痛点,我们重新设计实现 Data Catalog 系统,希望能达成如下目标:
产品能力上,帮助数据生产者方便快捷组织元数据,数据消费者更好的找数和理解数。
系统能力上,将接入新型元数据的成本从月级别降低为星期甚至天级别,架构精简,单人业余时间可运维。
二、 调研与思路
1. 业界产品调研
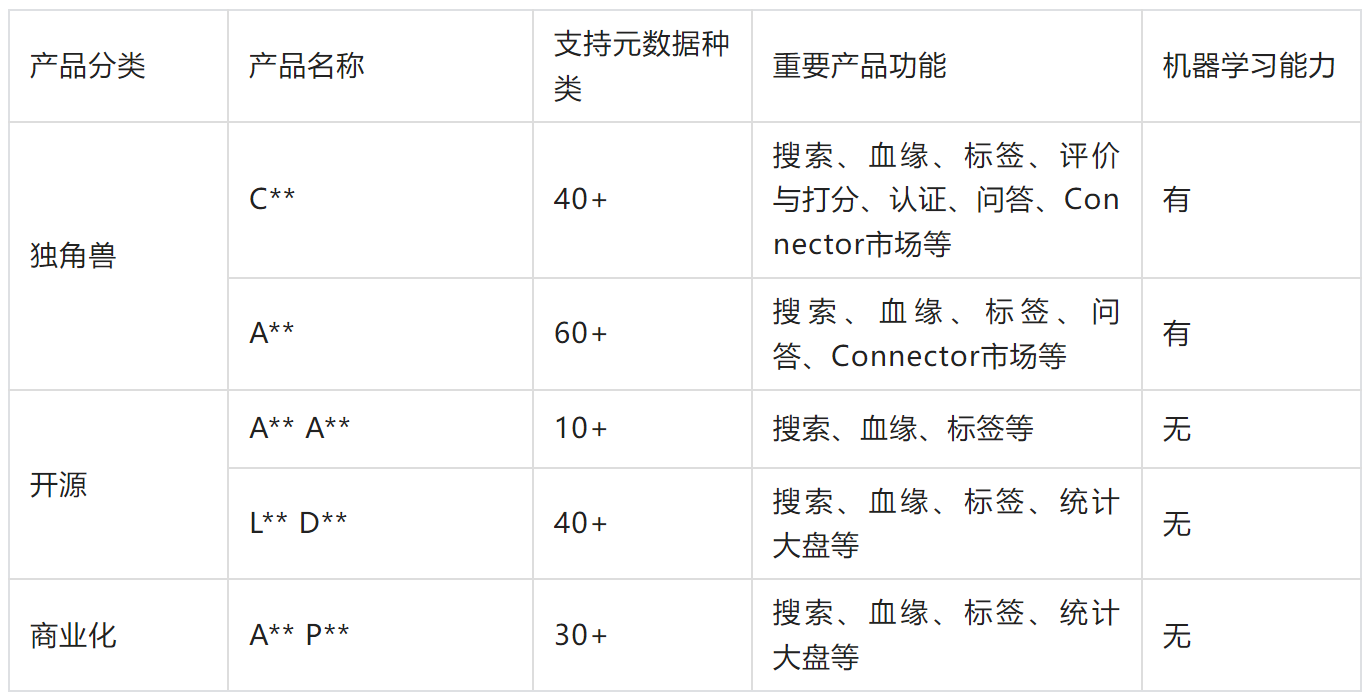
站在巨人的肩膀上,动手之前我们针对业界主流 DataCatalog 产品做了产品功能和技术调研。因各个系统都在频繁迭代,数据仅供参考。
2. 升级思路
根据调研结论,结合字节已有业务特点,我们敲定了以下发展思路:对于搜索、血缘这类核心能力,做深做强,对齐业界领先水平。对于各产品间特色功能,挑选适合字节业务特点的做融合。技术体系上,存储和模型能力基于 Apache Atlas 改造,应用层支持从旧版本平滑迁移。
三、技术与产品概览
1. 架构设计
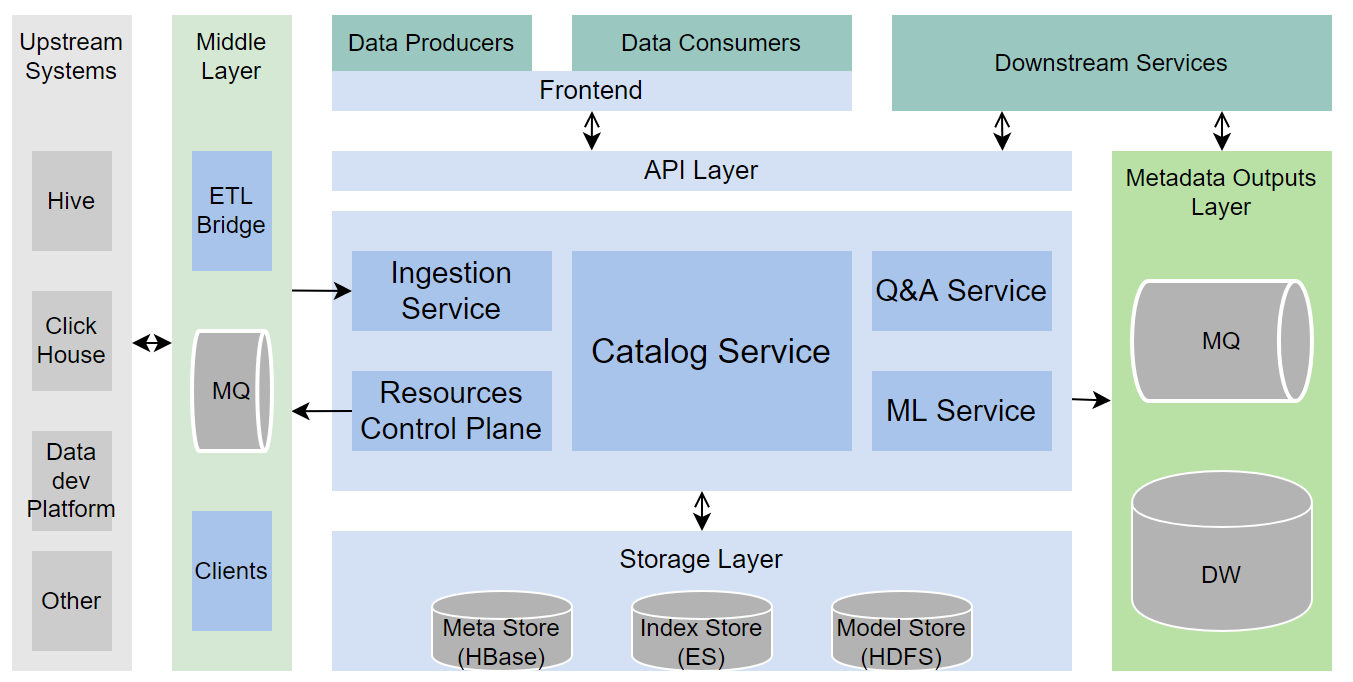
(1)元数据的接入
元数据接入支持 T+1 和近实时两种方式
上游系统:包括各类存储系统(比如 Hive、 Clickhouse 等)和业务系统(比如数据开发平台、数据质量平台等)
中间层:
ETL Bridge:T+1 方式运行,通常是从外部系统拉取最新元数据,与当前 Catalog 系统的元数据做对比,并更新差异的部分
MQ:用于暂存各类元数据增量消息,供 Catalog 系统近实时消费与上游系统打交道的各类 Clients,封装了操作底层资源的能力
(2)核心服务层
系统的核心服务,根据职责的不同,细拆为以下子服务:
Catalog Service:支持元数据的搜索、详情、修改等核心服务
Ingestion Service:接受外部系统调用,写入元数据,或主动从 MQ 中消费增量元数据
Resource Control Plane:通过各类 Clients,与底层的存储或业务系统交互,操作底层资源,比如建库建表,能力可插拔
Q&A Service:问答系统相关能力,支持对元数据的字段含义、使用场景等提问和回答,能力可插拔
ML Service:负责封装与机器学习相关的能力,能力可插拔
API Layer:以 RESTful API 的形式整合系统中的各类能力
(3)存储层
针对不同场景,选用的不同的存储:
Meta Store:存放全量元数据和血缘关系,当前使用的是 HBase
Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是 ElasticSearch
Model Store:存放推荐、打标等的算法模型信息,使用 HDFS,当 ML Service 启用时使用
(4)元数据的消费
数据的生产者和消费者,通过 Data Catalog 的前端与系统交互
下游在线服务可通过 OpenAPI 访问元数据,与系统交互
Metadata Outputs Layer:提供除了 API 之外的另外一种下游消费方式
MQ:用于暂存各类元数据变更消息,格式由 Catalog 系统官方定义 Data warehouse:以数仓表的形式呈现的全量元数据
2. 产品功能升级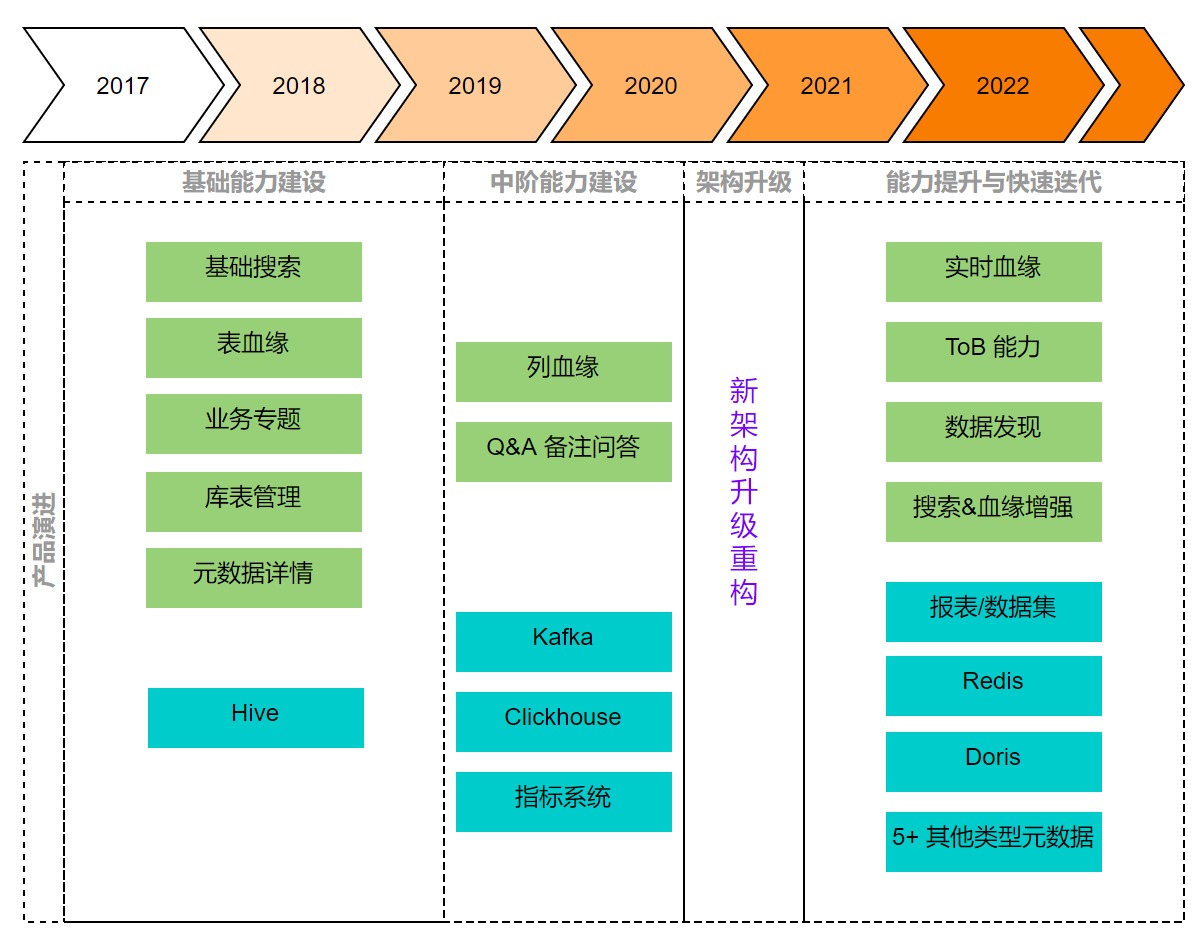
产品能力上的升级迭代,大致分为以下几个阶段:
基础能力建设(2017-2019):数据源主要是离线数仓 Hive,支持了 Hive 相关库表创建、元数据搜索与详情展示、表之间血缘,以及将相关表组织成业务视角的数据专题等
中阶能力建设(2019-2020 年中):数据源扩展了 Clickhouse 与 Kafka,支持了 Hive 列血缘,Q&A 问答系统等
架构升级(2020 年中-2021 年初):产品能力迭代放缓,基于新设计升级架构
能力提升与快速迭代(2021 年至今):数据源扩展为包含离线、近实时、业务等端到端系统,搜索和血缘能力有明显增强,探索机器学习能力,产品形态更成熟稳定。另外我们还具备了 ToB 售卖的能力。
四、关联产品
一站式数据中台套件,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,帮助数据团队有效的降低工作成本和数据维护成本、挖掘数据价值、为企业决策提供数据支撑。
欢迎关注字节跳动数据平台同名公众号获取更多技术干货
字节跳动构建Data Catalog数据目录系统的实践(上)的更多相关文章
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 刷到血赚!字节跳动内部出品:722页Android开发《360°全方面性能调优》学习手册首次外放,附项目实战!
前言 我们平时在使用软件的过程中是不是遇到过这样的情况:"这个 app 怎么还没下载完!"."太卡了吧!"."图片怎么还没加载出来!".&q ...
- 字节跳动挤上少儿英语末班车,gogokid能否抵达终点?
编辑 | 于斌 出品 | 于见(mpyujian) 近日,据多方消息,字节跳动旗下少儿英语品牌gogokid,迎来了一位新的90后CEO金钱琛.据知情人士透露,金钱琛入职不到两个月,目前全面掌管gog ...
- 在字节跳动,一个更好的企业级SparkSQL Server这么做
SparkSQL是Spark生态系统中非常重要的组件.面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求.本文将详细解读,如何通过构建SparkSQL服务器实现使用效 ...
- 去了字节跳动,才知道年薪40W的测试有这么多?
最近脉脉职言区有一条讨论火了: 哪家互联网公司薪资最'厉害'? 下面的评论多为字节跳动,还炸出了很多年薪40W的测试工程师 我只想问一句,现在的测试都这么有钱了吗? 前几天还有朋友说,从腾讯跳槽去 ...
- 爱了,字节跳动大神最佳整理:582页Android NDK七大模块学习宝典,理论与实践
前言 时至今日,短视频App可谓是如日中天,一片兴兴向荣.随着短视频的兴起,音视频开发也越来越受到重视,而且薪资水涨船高,以一线城市为例,音视频工程开发的薪资比Android应用层开发高出40%. 但 ...
- 字节跳动、快手等大厂Android面试刨根问底之内存泄露篇
现在快手字节跳动等公司都在大量招人,薪资优厚,但是想进去却没那么简单,面过的人都知道,这些公司的面试官巴不得把你会的东西都给你挖出来,所以要深入复习知识点,让自己耐问一点.一下是针对内存泄露真实面试过 ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
随机推荐
- SpringBoot和SpringCloud的区别?
SpringBoot专注于快速方便的开发单个个体微服务. SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来, 为各个微服务之间提供 ...
- Java中hashCode、equals、==的区别
ref:http://www.cnblogs.com/skywang12345/p/3324958.html 1.==作用: java中的==用来判断两个对象的地址是否相等:当对象是基本数据类型时,可 ...
- Collection和 Collections的区别?
Collection是集合类的上级接口,继承与他的接口主要有Set和List.Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索.排序.线程安全化等操作.
- 简述 Mybatis 的插件运行原理,以及如何编写一个插件?
Mybatis 仅可以编写针对 ParameterHandler.ResultSetHandler. StatementHandler.Executor 这 4 种接口的插件,Mybatis 使用 J ...
- Jpa设置默认值约束
使用SpringDataJpa设置字段的默认值约束的2种方式 // 第一种方式是修改建表时的列定义属性 @Column(columnDefinition = "varchar(35) def ...
- JVM监控工具介绍jstack, jconsole, jinfo, jmap, jdb, jsta
JVM监控工具介绍 jstack - 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程 ...
- scanf()函数的原理
最近使用scanf发现了自己对scanf函数还是不太了解,主要出现在无意中出现的一个错误: scanf正确的写法是,scanf中以什么格式输入变量,则变量的类型就应该是什么格式,如下面scanf输入到 ...
- getch()函数的使用方法及其返回值问题
getch()函数依赖于头文件 conio.h .会在windows平台下从控制台无回显地取一个字符,并且返回读取到的字符. 然而,我在实际用这个函数才发现getch()这个函数并不简单. getch ...
- Linux 0.11源码阅读笔记-高速缓冲
高速缓冲 概念 高速缓冲区是内存中的一块内存,在块设备与内核其它程序之间起着一个桥梁作用.内核程序如果需要访问块设备中的数据,都需要经过高速缓冲区来间接的操作. 高速缓冲区结构 高速缓冲区被划分为1k ...
- tomcat启动报错:A child container failed during start
环境:maven3.3.9+jdk1.8+tomcat8.5 错误详细描述: 严重: A child container failed during start java.util.concurren ...