强化学习-学习笔记8 | Q-learning
上一篇笔记认识了Sarsa,可以用来训练动作价值函数\(Q_\pi\);本篇来学习Q-Learning,这是另一种 TD 算法,用来学习 最优动作价值函数 Q-star,这就是之前价值学习中用来训练 DQN 的算法。
8. Q-learning
承接上一篇的疑惑,对比一下两个算法。
8.1 Sarsa VS Q-Learning
这两个都是 TD 算法,但是解决的问题不同。
Sarsa
- Sarsa 训练动作价值函数 \(Q_\pi(s,a)\);
- TD target:\(y_t = r_t + \gamma \cdot {Q_\pi(s_{t+1},a_{t+1})}\)
- 价值网络是 \(Q_\pi\) 的函数近似,Actor-Critic 方法中,用 Sarsa 更新价值网络(Critic)
Q-Learning
Q-learning 是训练最优动作价值函数 \(Q^*(s,a)\)
TD target :\(y_t = r_t + \gamma \cdot {\mathop{max}\limits_{a}Q^*(s_{t+1},a_{t+1})}\),对 Q 求最大化
注意这里就是区别。
用Q-learning 训练DQN
个人总结区别在于Sarsa动作是随机采样的,而Q-learning是取期望最大值
下面推导 Q-Learning 算法。
8.2 Derive TD target
注意Q-learning 和 Sarsa 的 TD target 有区别。
之前 Sarsa 证明了这个等式:\(Q_\pi({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot Q_\pi({S_{t+1}},{A_{t+1}})]\)
等式的意思是,\(Q_\pi\) 可以写成 奖励 以及 \(Q_\pi\) 对下一时刻做出的估计;
等式两端都有 Q,并且对于所有的 \(\pi\) 都成立。
所以把最优策略记作 \(\pi^*\),上述公式对其也成立,有:
\(Q_{\pi^*}({s_t},{a_t}) = \mathbb{E}[{R_t} + \gamma \cdot Q_{\pi^*}({S_{t+1}},{A_{t+1}})]\)
通常把\(Q_{\pi^*}\) 记作 \(Q^*\),都可以表示最优动作价值函数,于是便得到:
\(Q^*({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot Q^*({S_{t+1}},{A_{t+1}})]\)
处理右侧 期望中的 \(Q^*\),将其写成最大化形式:
因为\(A_{t+1} = \mathop{argmax}\limits_{a} Q^*({S_{t+1}},{a})\) ,A一定是最大化 \(Q^*\)的那个动作
解释:
给定状态\(S_{t+1}\),Q* 会给所有动作打分,agent 会执行分值最高的动作。
因此 \(Q^*({S_{t+1}},{A_{t+1}}) = \mathop{max}\limits_{a} Q^*({S_{t+1}},{a})\),\(A_{t+1}\) 是最优动作,可以最大化 \(Q^*\);
带入期望得到:\(Q^({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({S_{t+1}},{a})]\)
左边是 t 时刻的预测,等于右边的期望,期望中有最大化;期望不好求,用蒙特卡洛近似。用 \(r_t \ s_{t+1}\) 代替 \(R_t \ S_{t+1}\);
做蒙特卡洛近似:\(\approx {r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a})\)称为TD target \(y_t\)。
此处 \(y_t\) 有一部分真实的观测,所以比左侧 Q-star 完全的猜测要靠谱,所以尽量要让左侧 Q-star 接近 \(y_t\)。
8.3 算法过程
a. 表格形式
- 观测一个transition \(({s_t},{a_t},{r_t},{s_{t+1}})\)
- 用 \(s_{t+1} \ r_t\) 计算 TD target:\({r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a})\)
- Q-star 就是下图这样的表格:
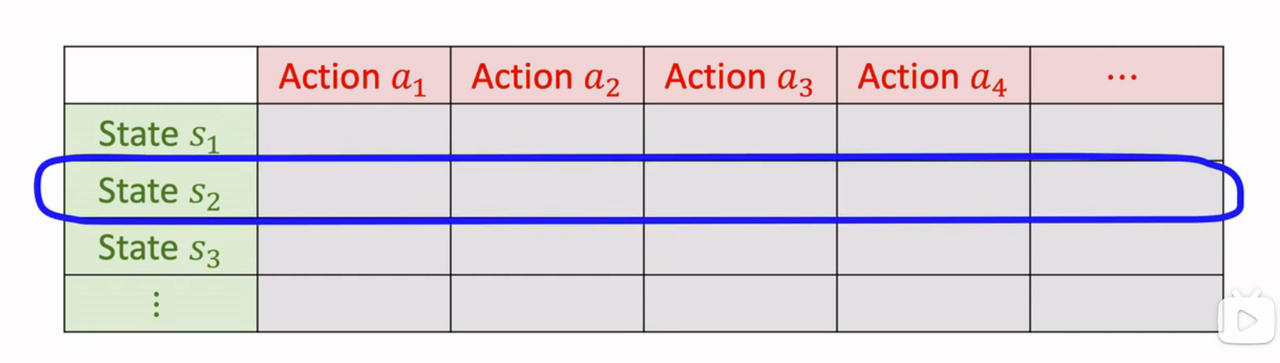
找到状态 \(s_{t+1}\) 对应的行,找出最大元素,就是 \(Q^*\) 关于 a 的最大值。
- 计算 TD error: \(\delta_t = Q^*({s_t},{a_t}) - y_t\)
- 更新\(Q^*({s_t},{a_t}) \leftarrow Q^*({s_t},{a_t}) - \alpha \cdot \delta_t\),更新\((s_{t},a_t)\)位置,让Q-star 值更接近 \(y_t\)
b. DQN形式
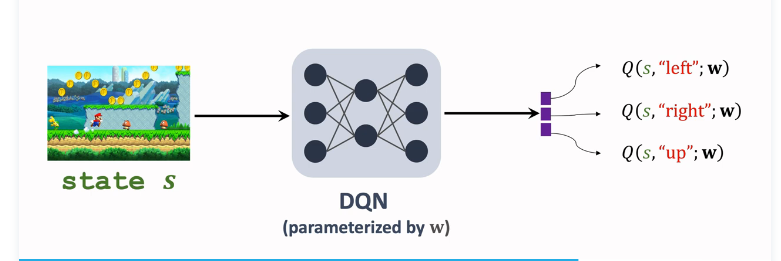
DQN \(Q^*({s},{a};w)\)近似 $Q^*({s},{a}) $,输入是当前状态 s,输出是对所有动作的打分;
接下来选择最大化价值的动作 \({a_t}= \mathop{argmax}\limits_{{a}} Q^*({S_{t+1}},{a},w)\),让 agent 执行 \(a_t\);用收集到的 transitions 学习训练参数 w,让DQN 的打分 q 更准确;
用 Q-learning 训练DQN的过程:
- 观测一个transition \(({s_t},{a_t},{r_t},{s_{t+1}})\)
- TD target: \({r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a};w)\)
- TD error: \(\delta_t = Q^*({s_t},{a_t};w) - y_t\)
- 梯度下降,更新参数: \(w \leftarrow w -\alpha \cdot \delta_t \cdot \frac{{s_t},{a_t};w}{\partial w}\)
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
- 笔记参考:
强化学习-学习笔记8 | Q-learning的更多相关文章
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
随机推荐
- 我发现 Linux 文档写错了
作者:小林coding 图解计算机基础网站:https://xiaolincoding.com 大家好,我是小林. 周末的时候,有位读者疑惑为什么 Linux man 手册中关于 netstat 命令 ...
- 安装黑苹果 、 Mac OS虚拟机
Mac OS 虚拟机 所需文件地址 unlocker 为VMware 新增Apple Mac OS X操作系统 Install_macOS_Monterey_12.0.1_21A559.iso 提取码 ...
- Halo 开源项目学习(四):发布文章与页面
基本介绍 博客最基本的功能就是让作者能够自由发布自己的文章,分享自己观点,记录学习的过程.Halo 为用户提供了发布文章和展示自定义页面的功能,下面我们分析一下这些功能的实现过程. 管理员发布文章 H ...
- 在GO中调用C源代码#基础篇1
开坑说明 最近在编写客户端程序或与其他部门做功能集成时多次碰到了跨语言的sdk集成,虽说方案很多诸如rpc啊,管道啊,文件io啊,unix socket啊之类的不要太多,但最完美的基础方式还是让程序与 ...
- 消息队列,IPC机制(进程间通信),生产者消费者模型,线程及相关
消息队列 创建 ''' Queue是模块multiprocessing中的一个类我们也可以这样导入from multiprocessing import Queue,创 建时queue = Queue ...
- unity---光照基础
发射光源类型 光照参数介绍 让摄像头看到Flare 耀斑 改变影子
- 面试官:BIO、NIO、AIO是什么,他们有什么区别?
哈喽!大家好,我是小奇,一位热爱分享的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 书接上回,感觉上次的公司氛围不 ...
- python 企业微信发送文件
import os import json import urllib3 class WinxinApi(object): def __init__(self,corpid,secret,chatid ...
- 【原创】快速理解Unicode和utf-8的本质
字符串编码 基本概念 在代码中处理,为了字节统一,都统一使用Unicode 核心:在pyhton中s.encode("utf-8")中的变量实例s必须是已经是Unicode格式,否 ...
- DAST 黑盒漏洞扫描器 第二篇:规则篇
0X01 前言 怎么衡量一个扫描器的好坏,扫描覆盖率高.扫描快.扫描过程安全 而最直接的效果就是扫描覆盖率高(扫的全) 怎么扫描全面,1 流量全面 2 规则漏报低 流量方面上篇已经讲过,这篇主要讲扫描 ...