Pytorch分布式训练
用单机单卡训练模型的时代已经过去,单机多卡已经成为主流配置。如何最大化发挥多卡的作用呢?本文介绍Pytorch中的DistributedDataParallel方法。
1. DataParallel
其实Pytorch早就有数据并行的工具DataParallel,它是通过单进程多线程的方式实现数据并行的。
简单来说,DataParallel有一个参数服务器的概念,参数服务器所在线程会接受其他线程传回来的梯度与参数,整合后进行参数更新,再将更新后的参数发回给其他线程,这里有一个单对多的双向传输。因为Python语言有GIL限制,所以这种方式并不高效,比方说实际上4卡可能只有2~3倍的提速。
2. DistributedDataParallel
Pytorch目前提供了更加高效的实现,也就是DistributedDataParallel。从命名上比DataParallel多了一个分布式的概念。首先 DistributedDataParallel是能够实现多机多卡训练的,但考虑到大部分的用户并没有多机多卡的环境,本篇博文主要介绍单机多卡的用法。
从原理上来说,DistributedDataParallel采用了多进程,避免了python多线程的效率低问题。一般来说,每个GPU都运行在一个单独的进程内,每个进程会独立计算梯度。
同时DistributedDataParallel抛弃了参数服务器中一对多的传输与同步问题,而是采用了环形的梯度传递,这里引用知乎上的图例。这种环形同步使得每个GPU只需要和自己上下游的GPU进行进程间的梯度传递,避免了参数服务器一对多时可能出现的信息阻塞。
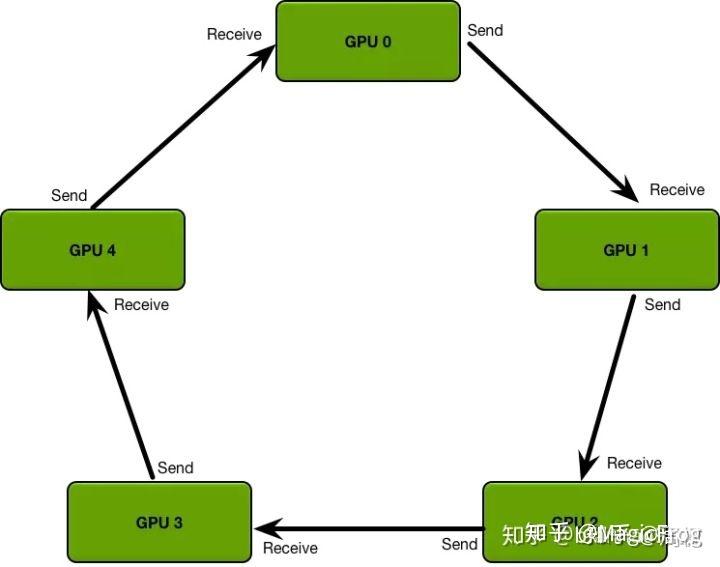
3. DistributedDataParallel示例
下面给出一个非常精简的单机多卡示例,分为六步实现单机多卡训练。
第一步,首先导入相关的包。
import argparse
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
第二步,加一个参数,local_rank。这比较好理解,相当于就是告知当前的程序跑在那一块GPU上,也就是下面的第三行代码。local_rank是通过pytorch的一个启动脚本传过来的,后面将说明这个脚本是啥。最后一句是指定通信方式,这个选nccl就行。
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend='nccl')
第三步,包装Dataloader。这里需要的是将sampler改为DistributedSampler,然后赋给DataLoader里面的sampler。
为什么需要这样做呢?因为每个GPU,或者说每个进程都会从DataLoader里面取数据,指定DistributedSampler能够让每个GPU取到不重叠的数据。
读者可能会比较好奇,在下面指定了batch_size为24,这是说每个GPU都会被分到24个数据,还是所有GPU平分这24条数据呢?答案是,每个GPU在每个iter时都会得到24条数据,如果你是4卡,一个iter中总共会处理24*4=96条数据。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
trainloader = torch.utils.data.DataLoader(my_trainset,batch_size=24,num_workers=4,sampler=train_sampler)
第四步,使用DDP包装模型。device_id仍然是args.local_rank。
model = DDP(model, device_ids=[args.local_rank])
第五步,将输入数据放到指定GPU。后面的前后向传播和以前相同。
for imgs,labels in trainloader:
imgs=imgs.to(args.local_rank)
labels=labels.to(args.local_rank)
optimizer.zero_grad()
output=net(imgs)
loss_data=loss(output,labels)
loss_data.backward()
optimizer.step()
第六步,启动训练。torch.distributed.launch就是启动脚本,nproc_per_node是GPU数。
python -m torch.distributed.launch --nproc_per_node 2 main.py
通过以上六步,我们就让模型跑在了单机多卡上。是不是也没有那么麻烦,但确实要比DataParallel复杂一些,考虑到加速效果,不妨试一试。
4. DistributedDataParallel注意点
DistributedDataParallel是多进程方式执行的,那么有些操作就需要小心了。如果你在代码中写了一行print,并使用4卡训练,那么你将会在控制台看到四行print。我们只希望看到一行,那该怎么做呢?
像下面一样加一个判断即可,这里的get_rank()得到的是进程的标识,所以输出操作只会在进程0中执行。
if dist.get_rank() == 0:
print("hah")
你会经常需要dist.get_rank()的。因为有很多操作都只需要在一个进程里执行,比如保存模型,如果不加以上判断,四个进程都会写模型,可能出现写入错误;另外load预训练模型权重时,也应该加入判断,只load一次;还有像输出loss等一些场景。
【参考】https://zhuanlan.zhihu.com/p/178402798
Pytorch分布式训练的更多相关文章
- [源码解析] 深度学习分布式训练框架 Horovod (1) --- 基础知识
[源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 目录 [源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 0x00 摘要 0x01 分布式并 ...
- [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入
[源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 目录 [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 0x00 摘要 0 ...
- [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架
[源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 目录 [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 0x00 摘要 0x01 架构图 ...
- [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构
[源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 目录 [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 0x00 摘要 0x01 ...
- [源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化 目录 [源码解析] PyTorch 分布式(9) ----- DistributedD ...
- [源码解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer静态架构
[源码解析] PyTorch 分布式(10)------DistributedDataParallel之Reducer静态架构 目录 [源码解析] PyTorch 分布式(10)------Distr ...
- [源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer
[源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer 目录 [源码解析] PyTorch 分布式(11) ----- Dis ...
- [源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播 目录 [源码解析] PyTorch 分布式(12) ----- Distribu ...
- [源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播 目录 [源码解析] PyTorch 分布式(13) ----- Distribu ...
随机推荐
- 漏洞复现:使用Kali制作木马程序
漏洞复现:使用Kali制作木马程序 攻击机:Kali2019 靶机:Win7 64位 攻击步骤: 1.打开Kali2019和Win7 64位虚拟机,确定IP地址在一个网段 2.确定好IP地址,进入Ka ...
- SQL安装
安装教程 点击传送 遇到的问题 解决方案1:
- FreeRTOS --(16)资源管理之临界区
转载自 https://blog.csdn.net/zhoutaopower/article/details/107387427 临界区的概念在任何的 SoC 都存在,比如,针对一个寄存器,基本操作为 ...
- 【位运算】剑指offer 56. 数组中数字出现的次数
这是一系列位运算的题目,本文将由浅入深,先从最简单的问题开始: 问题1: 一个数组中只有一个数字出现过1次,其余数字都出现过两次,请找到那个只出现1次的数字.要求时间复杂度是 \(O(n)\),空间复 ...
- vue - Vue路由(扩展)
忙里偷闲,还在学校,趁机把后面的路由多出来的知识点学完 十.缓存路由组件 让不展示的路由组件保持挂载,不被销毁 在我们的前面案例有一个问题,都知道vue的路由当我们切换一个路由后,另一个路由就会被销毁 ...
- java并发编程-StampedLock高性能读写锁
目录 一.读写锁 二.悲观读锁 三.乐观读 欢迎关注我的博客,更多精品知识合集 一.读写锁 在我的<java并发编程>上一篇文章中为大家介绍了<ReentrantLock读写锁> ...
- 791. Custom Sort String - LeetCode
Question 791. Custom Sort String Solution 题目大意:给你字符的顺序,让你排序另一个字符串. 思路: 输入参数如下: S = "cba" T ...
- 数仓选型必列入考虑的OLAP列式数据库ClickHouse(上)
概述 定义 ClickHouse官网地址 https://clickhouse.com/ 最新版本22.4.5.9 ClickHouse官网文档地址 https://clickhouse.com/do ...
- 负载均衡之LVS的三种模式
模式一:D-NAT模式 原理:此模式类似NAT网络中,所以此网络内主机发到互联网上的数据包的源目的IP都是NAT路由的IP,在NAT路由上做了IP替换. 把客户端发来的数据的IP头的目的地址在负载均衡 ...
- C++:制作火把
制作火把 时间限制 : 1.000 sec 内存限制 : 128 MB 题目描述: 小红最近在玩一个制作火把的游戏,一开始,小红手里有一根木棍,她希望能够通过这一根木棍通过交易换取制 ...