我的Spark学习笔记
一、架构设计
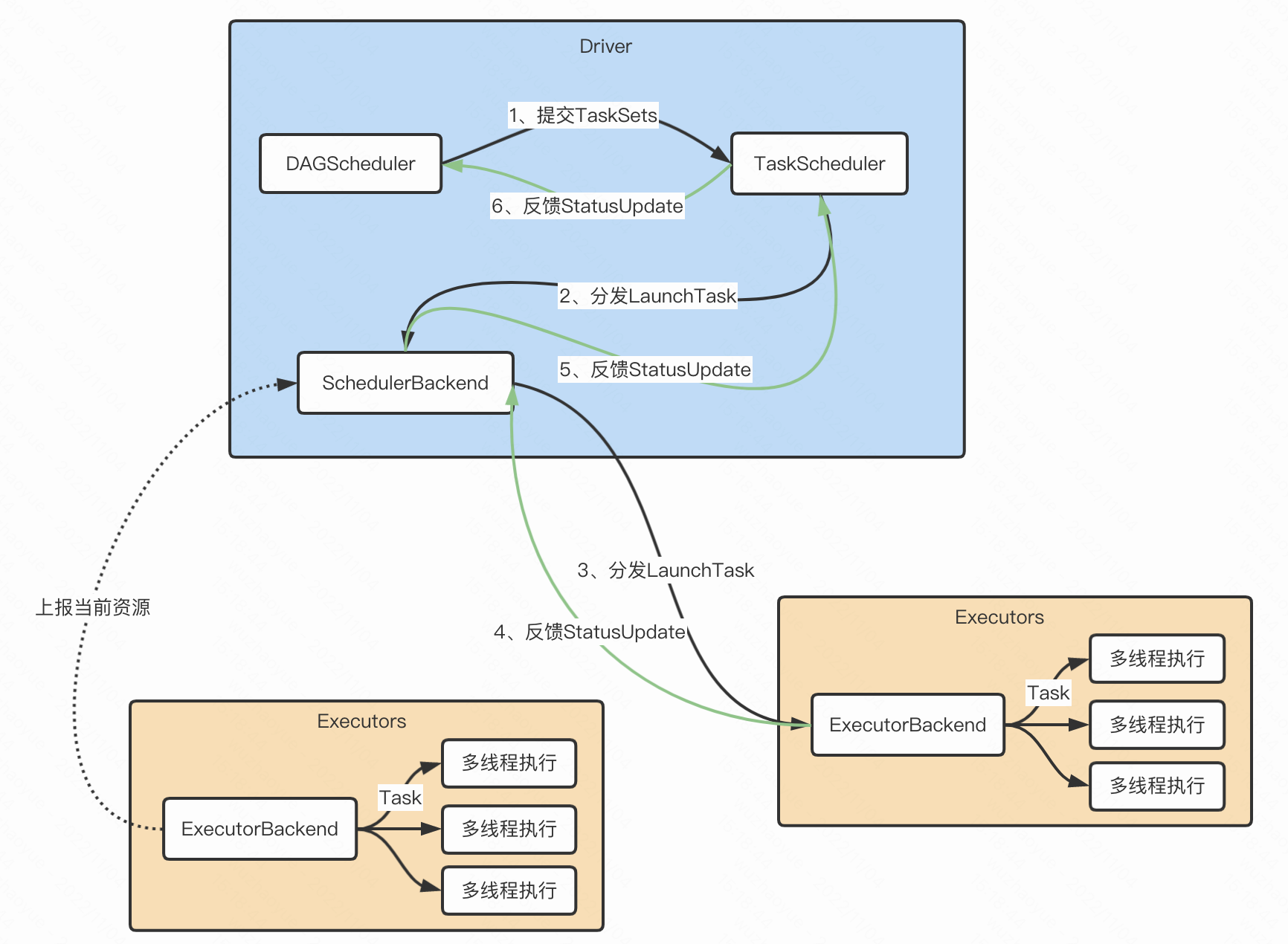
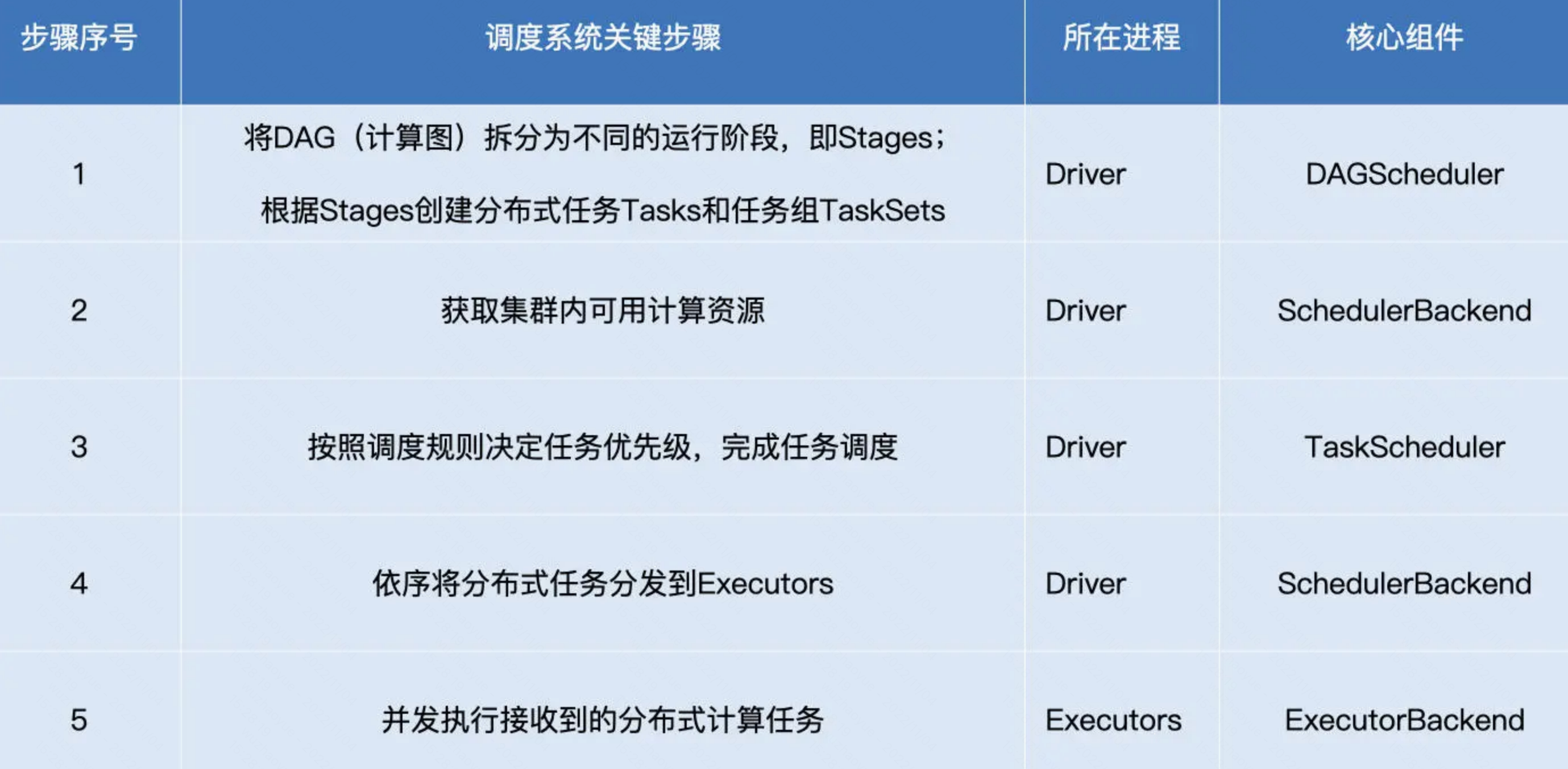
- Driver根据用户代码构建计算流图,拆解出分布式任务并分发到 Executors 中去;每个Executors收到任务,然后处理这个 RDD 的一个数据分片子集
- DAGScheduler根据用户代码构建 DAG;以 Shuffle 为边界切割 Stages;基于 Stages 创建 TaskSets,并将 TaskSets 提交给 TaskScheduler 请求调度
- TaskScheduler 在初始化的过程中,会创建任务调度队列,任务调度队列用于缓存 DAGScheduler 提交的 TaskSets。TaskScheduler 结合 SchedulerBackend 提供的 WorkerOffer,按照预先设置的调度策略依次对队列中的任务进行调度,也就是把任务分发给SchedulerBackend
- SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。会与集群内所有 Executors 中的 ExecutorBackend 保持周期性通信。SchedulerBackend收到TaskScheduler过来的任务,会把任务分发给ExecutorBackend去具体执行
- ExecutorBackend收到任务后多线程执行(一个线程处理一个Task)。处理完毕后反馈StatusUpdate给SchedulerBackend,再返回给TaskScheduler,最终给DAGScheduler
二、常用算子
2.1、RDD概念
Spark 主要以一个 弹性分布式数据集_(RDD)的概念为中心,它是一个容错且可以执行并行操作的元素的集合。有两种方法可以创建 RDD:在你的 driver program(驱动程序)中 _parallelizing 一个已存在的集合,或者在外部存储系统中引用一个数据集,例如,一个共享文件系统,HDFS,HBase,或者提供 Hadoop InputFormat 的任何数据源。
从内存创建RDD
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 从内存创建RDDobject MakeRDDFromMemory {def main(args: Array[String]): Unit = {// 准备环境val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")// 并行度,如果不设置则默认当前运行环境的最大可用核数sparkConf.set("spark.default.parallelism", "2")val sc = new SparkContext(sparkConf)// 从内存中创建RDD,将内存中集合的数据作为处理的数据源val seq = Seq[Int](1, 2, 3, 4, 5, 6)val rdd: RDD[Int] = sc.makeRDD(seq)rdd.collect().foreach(println)// numSlices表示分区的数量,不传默认spark.default.parallelismval rdd2: RDD[Int] = sc.makeRDD(seq, 3)// 将处理的数据保存成分区文件rdd2.saveAsTextFile("output")sc.stop()}}
从文件中创建RDD
import org.apache.spark.{SparkConf, SparkContext}// 从文件中创建RDD(本地文件、HDFS文件)object MakeRDDFromTextFile {def main(args: Array[String]): Unit = {// 准备环境val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)// 从文件中创建RDD,将文件中的数据作为处理的数据源// path路径默认以当前环境的根路径为基准。可以写绝对路径,也可以写相对路径//val rdd: RDD[String] = sc.textFile("datas/1.txt")// path路径可以是文件的具体路径,也可以目录名称//val rdd = sc.textFile("datas")// path路径还可以使用通配符 *//val rdd = sc.textFile("datas/1*.txt")// path还可以是分布式存储系统路径:HDFSval rdd = sc.textFile("hdfs://localhost:8020/test.txt")rdd.collect().foreach(println)sc.stop()}}
2.2、常用算子
map算子:数据转换
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// map算子object map {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4))// 转换函数def mapFunction(num: Int): Int = {num * 2}// 多种方式如下// val mapRDD: RDD[Int] = rdd.map(mapFunction)// val mapRDD: RDD[Int] = rdd.map((num: Int) => {// num * 2// })// val mapRDD: RDD[Int] = rdd.map((num: Int) => num * 2)// val mapRDD: RDD[Int] = rdd.map((num) => num * 2)// val mapRDD: RDD[Int] = rdd.map(num => num * 2)val mapRDD: RDD[Int] = rdd.map(_ * 2)mapRDD.collect().foreach(println)sc.stop()}}
mapPartitions算子:数据转换(分区批处理)
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** mapPartitions VS map** map 传入的是分区中的每个元素,是对每个元素就进行一次转换和改变,但不会减少或增多元素* mapPartitions 传入的参数是Iterator返回值也是Iterator,所传入的计算逻辑是对一个Iterator进行一次运算,可以增加或减少元素*** Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高。* 但是 mapPartitions 算子会长时间占用内存,这样会导致内存OOM。而map会在内存不够时进行GC。** 详细参考 https://blog.csdn.net/AnameJL/article/details/121689987*/object mapPartitions {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)// mapPartitions: 可以以分区为单位进行数据转换操作,但是会将整个分区的数据加载到内存进行引用。// 在内存较小,数据量较大的场合下,容易出现内存溢出。val mpRDD: RDD[Int] = rdd.mapPartitions(iter => {println("批处理当前分区数据")iter.map(_ * 2)})mpRDD.collect().foreach(println)sc.stop()}}
mapPartitionsWithIndex算子:分区索引 + 数据迭代器
import org.apache.spark.{SparkConf, SparkContext}// 分区索引object mapPartitionsWithIndex {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)val mpiRDD = rdd.mapPartitionsWithIndex(//(分区索引, 数据迭代器)(index, iter) => {println("index:" + index, "iter[" + iter.mkString(",") + "]")})mpiRDD.collect().foreach(println)sc.stop()}}
flatMap算子:数据扁平化
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射object flatMap {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4)))// 多个list合并成一个listval flatRDD: RDD[Int] = rdd.flatMap(list => list)flatRDD.collect().foreach(println)sc.stop()}}
glom算子:分区内数据合并
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变object glom {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)// 把每一个分区内数据合并成Arrayval glomRDD: RDD[Array[Int]] = rdd.glom()glomRDD.collect().foreach(array => {println(array.mkString(","))})sc.stop()}}
groupBy算子:数据分组
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。// 极限情况下,数据可能被分在同一个分区中一个组的数据在一个分区中,但是并不是说一个分区中只有一个组,分组和分区没有必然的关系object groupBy {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)// groupBy会将数据源中的每一个数据进行分组判断,根据返回的分组key进行分组,相同的key值的数据会放置在一个组中// val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(num => num % 2)val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(_ % 2)groupRDD.collect().foreach(println)sc.stop()}}
filter算子:数据过滤
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。// 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。object filter {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4))val filterRDD: RDD[Int] = rdd.filter(num => num % 2 != 0)filterRDD.collect().foreach(println)sc.stop()}}
sample算子:数据采样随机抽取
import org.apache.spark.{SparkConf, SparkContext}// 根据指定的规则从数据集中抽取数据object sample {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val dataRDD = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 1)// 抽取数据不放回(伯努利算法)// 伯努利算法:又叫 0、 1 分布。例如扔硬币,要么正面,要么反面。// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要// 第一个参数:抽取的数据是否放回, false:不放回// 第二个参数:抽取的几率,范围只能在[0,1]之间,0:全不取; 1:全取;// 第三个参数:随机数种子val dataRDD1 = dataRDD.sample(false, 0.5)// 抽取数据放回(泊松算法)// 第一个参数:抽取的数据是否放回, true:放回; false:不放回// 第二个参数:重复数据的几率,范围大于等于0,可以大于1 表示每一个元素被期望抽取到的次数// 第三个参数:随机数种子// 例如数据集内有10个,fraction为1的话抽取10个, 0.5的话抽取5个,2的话抽取20个val dataRDD2 = dataRDD.sample(true, 2)println(dataRDD1.collect().mkString(","))println(dataRDD2.collect().mkString(","))sc.stop()}}
distinct算子:数据去重
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object distinct {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))val rdd1: RDD[Int] = rdd.distinct()val rdd2: RDD[Int] = rdd.distinct(2)// 底层相当于这样写val rdd3 = rdd.map(x => (x, null)).reduceByKey((x, _) => x).map(_._1)println(rdd.collect().mkString(","))println(rdd1.collect().mkString(","))println(rdd2.collect().mkString(","))println(rdd3.collect().mkString(","))sc.stop()}}
coalesce算子:数据(shuffle可选)重新分区
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率* 当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本*/object coalesce {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)// 默认3个分区val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)// coalesce方法默认情况下不会将分区的数据打乱重新组合,默认shuffer=false// 这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜,如果想要让数据均衡,可以进行shuffle处理// 缩减成2个分区并shufferval newRDD: RDD[Int] = rdd.coalesce(2, true)newRDD.saveAsTextFile("output")sc.stop()}}
repartition算子:数据shuffle重新分区
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。* 无论是将分区数多的RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,* repartition操作都可以完成,因为无论如何都会经 shuffle 过程。* 直接用repartition就行,coalesce就别用了*/object repartition {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 3)// coalesce算子可以扩大分区的,但是如果不进行shuffle操作,是没有意义,不起作用。// 所以如果想要实现扩大分区的效果,需要使用shuffle操作/*** 底层就是coalesce* def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {* coalesce(numPartitions, shuffle = true)* }*/// 缩减分区val newRDD1: RDD[Int] = rdd.repartition(2)// 扩大分区val newRDD2: RDD[Int] = rdd.repartition(4)rdd.saveAsTextFile("output0")newRDD1.saveAsTextFile("output1")newRDD2.saveAsTextFile("output2")sc.stop()}}
sortBy算子:数据排序
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。* 排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。 中间存在shuffle的过程。*/object sortBy {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)// 例子1val rdd = sc.makeRDD(List(6, 2, 4, 5, 3, 1), 2)val newRDD: RDD[Int] = rdd.sortBy(n => n)println(newRDD.collect().mkString(","))newRDD.saveAsTextFile("output")// 例子2val rdd2 = sc.makeRDD(List(("1", 1), ("3", 2), ("2", 3)), 2)// sortBy方法可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式// sortBy默认情况下,不会改变分区。但是中间存在shuffle操作val newRDD1 = rdd2.sortBy(t => t._1.toInt, false) // 降序val newRDD2 = rdd2.sortBy(t => t._1.toInt, true) // 升序newRDD1.collect().foreach(println)newRDD2.collect().foreach(println)sc.stop()}}
intersection union subtract zip:两个数据源 交 并 差 拉链
/*** 两个数据源 交 并 差 拉链*/object intersection_union_subtract_zip {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)// 交集,并集和差集要求两个数据源数据类型保持一致val rdd1 = sc.makeRDD(List(1, 2, 3, 4))val rdd2 = sc.makeRDD(List(3, 4, 5, 6))// 交集 : 【3,4】val rdd3: RDD[Int] = rdd1.intersection(rdd2)println(rdd3.collect().mkString(","))// 并集 : 【1,2,3,4,3,4,5,6】val rdd4: RDD[Int] = rdd1.union(rdd2)println(rdd4.collect().mkString(","))// 差集 : 【1,2】val rdd5: RDD[Int] = rdd1.subtract(rdd2)println(rdd5.collect().mkString(","))// 拉链 : 【1-3,2-4,3-5,4-6】val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)println(rdd6.collect().mkString(","))// 拉链操作两个数据源的类型可以不一致,但要求分区中数据数量保持一致val rdd7 = sc.makeRDD(List("a", "b", "c", "d"))val rdd8 = rdd1.zip(rdd7)println(rdd8.collect().mkString(","))sc.stop()}}
partitionBy算子:数据按照指定规则重新进行分区
import org.apache.spark.rdd.RDDimport org.apache.spark.{HashPartitioner, SparkConf, SparkContext}/*** partitionBy:数据按照指定规则重新进行分区。Spark 默认的分区器是 HashPartitioner* repartition coalesce:将分区增加或缩小,数据是无规则的*/object partitionBy {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)// PairRDDFunctions才支持partitionBy,所以需要先转换成mapRDDval mapRDD: RDD[(Int, Int)] = rdd.map(num => (num, 1))// partitionBy根据指定的分区规则对数据进行重分区val newRDD = mapRDD.partitionBy(new HashPartitioner(2))newRDD.partitionBy(new HashPartitioner(2))newRDD.saveAsTextFile("output")sc.stop()}}
reduceByKey算子:按相同key聚合
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 可以将数据按照相同的 Key 对 Value 进行聚合*/object reduceByKey {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)))// reduceByKey : 相同的key的数据进行value数据的聚合操作// scala语言中一般的聚合操作都是两两聚合,spark基于scala开发的,所以它的聚合也是两两聚合// reduceByKey中如果key的数据只有一个,是不会参与运算的。val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey((x: Int, y: Int) => {println(s"x = ${x}, y = ${y}")x + y})reduceRDD.collect().foreach(println)sc.stop()}}
groupByKey算子:根据key对数据分组
import org.apache.spark.rdd.RDDimport org.apache.spark.{HashPartitioner, SparkConf, SparkContext}/*** 将数据源的数据根据 key 对 value 进行分组*** reduceByKey 和 groupByKey的区别?** 从 shuffle 的角度: reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey* 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量。* 而 groupByKey 只是进行分组,不存在数据量减少的问题, reduceByKey 性能比较高。** 从功能的角度: reduceByKey 其实包含分组和聚合的功能。 groupByKey 只能分组,不能聚合。* 所以在分组聚合的场合下,推荐使用 reduceByKey。如果仅仅是分组而不需要聚合,那么还是只能使用 groupByKey。*/object groupByKey {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)))// groupByKey : 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组// 元组中的第一个元素就是key,// 元组中的第二个元素就是相同key的value的集合val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()groupRDD.collect().foreach(println)val groupRDD2: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)groupRDD2.collect().foreach(println)val groupRDD3 = rdd.groupByKey(2)val groupRDD4 = rdd.groupByKey(new HashPartitioner(2))sc.stop()}}
aggregateByKey算子:将数据根据不同的规则进行分区内计算和分区间计算
import org.apache.spark.{SparkConf, SparkContext}/*** 将数据根据不同的规则进行分区内计算和分区间计算**/object aggregateByKey {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)), 2)// aggregateByKey存在函数柯里化,有两个参数列表// 第一个参数列表,需要传递一个参数,表示为初始值// 主要用于当碰见第一个key的时候,和value进行分区内计算// 第二个参数列表需要传递2个参数// 第一个参数表示分区内计算规则// 第二个参数表示分区间计算规则// 取出每个分区内相同key的最大值 然后分区间相加rdd.aggregateByKey(0)((x, y) => math.max(x, y), (x, y) => x + y).collect.foreach(println)sc.stop()}}
foldByKey算子:和aggregateByKey类似
import org.apache.spark.{SparkConf, SparkContext}/*** 当分区内计算规则和分区间计算规则相同时,aggregateByKey就可以简化为foldByKey*/object foldByKey {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3),("b", 4), ("b", 5), ("a", 6)), 2)// rdd.aggregateByKey(0)(_+_, _+_).collect.foreach(println)// 如果聚合计算时,分区内和分区间计算规则相同,spark提供了简化的方法,用下面的替换上面的rdd.foldByKey(0)(_ + _).collect.foreach(println)sc.stop()}}
combineByKey算子:和aggregateByKey类似
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。* 类似于aggregate(), combineByKey()允许用户返回值的类型与输入不一致。*/object combineByKey {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3),("b", 4), ("b", 5), ("a", 6)), 2)// combineByKey : 方法需要三个参数// 第一个参数表示:将相同key的第一个数据进行结构的转换,实现操作// 第二个参数表示:分区内的计算规则// 第三个参数表示:分区间的计算规则val newRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(v => (v, 1),(t: (Int, Int), v) => {(t._1 + v, t._2 + 1)},(t1: (Int, Int), t2: (Int, Int)) => {(t1._1 + t2._1, t1._2 + t2._2)})val resultRDD: RDD[(String, Int)] = newRDD.mapValues {case (num, cnt) => {num / cnt}}resultRDD.collect().foreach(println)sc.stop()}}
reduceByKey、 foldByKey、 aggregateByKey、 combineByKey 的区别
reduceByKey: 相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同foldByKey: 相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同aggregateByKey:相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同combineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构,分区内和分区间计算规则不相同
join算子:相同key连接
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD*/object join {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd1 = sc.makeRDD(List(("a", 1), ("a", 2), ("c", 3), ("b", 3)))val rdd2 = sc.makeRDD(List(("a", 5), ("c", 6), ("a", 4)))// join : 两个不同数据源的数据,相同的key的value会连接在一起,形成元组// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)joinRDD.collect().foreach(println)sc.stop()}}
leftOuterJoin rightOuterJoin:左外连接 右外连接
import org.apache.spark.{SparkConf, SparkContext}/*** 左外连接 右外连接*/object leftOuterJoin_rightOuterJoin {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2) //, ("c", 3)))val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))val leftJoinRDD = rdd1.leftOuterJoin(rdd2)val rightJoinRDD = rdd1.rightOuterJoin(rdd2)leftJoinRDD.collect().foreach(println)rightJoinRDD.collect().foreach(println)sc.stop()}}
cogroup算子:分组 连接
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** 分组 连接*/object cogroup {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2) //, ("c", 3)))val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6), ("c", 7)))// cogroup : connect + group (分组,连接)val cgRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)cgRDD.collect().foreach(println)sc.stop()}}
参考资料:Spark中文文档尚硅谷Spark教程
我的Spark学习笔记的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
随机推荐
- CF1511G Chips on a Board (倍增)
题面 原题题面 转化方便版题意: 有 n n n 堆石子,第 i i i 堆有 c i ∈ [ 1 , m ] c_i\in [1,m] ci∈[1,m] 个石子,有 q q q 次询问,每次询问给 ...
- 2020/12/9 酒etf
2020/12/9 2.315建仓酒etf,之后陆续加仓,拿到年底看看 2020/12/12 2.36卖出部分,目前成本2.106,盈利百分之9.449,白酒应该是没问题,但感觉年前应该有波调整. 2 ...
- 第七十三篇:解决Vue组件中的样式冲突
好家伙, 1.组件之间的样式冲突 默认情况下,写在.vue组件中的样式会全局生效,因此很容易造成多个组件之间的样式冲突问题. 举个例子: 我们在Left.vue的组件中添加样式 <templat ...
- java 类名后加变量名是什么意思?
回答这个问题我们需要先了解两个事情: A是一个类,我们如果对他进行实例化,需要这样写: A a = new A(); 详细解释一下这个语句,首先等号左边做的事情:在JVM栈内存(stack)中定义了一 ...
- [Python]-string-字符串
字符串是Python中很常用的数据类型,此处记录一些典型用法并随时更新. split()方法 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串. 两个参数st ...
- MySQL DDL执行方式-Online DDL介绍
1 引言 大家好,今天与大家一起分享一下 mysql DDL执行方式. 一般来说MySQL分为DDL(定义)和DML(操作). DDL:Data Definition Language,即数据定义语言 ...
- ProxySQL(5):线程、线程池、连接池
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9281909.html ProxySQL的线程 ProxySQL由多个模块组成,是一个多线程的daemon类程 ...
- 通过堡垒机上传文件报错ssh:没有权限的问题
背景描述 一台有公网IP的主机安装的有jumpserver,假设为A主机,另外几台没有公网ip的主机,假设其中一个为B主机. 操作 1.通过主机A的公网IP和端口等登录到jumpserver的管理员用 ...
- 不停机为虚拟机添加主机磁盘(以VMware Workstation为例)
VMware Workstation软件上安装的centos7系统,新增磁盘后使用fdisk -l命令查看不到新增的磁盘,有没有办法在不重启的情况下添加上新磁盘? 有办法 具体如下: # 查看主机总线 ...
- k8s上安装安装 Ingress Controller &卸载
在 master 节点上执行 nginx-ingress.yaml文件内容 # 如果打算用于生产环境,请参考 https://github.com/nginxinc/kubernetes-ingres ...