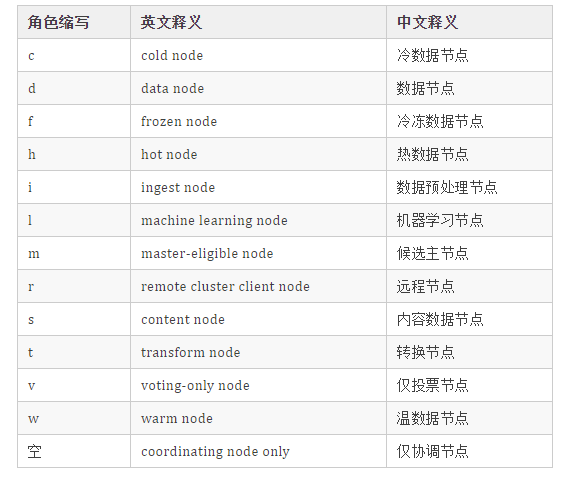
Elasticsearch 8.X 节点角色划分深入详解
文章转载自: https://mp.weixin.qq.com/s/3486iH3VH7TV6lza-a7adQ
0、问题引出
如果你的 Elasticsearch 集群是 7.9 之前的版本,在配置节点的时候,只会涉及节点类型的概念。我相信大家会对下面的概念比较熟悉:
- 主节点
- 数据节点
- 协调节点
- Ingest 节点
- 冷热集群架构
Elasticsearch 7.9 版本引入了节点角色的概念。最近社群小伙伴关于节点角色提了不少问题,列举如下:
- Q1:请问 Nginx + ES Coordinate + ES Master + ES Node 如何安装配置呢?是否安装一样,只需更改节点角色即可?
- Q2:ES部署上,node.role都是mdi和 node.role区分m、d、i ,在部署上各有什么优势?更推荐用哪种?
- Q3:有 ES 7.x 的集群角色如图,请问在写入海量数据时,应该连接什么角色的节点写入?专用协调节点还是数据节点?
- Q4:role的配置,加上这些data_hot, data_warm, data_cold 和自定义的attr属性有区别吗?
- Q5:谁能解释一下es的角色 data data_content data_hot/warm/cold他们直接的关系?
- Q6:请问 ES 7.10 的 data_content 角色是个什么样的存在?和协调节点什么区别?
带着这些问题,我们开始 Elasticsearch 节点角色的解读。
1、什么是 Elasticsearch 节点角色?

Elasticsearch 7.9 之前的版本中的节点类型:数据节点、协调节点、候选主节点、ingest 节点,在 Elasticsearch 7.9 以及之后 版本中有了升级,升级了什么呢?
节点类型升级为节点角色(Node roles)。节点角色分的很细:数据节点角色、主节点角色、ingest节点角色、热节点角色等。
在 Elasticsearch 集群中,每个启动的 Elasticsearch 进程都可以叫做一个节点。集群中只有一个节点的时候,以 Elasticsearch 8.1.3 版本单节点集群为例,如果我们不手动设置节点角色,默认节点角色如下“红框”所示:

GET _cat/nodes?v
# 返回结果
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.21.0.14 70 96 0 0.03 0.03 0.05 cdfhilmrstw * VM-0-14-centos
当集群中有多个节点角色的时候,就需要手动设定、配置节点的角色。
节点角色划分的目的在于:不同角色的节点各司其职,共同确保集群的功能的稳定和性能的高可用。
如上截图中的 “cdfhilmrstw”,我第一次看到这个串也是一脸懵逼,解释一下,你就“豁然开朗”。
2、为什么引入节点角色?节点类型不香吗?
https://github.com/elastic/elasticsearch/pull/54998
一个新功能的诞生必然是基于早期版本存在bug或者至少用户体验差。
节点角色就是基于节点类型配置复杂和用户体验差应运而生的。
早期版本如果需要配置仅候选主节点类型,需要的配置(极端情况)如下:
node.data: false
node.ingest: false
node.remote_cluster_client: false
node.ml: false
node.master: true
node.transform: false
node.voting_only: false
这是非常繁琐的配置,类似我要说我自己是主节点,需要我先说明我不是数据节点、不是 Ingest 预处理节点、不是机器学习节点、不是XXX各种节点.....
而节点角色的出现“革命性”的结局了这个问题,如下所示,只需要说明我是某某某,而不需要费劲巴拉的解释我不是某某某。
node.roles: [ data, master ]
3、不同角色节点的功能详解
3.1 主节点(Master-eligible node)
主节点的核心用途:集群层面的管理,例如创建或删除索引、跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。主节点的path.data 用于存储集群元数据信息,不可缺少。
主节点的重要性:拥有稳定的主节点对于集群健康非常重要。
和早期版本不同,节点角色划分后,主节点又被细分为:候选主节点和仅投票主节点。
- 主节点存储数据:集群中每个索引的索引元数据,集群层面的元数据。
3.1.1 专用候选主节点(Dedicated master-eligible node)
如果集群规模大、节点多之后,有必要独立设置专用候选主节点。
专用候选主节点配置:
node.roles: [ master ]
3.1.2 仅投票主节点(Voting-only master-eligible node)
用途:仅投票,不会被选为主节点。
硬件配置可以较专用候选主节点低一些。
仅投票主节点配置:
node.roles: [ master, voting_only ]
注意:master 必不可少。
关于集群主节点配置,要强调说明如下:
- 高可用性 (HA) 集群需要至少三个符合主节点资格的节点;其中至少两个不是仅投票节点。
- 即使其中一个节点发生故障,这样的集群也将能够选举一个主节点。
3.2 数据节点(Data node)
数据节点用途:数据落地存储、数据增、删、改、查、搜索、聚合操作等处理操作。
数据节点硬件配置:CPU 要求高、内存要求高、磁盘要求高。
专属数据节点好处:主节点和数据节点分离,各司其职。
数据节点存储内容
- 分片数据。
- 每个分片对应的元数据。
- 集群层面的元数据,如:setting 和 索引模板。
拥有专用数据节点的主要好处是主角色和数据角色的分离。
数据节点的配置:
node.roles: [ data ]
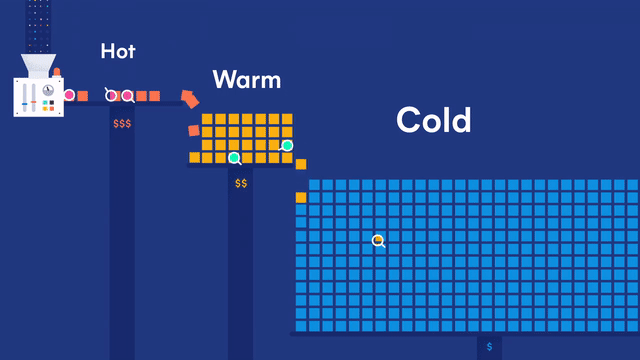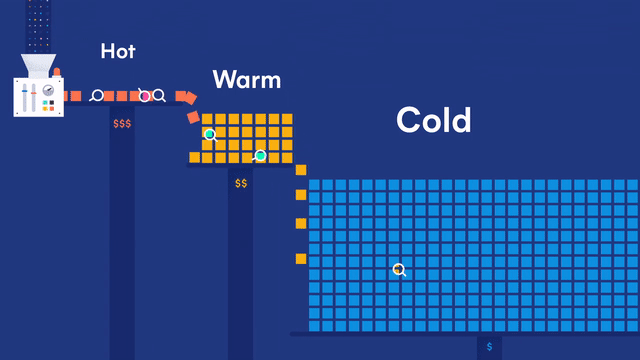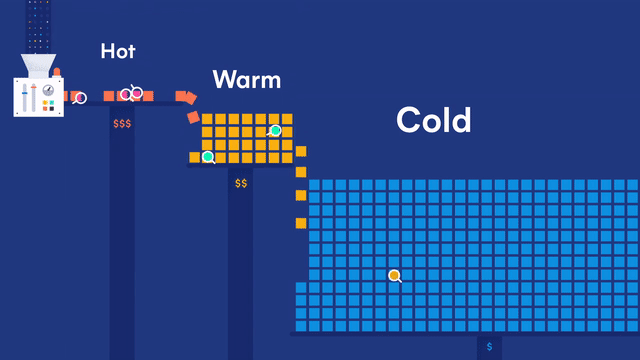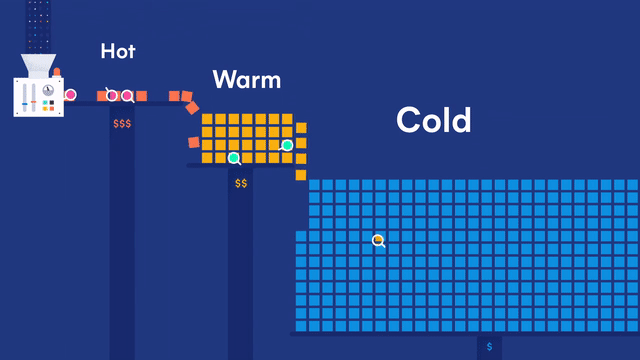
在 Elastic 多层(tires)冷热集群架构体系下,数据节点又可以细分为:
- 内容数据节点(Content data node)
- 热数据节点(Hot data node)
- 温数据节点(Warm data node)
- 冷数据节点(Cold data node)
- 冷冻数据节点(Frozen data node)
3.2.1 内容数据节点
用途:处理写入和查询负载,具有较长的数据保留要求。
建议至少设置一个副本,以保证数据的高可用。
不属于数据流的系统索引或其他索引会自动分配到内容数据节点。
node.roles: [ data_content ]
3.2.2 热数据节点
用途:保存最近、最常访问的时序数据。
推荐使用:SSD 磁盘,至少设置一个副本。
node.roles: [ data_hot ]
3.2.3 温数据节点
用途:保存访问频次低且很少更新的时序数据。
node.roles: [ data_warm ]
3.2.4 冷数据节点
用途:保存不经常访问且通常不更新的时序数据。可存储可搜索快照。
node.roles: [ data_cold ]
3.2.5 冷冻数据节点
用途:保存很少访问且从不更新的时序数据。
node.roles: [ data_frozen ]
在冷热集群架构时序数据 ILM 索引生命周期管理的实战演练环节,验证发现:
在配置节点角色时,data_hot、data_warm、data_cold 要和 data_content 要一起配置。且 data_hot、data_warm、data_cold 不要和原有的data 节点一起配置了。
如果仅data_hot 不设置 data_content 会导致集群数据写入后无法落地。
我的理解:data_hot, data_warm, data_cold 是标识性的节点,实际落地存储还得靠 data_content 角色。
3.3 数据预处理节点(ingest node)
用途:执行由预处理管道组成的预处理任务。
node.roles: [ ingest ]
3.4 仅协调节点(Coordinating only node)
用途:类似智能负载均衡器,负责:路由分发请求、聚集搜索或聚合结果。
注意事项:在一个集群中添加太多的仅协调节点会增加整个集群的负担,因为当选的主节点必须等待来自每个节点的集群状态更新的确认。
node.roles: [ ]
空即是“色”,不对,这里空即是“仅协调节点”。
3.5 远程节点(Remote-eligible node)
用途:跨集群检索或跨集群复制。
node.roles: [ remote_cluster_client ]
3.6 机器学习节点(Machine learning node)
用途:机器学习,系收费功能。
node.roles: [ ml, remote_cluster_client]
3.7 转换节点(Transform node)
用途:运行转换并处理转换 API 请求。这块,咱们之前文章没有涉及。
推荐阅读:https://www.elastic.co/guide/en/elasticsearch/reference/current/transform-overview.html
node.roles: [ transform, remote_cluster_client ]
4、回答开篇问题
4.1 Q1:请问 Nginx + ES Coordinate + ES Master + ES Node 如何安装配置呢?是否安装一样,只需更改节点角色即可?
答案:先划分节点角色。节点不多的话手动one by one 部署(部署好了一个,其他的拷贝后修改角色、ip等就可以),节点非常多的话可以借助:ansible 等脚本工具快速部署。
4.2 Q2:ES部署上,node.role都是mdi和 node.role区分m、d、i ,在部署上各有什么优势?更推荐用哪种?
答案:本文已介绍。m 代表主节点 master, d 代表数据节点 data, i 代表数据预处理节点 ingest。
4.3 Q3:有 ES 7.x 的集群角色如图,请问在写入海量数据时,应该连接什么角色的节点写入?专用协调节点还是数据节点?
答案:看节点规模和节点角色划分,如果已经有了独立协调节点,连接独立协调节点。如果没有,连接硬件配置高的节点。
4.4 Q4:role的配置,加上这些data_hot, data_warm, data_cold 和自定义的attr属性有区别吗?
答案:新版本新特性,有区别,新的方式配置更为简洁,可读性强、用户体验优。
4.5 Q5:谁能解释一下es的角色 data data_content data_hot/warm/cold他们直接的关系?
答案:系冷热集群架构的数据节点的分层处理机制。相当于早期版本冷热集群架构的手动配置节点属性的部分,高版本做了精细切分,使得数据冷热集群管理更为高效。尤其默认迁移(migrate )自动实现机制,之前版本的分片分配策略手动配置变得不再必须:
"allocate" : {
"include" : {
"box_type": "hot,warm"
}
}
4.6 Q6:请问 ES 7.10 的 data_content 角色是个什么样的存在?和协调节点什么区别?
答案:两种完全不同的节点。data_content 属于数据节点,永久存储数据的地方。而协调节点是用来请求路由分发、结果汇聚处理的。
5、小结
有了节点角色划分之后,老版本的节点类型配置还是支持的。最早使用节点角色做 ILM 索引生命周期管理还有点不适应,摸索了一小段时间。
但,我们得拥抱 Elasticsearch 的变化。
节点角色的划分是用户体验层面、功能层面的改进,有了它,我们节点划分会更加明晰,节点用途会更加聚焦、具体。
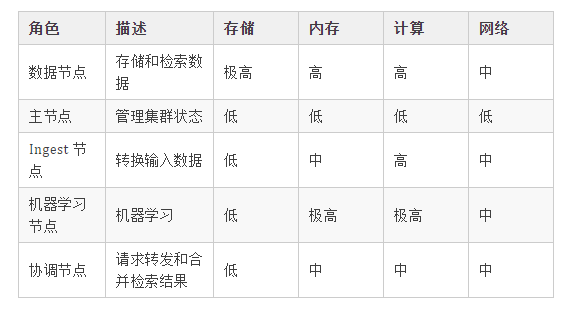
关于节点角色和硬件配置的关系,也是经常被提问的问题,推荐配置参考:
Elasticsearch 8.X 节点角色划分深入详解的更多相关文章
- 刨根问底 | Elasticsearch 5.X集群多节点角色配置深入详解【转】
转自:https://blog.csdn.net/laoyang360/article/details/78290484 1.问题引出 ES5.X节点类型多了ingest节点类型. 针对3个节点.5个 ...
- Elasticsearch之settings和mappings(图文详解)
Elasticsearch之settings和mappings的意义 简单的说,就是 settings是修改分片和副本数的. mappings是修改字段和类型的. 记住,可以用url方式来操作它们,也 ...
- apache-storm-1.0.2.tar.gz的集群搭建(3节点)(图文详解)(非HA和HA)
不多说,直接上干货! Storm的版本选取 我这里,是选用apache-storm-1.0.2.tar.gz apache-storm-0.9.6.tar.gz的集群搭建(3节点)(图文详解) 为什么 ...
- RocketMQ——角色与术语详解
原文地址:http://jaskey.github.io/blog/2016/12/15/rocketmq-concept/ RocketMQ——角色与术语详解 2016-12-15 THU 15:4 ...
- ELK & ElasticSearch 5.1 基础概念及配置文件详解【转】
转自:https://blog.csdn.net/zxf_668899/article/details/54582849 配置文件 基本概念 接近实时NRT 集群cluster 索引index 文档d ...
- Elasticsearch前沿:ES 5.x改进详解与ES6展望
转:http://www.dataguru.cn/article-11094-1.html 曾勇(Medcl),Elastic 工程师与布道师,2015 年加入 Elastic 公司.加入 Elast ...
- CentOS6.5下nginx-1.8.1.tar.gz的单节点搭建(图文详解)
不多说,直接上干货! [hadoop@djt002 local]$ su root Password: [root@djt002 local]# ll total drwxr-xr-x. root r ...
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
前言 在上一篇中介绍了ElasticSearch集群和kinaba的安装教程,本篇文章就来讲解下 ElasticSearch的DSL语句使用. ElasticSearch DSL 介绍 Elastic ...
- elasticsearch ik中文分词器的使用详解
(基于es5.4)先喵几眼github,按照步骤安装好分词器 link:https://github.com/medcl/elasticsearch-analysis-ik 复习一下常用的操作 .查看 ...
随机推荐
- Python实现哈希表(分离链接法)
一.python实现哈希表 只使用list,构建简单的哈希表(字典对象) # 不使用字典构造的分离连接法版哈希表 class HashList(): """ Simple ...
- OneOS家族,LITE版小兄弟诞生了!
号外,号外!OneOS-Lite诞生啦!前有大哥OneOS,以及一众优秀的RTOS,正所谓珠玉在前,我很难啊.但我可不能怂,大哥叫小O,我就叫小L,站在大哥的肩上,小小L也有发光发热的机会. 小L代码 ...
- Proxmox6.2简单配置
刻录: 使用rufus+GPT+DD方式写入U盘 一.更换国内源: 1)删除企业源 mv /etc/apt/sources.list.d/pve-enterprise.list /etc/apt/so ...
- 基于图的广度优先搜索策略(耿7.11)--------西工大noj.20
目录 代码 代码 #include <stdio.h> #include <stdlib.h> #include <string.h> typedef struct ...
- 同时安装py2和py3-安装多版本python
遇到问题和需求 我的电脑环境:先安装py2再安装py3,平时我工作中是使用python2,如何保证两个版本共存且让代码来选择要使用的版本. 遇到问题 在cmd中输入python,进入的是py2的环境, ...
- 性能浪费的日志案例和使用Lambda优化日志案例
有些场景的代码执行后,结果不一定会被使用,从而造成性能浪费.而Lambda表达式是延迟执行的,这正好可以作为解决方案,提升性能 性能浪费的日志案例 日志可以帮助我们快速的定位问题,记录程序运行过程中的 ...
- 解决线程安全问题_同步方法和解决线程安全问题_Lock锁
解决线程安全问题_同步方法 package com.yang.Test.ThreadStudy; import lombok.SneakyThrows; /** * 卖票案例出现了线程安全的问题 * ...
- 【原创】Python 使用jmpy模块加密|加固 python代码
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! 使用jmpy模块 将py文件加密为so或 ...
- BS架构与CS架构
BS与CS的区别:1.BS是标准规范的,CS的协议自定义:2.BS核心运算都在服务器端,CS客户端和服务器端都可以运算:3.BS只需要部署服务器端,CS需要同时升级客户端和服务器端. CS(Clien ...
- 多线程与高并发(五)—— 源码解析 ReentrantLock
一.前言 ReentrantLock 是基于 AQS 实现的同步框架,关于 AQS 的源码在 这篇文章 已经讲解过,ReentrantLock 的主要实现都依赖AQS,因此在阅读本文前应该先了解 AQ ...