C语言之走迷宫深度和广度优先(利用堆栈和队列)

完成以下迷宫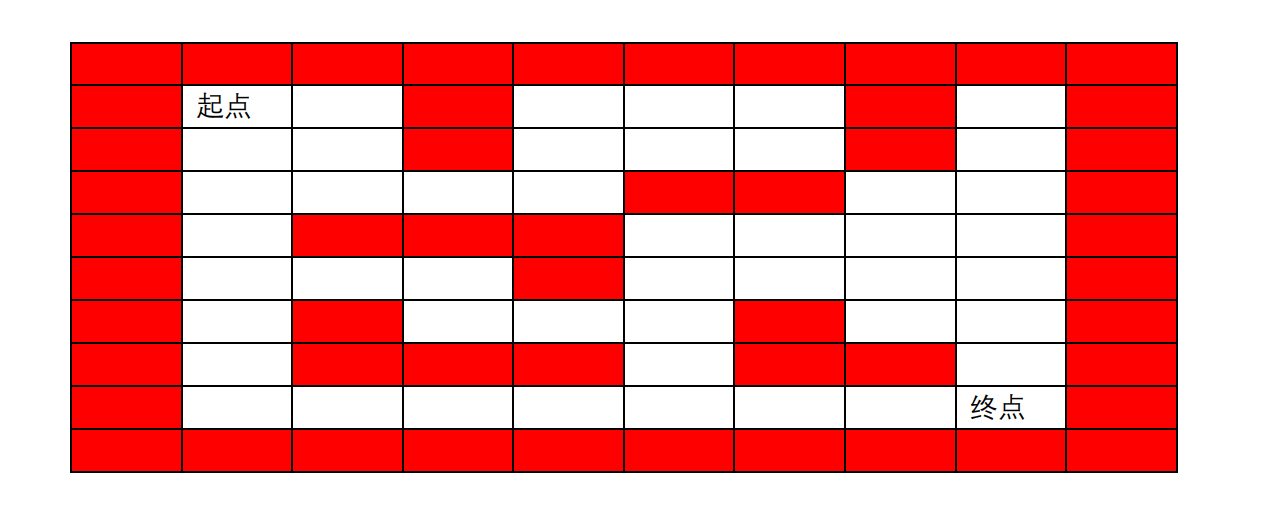
利用二维数组储存每一个数组里的值,若是不能走则为1,若是可行就是0,走过了就设为2。
一般是再复制一个数组,用来记录。
堆栈的思想就是将一个点的上下左右都遍历一遍,若可行进栈,跳出遍历,再寻找下一个可走的。若遇到无路可走的就退回上一步,就是出栈。所以就是说堆栈里记录的是可以走到终点的路。
队列的思想就是一直找,把所有可以走的路都走一遍,直到遇到终点。
这里的每一个可以走的点都为链表中的一个节点,在队列中要记录这个点的上一点是什么,就是哪一个点衍生出的这个点。
若是堆栈,最后在出栈便是所走的路径,但是堆栈是后进先出的原理,可能为了好看最后要做些处理。
若是队列,最后是利用找到的终点的那个节点,一直找这个节点的上一个节点,上个节点的上个节点,一直找到起点,可能为了好看最后还是要做些处理。
这里就是按照上述方法做的,但是太懒了,做出来就没有处理了。
堆栈是比较简单的,主要是队列中的头部和尾部的节点设置,和进队列的时候是怎么循环,这个循环是怎么在遍历之前的节点的也同时在加入新的节点进队。后来我是没有用出队这个原理去做。
以下是用堆栈实现的
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
typedef struct stack{
int x;//记录下标
int y;
int direction;//记录方向
struct stack *next;
}stack;
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
//这里是输进去的迷宫,也可以随机实现,但是这里偷下懒
int cmaze[10][10];
for(i=0;i<10;i++){
for(j=0;j<10;j++){
cmaze[i][j]=maze[i][j];
}
}
//用一个新的二维数组记录走过的点
printf("\n\n");
stack *top,*p,*q,*t,*s;
top=(stack *)malloc(sizeof(stack));
top->next=NULL;
//人为设置的,(1,1)是起点,(8,8)是终点
int flag=0,x=0,y=0;
if(flag==0){
p=(stack *)malloc(sizeof(stack));
p->x=1;
p->y=1;
p->direction=-1;
q=top->next;
top->next=p;
p->next=q;
flag=1;
}
q=top->next;
x=q->x;
y=q->y;
while(q->x!=8 || q->y!=8){
//0:向左 y+1 1:向下 x+1 2:向右 y-1 3:向上 x+1
if(cmaze[x][y+1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y+1;
p->direction=0;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y+1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x+1;
p->y=y;
p->direction=1;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else if(cmaze[x][y-1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=2;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y-1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=3;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else{
t=top->next;
s=t->next;
top->next=s;
free(t);
}
q=top->next;
x=q->x;
y=q->y;
//每次都是栈顶的元素找方向,找不到就是free掉,出栈,就是后退一步
}
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",cmaze[i][j]);
}
printf("\n");
}
printf("溯源:\n");
while(top->next!=NULL){
p=top->next;
x=p->x;
y=p->y;
printf("x=%d,y=%d\n",x,y);
top=top->next;
}
return 0;
}

//队列
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define maxsize 10
#define null 0
typedef struct node{
int x;
int y;
struct node*last;
struct node*next;
} lqnode;
typedef struct{
node *front,*rear;
}Queue;
//定义一个队列的结构体,记录头和尾
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",maze[i][j]);
}
printf("\n");
}
Queue *q;
lqnode *p;
q=(Queue *)malloc(sizeof(Queue));
p=(lqnode *)malloc(sizeof(lqnode));
p->next=null;
q->rear=p;
q->front=p;
int x,y;
lqnode *r,*t;
r=(lqnode *)malloc(sizeof(lqnode));
r->x=1;
r->y=1;
r->last=null;
q->rear->next=r;
r->next=null;
q->rear=r;
t=q->front->next;
x=t->x;
y=t->y;
printf("可以走的点\n");
while(x!=8 || y!=8){
if(maze[x][y+1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y+1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y+1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
if(maze[x][y-1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y-1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y-1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
//可以走的就加入队列,然后队列是从头开始循环的,一边循环一边加入了新元素
t=t->next;
x=t->x;
y=t->y;
printf("%d,%d\n",x,y);
}
printf("溯源:\n");
while(t->last!=NULL){
printf("x=%d,y=%d\n",t->x,t->y);
t=t->last;
}
//用last记录每一个节点是由哪个节点走过来的
return 0;
}
1 1 1 1 是上面的迷宫,截图没有截好
C语言之走迷宫深度和广度优先(利用堆栈和队列)的更多相关文章
- C语言动态走迷宫
曾经用C语言做过的动态走迷宫程序,先分享代码如下: 代码如下: //头文件 #include<stdio.h> #include<windows.h>//Sleep(500)函 ...
- golang 实现广度优先算法(走迷宫)
maze.go package main import ( "fmt" "os" ) /** * 广度优先算法 */ /** * 从文件中读取数据 */ fun ...
- golang广度优先算法-走迷宫
广度优先遍历,走迷宫思路: 1.创建二维数组,0表示是路,1表示是墙:创建队列Q,存储可遍历的点,Q的第一个元素为起始点 2.从队列中取一个点,开始,按上.左.下.右的顺序遍历周围的点next,nex ...
- 数据结构之 栈与队列--- 走迷宫(深度搜索dfs)
走迷宫 Time Limit: 1000MS Memory limit: 65536K 题目描述 一个由n * m 个格子组成的迷宫,起点是(1, 1), 终点是(n, m),每次可以向上下左右四个方 ...
- LeetCode 79,这道走迷宫问题为什么不能用宽搜呢?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题第48篇文章,我们一起来看看LeetCode当中的第79题,搜索单词(Word Search). 这一题官方给的难 ...
- sdut 2449走迷宫【最简单的dfs应用】
走迷宫 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_ 题目描述 一个由n * m 个格子组成的迷宫,起点是(1, 1), 终点是(n, m) ...
- 洛谷P1238 走迷宫
洛谷1238 走迷宫 题目描述 有一个m*n格的迷宫(表示有m行.n列),其中有可走的也有不可走的,如果用1表示可以走,0表示不可以走,文件读入这m*n个数据和起始点.结束点(起始点和结束点都是用两个 ...
- BZOJ 2707: [SDOI2012]走迷宫( tarjan + 高斯消元 )
数据范围太大不能直接高斯消元, tarjan缩点然后按拓扑逆序对每个强连通分量高斯消元就可以了. E(u) = 1 + Σ E(v) / degree(u) 对拍时发现网上2个程序的INF判断和我不一 ...
- NYOJ306 走迷宫(dfs+二分搜索)
题目描写叙述 http://acm.nyist.net/JudgeOnline/problem.php?pid=306 Dr.Kong设计的机器人卡多非常爱玩.它经常偷偷跑出实验室,在某个游乐场玩之不 ...
随机推荐
- 6.11 NOI 模拟
\(T1\)魔法师 \(f(x)\)是各个数位之积,当\(f(x)\ne 0\),每一位只能是\(1\sim 9\),考虑数位积的质因数分解只能是\(2,3,5,7\)的形式,考虑对所有的\((a,b ...
- ABP 6.0.0-rc.1的新特性
2022-07-26官方发布ABP 6.0.0-rc.1版本,本文挑选了几个新特性进行了介绍,主要包括LeptonX Lite默认主题.OpenIddict模块,以及如何将Identity Ser ...
- How to code like a pro in 2022 and avoid If-Else
在浏览文章的时候发现了一篇叙述有关if-else语句的文章,这篇文章作者是Thai Tran,他原文是用英语写的,然后看着文章浅显易懂,便尝试翻译成汉语.如有不妥还望指出. 原文链接:https:// ...
- luogu1419 寻找段落 (二分,单调队列)
单调队列存坐标 #include <iostream> #include <cstdio> #include <cstring> #include <algo ...
- 论文翻译:2020_Lightweight Online Noise Reduction on Embedded Devices using Hierarchical Recurrent Neural Networks
论文地址:基于分层递归神经网络的嵌入式设备轻量化在线降噪 引用格式:Schröter H, Rosenkranz T, Zobel P, et al. Lightweight Online Noise ...
- Linux操作系统学习(运维必会)
Linux一切皆文件,最高权限的账户root. 1.开机登录 开机会启动很多进程,在Windows上叫"服务"(service),在Linux上叫做"守护进程" ...
- 修改窗体的Title
直接上代码 /// <summary> /// 获取窗体的名称 /// </summary> /// <param name="hWnd">&l ...
- 【读书笔记】C#高级编程 第十二章 动态语言扩展
(一)DLR C#4的动态功能是Dynamic Language Runtime(动态语言运行时,DLR)的一部分.DLR是添加到CLR的一系列服务. (二)dynamic类型 dynamic类型允许 ...
- ClangFormat配置备份
{ # 语言 Language: Cpp, # 水平对齐表达式的操作数 AlignOperands: true, # 不对包含头文件进行排序 SortIncludes: false, # 对齐注释 A ...
- SpringMVC--从理解SpringMVC执行流程到SSM框架整合
前言 SpringMVC框架是SSM框架中继Spring另一个重要的框架,那么什么是SpringMVC,如何用SpringMVC来整合SSM框架呢?下面让我们详细的了解一下. 注:在学习SpringM ...