深入剖析 RocketMQ 源码 - 负载均衡机制
一、引言
RocketMQ是一款优秀的分布式消息中间件,在各方面的性能都比目前已有的消息队列要好,RocketMQ默认采用长轮询的拉模式, 单机支持千万级别的消息堆积,可以非常好的应用在海量消息系统中。
RocketMQ主要由 Producer、Broker、Consumer、Namesvr 等组件组成,其中Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息,Namesvr负责存储元数据,各组件的主要功能如下:
消息生产者(Producer):负责生产消息,一般由业务系统负责生产消息。一个消息生产者会把业务应用系统里产生的消息发送到Broker服务器。RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。同步和异步方式均需要Broker返回确认信息,单向发送不需要。
消息消费者(Consumer):负责消费消息,一般是后台系统负责异步消费。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。从用户应用的角度而言提供了两种消费形式:拉取式消费、推动式消费。
代理服务器(Broker Server):消息中转角色,负责存储消息、转发消息。代理服务器在RocketMQ系统中负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备。代理服务器也存储消息相关的元数据,包括消费者组、消费进度偏移和主题和队列消息等。
名字服务(Name Server):名称服务充当路由消息的提供者。生产者或消费者能够通过名字服务查找各主题相应的Broker IP列表。多个Namesrv实例组成集群,但相互独立,没有信息交换。
生产者组(Producer Group):同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。
消费者组(Consumer Group):同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。
RocketMQ整体消息处理逻辑上以Topic维度进行生产消费、物理上会存储到具体的Broker上的某个MessageQueue当中,正因为一个Topic会存在多个Broker节点上的多个MessageQueue,所以自然而然就产生了消息生产消费的负载均衡需求。
本篇文章分析的核心在于介绍RocketMQ的消息生产者(Producer)和消息消费者(Consumer)在整个消息的生产消费过程中如何实现负载均衡以及其中的实现细节。
二、RocketMQ的整体架构
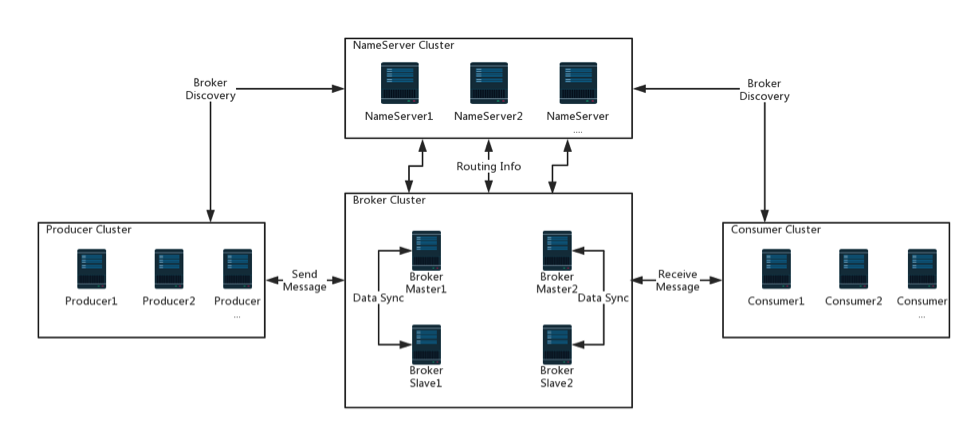
(图片来自于Apache RocketMQ)
RocketMQ架构上主要分为四部分,如上图所示:
Producer:消息发布的角色,支持分布式集群方式部署。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
Consumer:消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求。
NameServer:NameServer是一个非常简单的Topic路由注册中心,支持分布式集群方式部署,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。
BrokerServer:Broker主要负责消息的存储、投递和查询以及服务高可用保证,支持分布式集群方式部署。
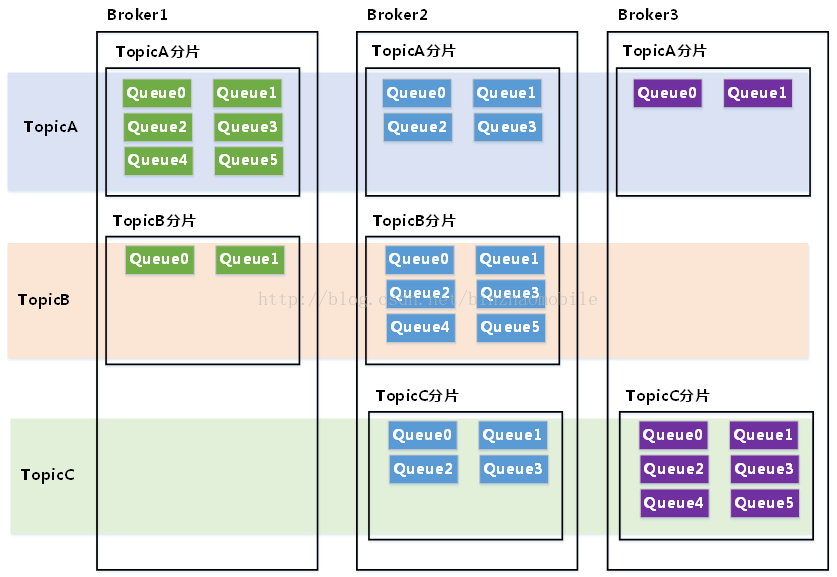
RocketMQ的Topic的物理分布如上图所示:
Topic作为消息生产和消费的逻辑概念,具体的消息存储分布在不同的Broker当中。
Broker中的Queue是Topic对应消息的物理存储单元。
在RocketMQ的整体设计理念当中,消息的生产消费以Topic维度进行,每个Topic会在RocketMQ的集群中的Broker节点创建对应的MessageQueue。
producer生产消息的过程本质上就是选择Topic在Broker的所有的MessageQueue并按照一定的规则选择其中一个进行消息发送,正常情况的策略是轮询。
consumer消费消息的过程本质上就是一个订阅同一个Topic的consumerGroup下的每个consumer按照一定的规则负责Topic下一部分MessageQueue进行消费。
在RocketMQ整个消息的生命周期内,不管是生产消息还是消费消息都会涉及到负载均衡的概念,消息的生成过程中主要涉及到Broker选择的负载均衡,消息的消费过程主要涉及多consumer和多Broker之间的负责均衡。
三、producer消息生产过程
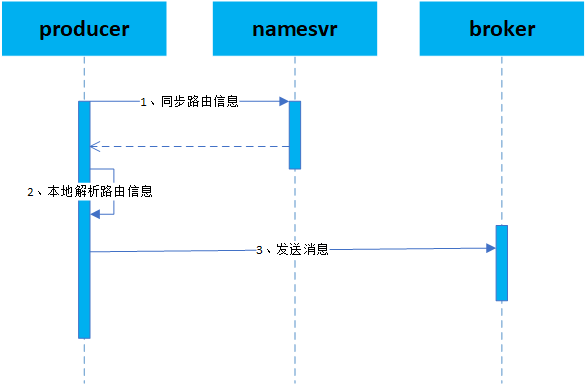
producer消息生产过程:
producer首先访问namesvr获取路由信息,namesvr存储Topic维度的所有路由信息(包括每个topic在每个Broker的队列分布情况)。
producer解析路由信息生成本地的路由信息,解析Topic在Broker队列信息并转化为本地的消息生产的路由信息。
producer根据本地路由信息向Broker发送消息,选择本地路由中具体的Broker进行消息发送。
3.1 路由同步过程
public class MQClientInstance {
public boolean updateTopicRouteInfoFromNameServer(final String topic) {
return updateTopicRouteInfoFromNameServer(topic, false, null);
}
public boolean updateTopicRouteInfoFromNameServer(final String topic, boolean isDefault,
DefaultMQProducer defaultMQProducer) {
try {
if (this.lockNamesrv.tryLock(LOCK_TIMEOUT_MILLIS, TimeUnit.MILLISECONDS)) {
try {
TopicRouteData topicRouteData;
if (isDefault && defaultMQProducer != null) {
// 省略对应的代码
} else {
// 1、负责查询指定的Topic对应的路由信息
topicRouteData = this.mQClientAPIImpl.getTopicRouteInfoFromNameServer(topic, 1000 * 3);
}
if (topicRouteData != null) {
// 2、比较路由数据topicRouteData是否发生变更
TopicRouteData old = this.topicRouteTable.get(topic);
boolean changed = topicRouteDataIsChange(old, topicRouteData);
if (!changed) {
changed = this.isNeedUpdateTopicRouteInfo(topic);
}
// 3、解析路由信息转化为生产者的路由信息和消费者的路由信息
if (changed) {
TopicRouteData cloneTopicRouteData = topicRouteData.cloneTopicRouteData();
for (BrokerData bd : topicRouteData.getBrokerDatas()) {
this.brokerAddrTable.put(bd.getBrokerName(), bd.getBrokerAddrs());
}
// 生成生产者对应的Topic信息
{
TopicPublishInfo publishInfo = topicRouteData2TopicPublishInfo(topic, topicRouteData);
publishInfo.setHaveTopicRouterInfo(true);
Iterator<Entry<String, MQProducerInner>> it = this.producerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQProducerInner> entry = it.next();
MQProducerInner impl = entry.getValue();
if (impl != null) {
impl.updateTopicPublishInfo(topic, publishInfo);
}
}
}
// 保存到本地生产者路由表当中
this.topicRouteTable.put(topic, cloneTopicRouteData);
return true;
}
}
} finally {
this.lockNamesrv.unlock();
}
} else {
}
} catch (InterruptedException e) {
}
return false;
}
}
路由同步过程:
路由同步过程是消息生产者发送消息的前置条件,没有路由的同步就无法感知具体发往那个Broker节点。
路由同步主要负责查询指定的Topic对应的路由信息,比较路由数据topicRouteData是否发生变更,最终解析路由信息转化为生产者的路由信息和消费者的路由信息。
public class TopicRouteData extends RemotingSerializable {
private String orderTopicConf;
// 按照broker维度保存的Queue信息
private List<QueueData> queueDatas;
// 按照broker维度保存的broker信息
private List<BrokerData> brokerDatas;
private HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
}
public class QueueData implements Comparable<QueueData> {
// broker的名称
private String brokerName;
// 读队列大小
private int readQueueNums;
// 写队列大小
private int writeQueueNums;
// 读写权限
private int perm;
private int topicSynFlag;
}
public class BrokerData implements Comparable<BrokerData> {
// broker所属集群信息
private String cluster;
// broker的名称
private String brokerName;
// broker对应的ip地址信息
private HashMap<Long/* brokerId */, String/* broker address */> brokerAddrs;
private final Random random = new Random();
}
--------------------------------------------------------------------------------------------------
public class TopicPublishInfo {
private boolean orderTopic = false;
private boolean haveTopicRouterInfo = false;
// 最细粒度的队列信息
private List<MessageQueue> messageQueueList = new ArrayList<MessageQueue>();
private volatile ThreadLocalIndex sendWhichQueue = new ThreadLocalIndex();
private TopicRouteData topicRouteData;
}
public class MessageQueue implements Comparable<MessageQueue>, Serializable {
private static final long serialVersionUID = 6191200464116433425L;
// Topic信息
private String topic;
// 所属的brokerName信息
private String brokerName;
// Topic下的队列信息Id
private int queueId;
}
路由解析过程:
TopicRouteData核心变量QueueData保存每个Broker的队列信息,BrokerData保存Broker的地址信息。
TopicPublishInfo核心变量MessageQueue保存最细粒度的队列信息。
producer负责将从namesvr获取的TopicRouteData转化为producer本地的TopicPublishInfo。
public class MQClientInstance {
public static TopicPublishInfo topicRouteData2TopicPublishInfo(final String topic, final TopicRouteData route) {
TopicPublishInfo info = new TopicPublishInfo();
info.setTopicRouteData(route);
if (route.getOrderTopicConf() != null && route.getOrderTopicConf().length() > 0) {
// 省略相关代码
} else {
List<QueueData> qds = route.getQueueDatas();
// 按照brokerName进行排序
Collections.sort(qds);
// 遍历所有broker生成队列维度信息
for (QueueData qd : qds) {
// 具备写能力的QueueData能够用于队列生成
if (PermName.isWriteable(qd.getPerm())) {
// 遍历获得指定brokerData进行异常条件过滤
BrokerData brokerData = null;
for (BrokerData bd : route.getBrokerDatas()) {
if (bd.getBrokerName().equals(qd.getBrokerName())) {
brokerData = bd;
break;
}
}
if (null == brokerData) {
continue;
}
if (!brokerData.getBrokerAddrs().containsKey(MixAll.MASTER_ID)) {
continue;
}
// 遍历QueueData的写队列的数量大小,生成MessageQueue保存指定TopicPublishInfo
for (int i = 0; i < qd.getWriteQueueNums(); i++) {
MessageQueue mq = new MessageQueue(topic, qd.getBrokerName(), i);
info.getMessageQueueList().add(mq);
}
}
}
info.setOrderTopic(false);
}
return info;
}
}
路由生成过程:
路由生成过程主要是根据QueueData的BrokerName和writeQueueNums来生成MessageQueue 对象。
MessageQueue是消息发送过程中选择的最细粒度的可发送消息的队列。
{
"TBW102": [{
"brokerName": "broker-a",
"perm": 7,
"readQueueNums": 8,
"topicSynFlag": 0,
"writeQueueNums": 8
}, {
"brokerName": "broker-b",
"perm": 7,
"readQueueNums": 8,
"topicSynFlag": 0,
"writeQueueNums": 8
}]
}
路由解析举例:
topic(TBW102)在broker-a和broker-b上存在队列信息,其中读写队列个数都为8。
先按照broker-a、broker-b的名字顺序针对broker信息进行排序。
针对broker-a会生成8个topic为TBW102的MessageQueue对象,queueId分别是0-7。
针对broker-b会生成8个topic为TBW102的MessageQueue对象,queueId分别是0-7。
topic(名为TBW102)的TopicPublishInfo整体包含16个MessageQueue对象,其中有8个broker-a的MessageQueue,有8个broker-b的MessageQueue。
消息发送过程中的路由选择就是从这16个MessageQueue对象当中获取一个进行消息发送。
3.2 负载均衡过程
public class DefaultMQProducerImpl implements MQProducerInner {
private SendResult sendDefaultImpl(
Message msg,
final CommunicationMode communicationMode,
final SendCallback sendCallback,
final long timeout
) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
// 1、查询消息发送的TopicPublishInfo信息
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
if (topicPublishInfo != null && topicPublishInfo.ok()) {
String[] brokersSent = new String[timesTotal];
// 根据重试次数进行消息发送
for (; times < timesTotal; times++) {
// 记录上次发送失败的brokerName
String lastBrokerName = null == mq ? null : mq.getBrokerName();
// 2、从TopicPublishInfo获取发送消息的队列
MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName);
if (mqSelected != null) {
mq = mqSelected;
brokersSent[times] = mq.getBrokerName();
try {
// 3、执行发送并判断发送结果,如果发送失败根据重试次数选择消息队列进行重新发送
sendResult = this.sendKernelImpl(msg, mq, communicationMode, sendCallback, topicPublishInfo, timeout - costTime);
switch (communicationMode) {
case SYNC:
if (sendResult.getSendStatus() != SendStatus.SEND_OK) {
if (this.defaultMQProducer.isRetryAnotherBrokerWhenNotStoreOK()) {
continue;
}
}
return sendResult;
default:
break;
}
} catch (MQBrokerException e) {
// 省略相关代码
} catch (InterruptedException e) {
// 省略相关代码
}
} else {
break;
}
}
if (sendResult != null) {
return sendResult;
}
}
}
}
消息发送过程:
查询Topic对应的路由信息对象TopicPublishInfo。
从TopicPublishInfo中通过selectOneMessageQueue获取发送消息的队列,该队列代表具体落到具体的Broker的queue队列当中。
执行发送并判断发送结果,如果发送失败根据重试次数选择消息队列进行重新发送,重新选择队列会避开上一次发送失败的Broker的队列。
public class TopicPublishInfo {
public MessageQueue selectOneMessageQueue(final String lastBrokerName) {
if (lastBrokerName == null) {
return selectOneMessageQueue();
} else {
// 按照轮询进行选择发送的MessageQueue
for (int i = 0; i < this.messageQueueList.size(); i++) {
int index = this.sendWhichQueue.getAndIncrement();
int pos = Math.abs(index) % this.messageQueueList.size();
if (pos < 0)
pos = 0;
MessageQueue mq = this.messageQueueList.get(pos);
// 避开上一次上一次发送失败的MessageQueue
if (!mq.getBrokerName().equals(lastBrokerName)) {
return mq;
}
}
return selectOneMessageQueue();
}
}
}
路由选择过程:
MessageQueue的选择按照轮询进行选择,通过全局维护索引进行累加取模选择发送队列。
MessageQueue的选择过程中会避开上一次发送失败Broker对应的MessageQueue。
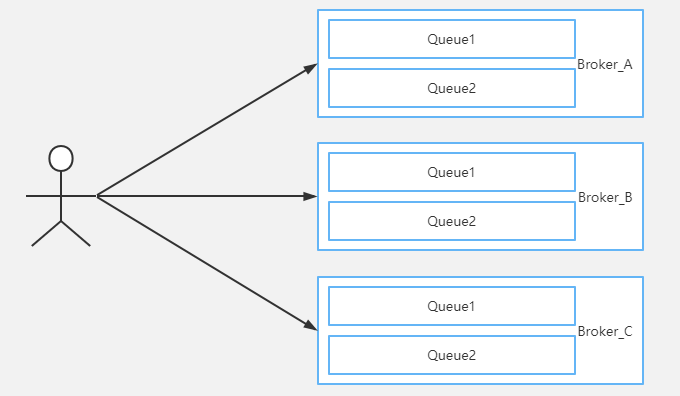
Producer消息发送示意图:
某Topic的队列分布为Broker_A_Queue1、Broker_A_Queue2、Broker_B_Queue1、Broker_B_Queue2、Broker_C_Queue1、Broker_C_Queue2,根据轮询策略依次进行选择。
发送失败的场景下如Broker_A_Queue1发送失败那么就会跳过Broker_A选择Broker_B_Queue1进行发送。
四、consumer消息消费过程
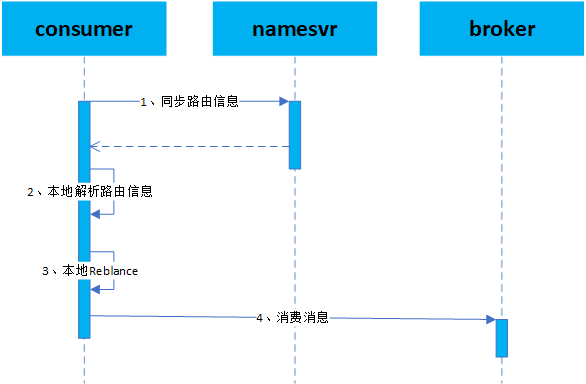
consumer消息消费过程:
consumer访问namesvr同步topic对应的路由信息。
consumer在本地解析远程路由信息并保存到本地。
consumer在本地进行Reblance负载均衡确定本节点负责消费的MessageQueue。
consumer访问Broker消费指定的MessageQueue的消息。
4.1 路由同步过程
public class MQClientInstance {
// 1、启动定时任务从namesvr定时同步路由信息
private void startScheduledTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
MQClientInstance.this.updateTopicRouteInfoFromNameServer();
} catch (Exception e) {
log.error("ScheduledTask updateTopicRouteInfoFromNameServer exception", e);
}
}
}, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);
}
public void updateTopicRouteInfoFromNameServer() {
Set<String> topicList = new HashSet<String>();
// 遍历所有的consumer订阅的Topic并从namesvr获取路由信息
{
Iterator<Entry<String, MQConsumerInner>> it = this.consumerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQConsumerInner> entry = it.next();
MQConsumerInner impl = entry.getValue();
if (impl != null) {
Set<SubscriptionData> subList = impl.subscriptions();
if (subList != null) {
for (SubscriptionData subData : subList) {
topicList.add(subData.getTopic());
}
}
}
}
}
for (String topic : topicList) {
this.updateTopicRouteInfoFromNameServer(topic);
}
}
public boolean updateTopicRouteInfoFromNameServer(final String topic, boolean isDefault,
DefaultMQProducer defaultMQProducer) {
try {
if (this.lockNamesrv.tryLock(LOCK_TIMEOUT_MILLIS, TimeUnit.MILLISECONDS)) {
try {
TopicRouteData topicRouteData;
if (isDefault && defaultMQProducer != null) {
// 省略代码
} else {
topicRouteData = this.mQClientAPIImpl.getTopicRouteInfoFromNameServer(topic, 1000 * 3);
}
if (topicRouteData != null) {
TopicRouteData old = this.topicRouteTable.get(topic);
boolean changed = topicRouteDataIsChange(old, topicRouteData);
if (!changed) {
changed = this.isNeedUpdateTopicRouteInfo(topic);
}
if (changed) {
TopicRouteData cloneTopicRouteData = topicRouteData.cloneTopicRouteData();
for (BrokerData bd : topicRouteData.getBrokerDatas()) {
this.brokerAddrTable.put(bd.getBrokerName(), bd.getBrokerAddrs());
}
// 构建consumer侧的路由信息
{
Set<MessageQueue> subscribeInfo = topicRouteData2TopicSubscribeInfo(topic, topicRouteData);
Iterator<Entry<String, MQConsumerInner>> it = this.consumerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQConsumerInner> entry = it.next();
MQConsumerInner impl = entry.getValue();
if (impl != null) {
impl.updateTopicSubscribeInfo(topic, subscribeInfo);
}
}
}
this.topicRouteTable.put(topic, cloneTopicRouteData);
return true;
}
}
} finally {
this.lockNamesrv.unlock();
}
}
} catch (InterruptedException e) {
}
return false;
}
}
路由同步过程:
路由同步过程是消息消费者消费消息的前置条件,没有路由的同步就无法感知具体待消费的消息的Broker节点。
consumer节点通过定时任务定期从namesvr同步该消费节点订阅的topic的路由信息。
consumer通过updateTopicSubscribeInfo将同步的路由信息构建成本地的路由信息并用以后续的负责均衡。
4.2 负载均衡过程
public class RebalanceService extends ServiceThread {
private static long waitInterval =
Long.parseLong(System.getProperty(
"rocketmq.client.rebalance.waitInterval", "20000"));
private final MQClientInstance mqClientFactory;
public RebalanceService(MQClientInstance mqClientFactory) {
this.mqClientFactory = mqClientFactory;
}
@Override
public void run() {
while (!this.isStopped()) {
this.waitForRunning(waitInterval);
this.mqClientFactory.doRebalance();
}
}
}
负载均衡过程:
consumer通过RebalanceService来定期进行重新负载均衡。
RebalanceService的核心在于完成MessageQueue和consumer的分配关系。
public abstract class RebalanceImpl {
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
case BROADCASTING: {
// 省略相关代码
break;
}
case CLUSTERING: { // 集群模式下的负载均衡
// 1、获取topic下所有的MessageQueue
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
// 2、获取topic下该consumerGroup下所有的consumer对象
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
// 3、开始重新分配进行rebalance
if (mqSet != null && cidAll != null) {
List<MessageQueue> mqAll = new ArrayList<MessageQueue>();
mqAll.addAll(mqSet);
Collections.sort(mqAll);
Collections.sort(cidAll);
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
// 4、通过分配策略重新进行分配
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
return;
}
Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();
if (allocateResult != null) {
allocateResultSet.addAll(allocateResult);
}
// 5、根据分配结果执行真正的rebalance动作
boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
if (changed) {
this.messageQueueChanged(topic, mqSet, allocateResultSet);
}
}
break;
}
default:
break;
}
}
重新分配流程:
获取topic下所有的MessageQueue。
获取topic下该consumerGroup下所有的consumer的cid(如192.168.0.8@15958)。
针对mqAll和cidAll进行排序,mqAll排序顺序按照先BrokerName后BrokerId,cidAll排序按照字符串排序。
通过分配策略
AllocateMessageQueueStrategy重新分配。
根据分配结果执行真正的rebalance动作。
public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy {
private final InternalLogger log = ClientLogger.getLog();
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<MessageQueue>();
// 核心逻辑计算开始
// 计算当前cid的下标
int index = cidAll.indexOf(currentCID);
// 计算多余的模值
int mod = mqAll.size() % cidAll.size();
// 计算平均大小
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
// 计算起始下标
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
// 计算范围大小
int range = Math.min(averageSize, mqAll.size() - startIndex);
// 组装结果
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
// 核心逻辑计算结束
@Override
public String getName() {
return "AVG";
}
}
------------------------------------------------------------------------------------
rocketMq的集群存在3个broker,分别是broker_a、broker_b、broker_c。
rocketMq上存在名为topic_demo的topic,writeQueue写队列数量为3,分布在3个broker。
排序后的mqAll的大小为9,依次为
[broker_a_0 broker_a_1 broker_a_2 broker_b_0 broker_b_1 broker_b_2 broker_c_0 broker_c_1 broker_c_2]
rocketMq存在包含4个consumer的consumer_group,排序后cidAll依次为
[192.168.0.6@15956 192.168.0.7@15957 192.168.0.8@15958 192.168.0.9@15959]
192.168.0.6@15956 的分配MessageQueue结算过程
index:0
mod:9%4=1
averageSize:9 / 4 + 1 = 3
startIndex:0
range:3
messageQueue:[broker_a_0、broker_a_1、broker_a_2]
192.168.0.6@15957 的分配MessageQueue结算过程
index:1
mod:9%4=1
averageSize:9 / 4 = 2
startIndex:3
range:2
messageQueue:[broker_b_0、broker_b_1]
192.168.0.6@15958 的分配MessageQueue结算过程
index:2
mod:9%4=1
averageSize:9 / 4 = 2
startIndex:5
range:2
messageQueue:[broker_b_2、broker_c_0]
192.168.0.6@15959 的分配MessageQueue结算过程
index:3
mod:9%4=1
averageSize:9 / 4 = 2
startIndex:7
range:2
messageQueue:[broker_c_1、broker_c_2]
分配策略分析:
- 整体分配策略可以参考上图的具体例子,可以更好的理解分配的逻辑。
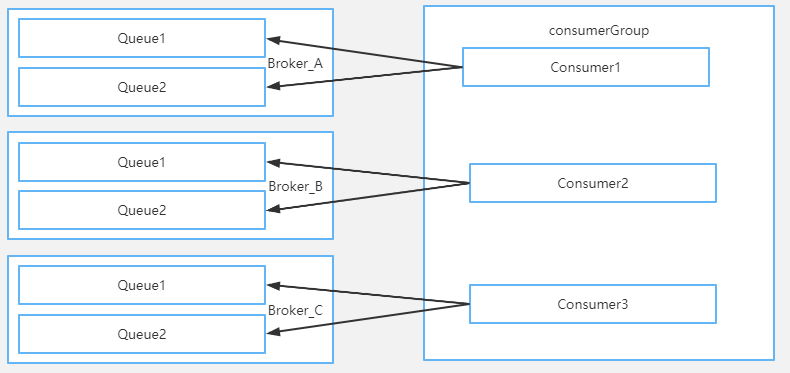
consumer的分配:
同一个consumerGroup下的consumer对象会分配到同一个Topic下不同的MessageQueue。
每个MessageQueue最终会分配到具体的consumer当中。
五、RocketMQ指定机器消费设计思路
日常测试环境当中会存在多台consumer进行消费,但实际开发当中某台consumer新上了功能后希望消息只由该机器进行消费进行逻辑覆盖,这个时候consumerGroup的集群模式就会给我们造成困扰,因为消费负载均衡的原因不确定消息具体由那台consumer进行消费。当然我们可以通过介入consumer的负载均衡机制来实现指定机器消费。
public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy {
private final InternalLogger log = ClientLogger.getLog();
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<MessageQueue>();
// 通过改写这部分逻辑,增加判断是否是指定IP的机器,如果不是直接返回空列表表示该机器不负责消费
if (!cidAll.contains(currentCID)) {
return result;
}
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
}
consumer负载均衡策略改写:
通过改写负载均衡策略AllocateMessageQueueAveragely的allocate机制保证只有指定IP的机器能够进行消费。
通过IP进行判断是基于RocketMQ的cid格式是192.168.0.6@15956,其中前面的IP地址就是对于的消费机器的ip地址,整个方案可行且可以实际落地。
六、小结
本文主要介绍了RocketMQ在生产和消费过程中的负载均衡机制,结合源码和实际案例力求给读者一个易于理解的技术普及,希望能对读者有参考和借鉴价值。囿于文章篇幅,有些方面未涉及,也有很多技术细节未详细阐述,如有疑问欢迎继续交流。
作者:vivo互联网服务器团队-Wang Zhi
深入剖析 RocketMQ 源码 - 负载均衡机制的更多相关文章
- 深入剖析RocketMQ源码-NameServer
一.RocketMQ架构简介 1.1 逻辑部署图 (图片来自网络) 1.2 核心组件说明 通过上图可以看到,RocketMQ的核心组件主要包括4个,分别是NameServer.Broker.Produ ...
- 深入剖析 RocketMQ 源码 - 消息存储模块
一.简介 RocketMQ 是阿里巴巴开源的分布式消息中间件,它借鉴了 Kafka 实现,支持消息订阅与发布.顺序消息.事务消息.定时消息.消息回溯.死信队列等功能.RocketMQ 架构上主要分为四 ...
- RocketMQ源码 — 六、 RocketMQ高可用(1)
高可用究竟指的是什么?请参考:关于高可用的系统 RocketMQ做了以下的事情来保证系统的高可用 多master部署,防止单点故障 消息冗余(主从结构),防止消息丢失 故障恢复(本篇暂不讨论) 那么问 ...
- RocketMQ源码分析之从官方示例窥探:RocketMQ事务消息实现基本思想
摘要: RocketMQ源码分析之从官方示例窥探RocketMQ事务消息实现基本思想. 在阅读本文前,若您对RocketMQ技术感兴趣,请加入RocketMQ技术交流群 RocketMQ4.3.0版本 ...
- RocketMQ源码详解 | Consumer篇 · 其一:消息的 Pull 和 Push
概述 当消息被存储后,消费者就会将其消费. 这句话简要的概述了一条消息的最总去向,也引出了本文将讨论的问题: 消息什么时候才对被消费者可见? 是在 page cache 中吗?还是在落盘后?还是像 K ...
- Azure的负载均衡机制
负载均衡一直是一个比较重要的议题,几乎所有的Azure案例或者场景都不可避免,鉴于经常有客户会问,所以笔者觉得有必要总结一下. Azure提供的负载均衡机制,按照功能,可以分为三种:Azure Loa ...
- HDFS 02 - HDFS 的机制:副本机制、机架感知机制、负载均衡机制
目录 1 - HDFS 的副本机制 2 - HDFS 的机架感知机制 3 - HDFS 的负载均衡机制 参考资料 版权声明 1 - HDFS 的副本机制 HDFS 中的文件,在物理上都是以分块(blo ...
- 【RocketMQ源码分析】深入消息存储(1)
最近在学习RocketMQ相关的东西,在学习之余沉淀几篇笔记. RocketMQ有很多值得关注的设计点,消息发送.消息消费.路由中心NameServer.消息过滤.消息存储.主从同步.事务消息等等. ...
- RocketMQ源码详解 | Broker篇 · 其一:线程模型与接收链路
概述 在上一节 RocketMQ源码详解 | Producer篇 · 其二:消息组成.发送链路 中,我们终于将消息发送出了 Producer,在短暂的 tcp 握手后,很快它就会进入目的 Broker ...
随机推荐
- ASP.NET Core 6框架揭秘实例演示[23]:ASP.NET Core应用承载方式的变迁
ASP.NET Core应用本质上就是一个由中间件构成的管道,承载系统将应用承载于一个托管进程中运行起来,其核心任务就是将这个管道构建起来.从设计模式的角度来讲,"管道"是构建者( ...
- ArcMap操作随记(10)
1.基于点生成辐射线 [缓冲区]→[构造视线] 2.求算点集中于剩余点距离总和最小的点 [构造视线]→[计算几何]→[汇总] 3.关于空间参考,关于投影 ①横轴墨卡托投影 "等角横轴切圆柱投 ...
- 一些JDK自带的性能分析利器
有时候碰到服务器CPU飙升或者程序卡死之类的问题,一般都不太好定位.这类bug一般都隐藏的比较深并且还可能是偶发性的,比较棘手. 对于此类问题,一般我们都有固定的分析流程.借助于JDK自带的一些分析工 ...
- html 两个并列div样式
1.html 代码 <html> <head> <link rel="stylesheet" href="cs2.css"> ...
- 谈谈 Kubernetes Operator
简介 你可能听过Kubernetes中Operator的概念,Operator可以帮助我们扩展Kubernetes功能,包括管理任何有状态应用程序.我们看到了它被用于有状态基础设施应用程序的许多可能性 ...
- ArcGIS Server 禁用/rest/services路径(禁用服务目录)
ArcGIS Server服务目录(路径如:http://<hostname>:6080/arcgis/rest/services)默认可以不需要登陆直接打开.效果如下图. ArcGIS服 ...
- 常用命令行指令 Windows & Linux
一.Linux linux常用命令详解:https://www.cnblogs.com/yuncong/p/10247583.html 挂载U盘到linux一个文件夹中 二.Windows 1.查看电 ...
- 6月5日 python学习总结 jQuery (二)
1. 操作样式 对CSS类的操作: addClass();// 添加指定的CSS类名. removeClass();// 移除指定的CSS类名. hasClass();// 判断样式存不存在 ...
- 放在initramfs的ko会先加载,还是/lib/modules/下面的ko会先加载?
如果是在switchroot时加载,用的是initramfs,在switchroot后,用的是硬盘上的,有些ko放到initramfs中,但是switchroot前不加载的话,用的还是硬盘上的,关键看 ...
- Spring Data Jpa 更新操作
第一步,通过Repository对象把实体根据ID查询出来 第二部,往查出来的实体对象进行set各个字段 第三步,通过Repository接口的save方法进行保存 保存和更新方式(已知两种) 第一种 ...