Spark详解(07) - SparkStreaming
Spark详解(07) - SparkStreaming
SparkStreaming概述
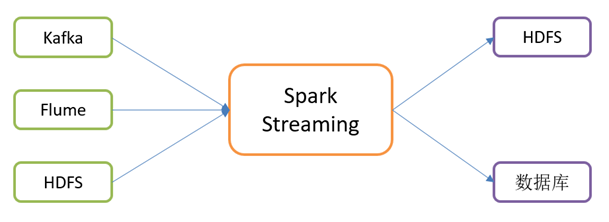
Spark Streaming用于流式数据的处理。
Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、HDFS等。
数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。
而结果也能保存在很多地方,如HDFS、数据库等。
Spark Streaming架构原理
什么是Dstream
SparkCore => RDD
SparkSQL => DataFrame、DataSet
Spark Streaming使用离散化流(Discretized Stream)作为抽象表示,叫作Dstream
DStream是随时间推移而收到的数据的序列。
在DStream内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列(因此得名"离散化")。
所以简单来讲,DStream就是对RDD在实时数据处理场景的一种封装。

架构图
整体`架构图
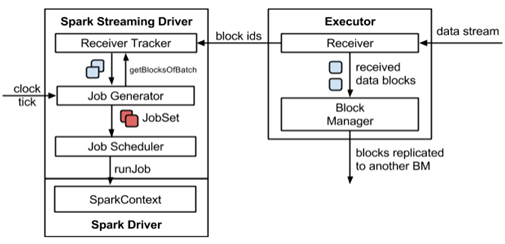
SparkStreaming架构图
背压机制
Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数"spark.streaming.receiver.maxRate"的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure):根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
通过属性"spark.streaming.backpressure.enabled"来控制是否启用背压机制,默认值false,即不启用。
Spark Streaming特点
易用

容错
易整合到Spark体系

DStream入门
WordCount案例实操
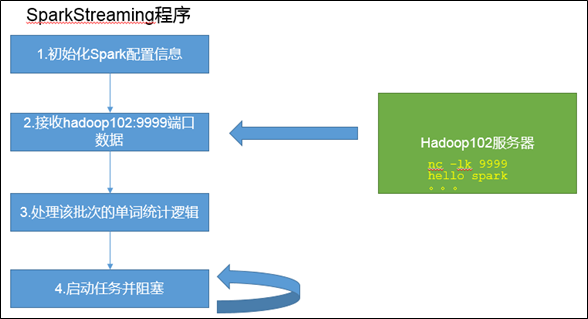
需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
1)添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
2)编写代码
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming01_WordCount {
- def main(args: Array[String]): Unit = {
- //1.初始化Spark配置信息
- val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- //2.初始化SparkStreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3.通过监控端口创建DStream,读进来的数据为一行行
- val lineDStream = ssc.socketTextStream("hadoop102", 9999)
- //3.1 将每一行数据做切分,形成一个个单词
- val wordDStream = lineDStream.flatMap(_.split(" "))
- //3.2 将单词映射成元组(word,1)
- val wordToOneDStream = wordDStream.map((_, 1))
- //3.3 将相同的单词次数做统计
- val wordToSumDStream = wordToOneDStream.reduceByKey(_+_)
- //3.4 打印
- wordToSumDStream.print()
- //4 启动SparkStreamingContext
- ssc.start()
- // 将主线程阻塞,主线程不退出
- ssc.awaitTermination()
- }
- }
3)更改日志打印级别
将log4j.properties文件添加到resources里面,就能更改打印日志的级别为error
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
4)启动程序并通过netcat发送数据:
[hadoop@hadoop102 ~]$ nc -lk 9999
hello spark
5)在Idea控制台输出如下内容:
-------------------------------------------
Time: 1602731772000 ms
-------------------------------------------
(hello,1)
(spark,1)
注意:目前用的算子,只能处理本批次数据的累加,不能统计所有批次总的单词个数。
WordCount解析
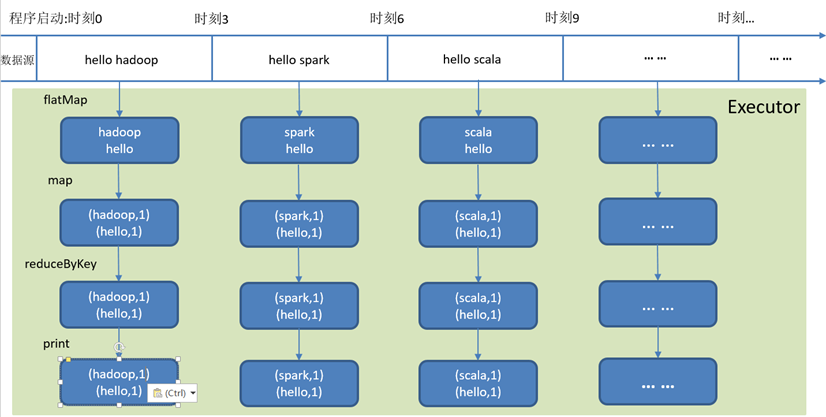
DStream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
在内部实现上,每一批次的数据封装成一个RDD,一系列连续的RDD组成了DStream。对这些RDD的转换是由Spark引擎来计算。
说明:DStream中批次与批次之间计算相互独立。如果批次设置时间小于计算时间会出现计算任务叠加情况,需要多分配资源。通常情况,批次设置时间要大于计算时间。
DStream创建
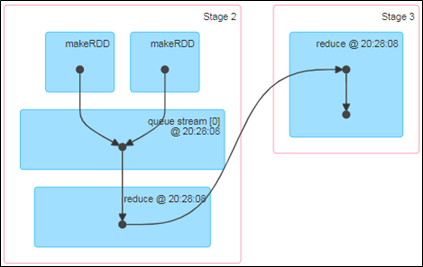
RDD队列
使用ssc.queueStream(queueOfRDDs)来创建DStream
将每一个推送到这个队列中的RDD,都会作为一个DStream处理。
需求:循环创建几个RDD,将RDD放入队列。通过SparkStreaming创建DStream,计算WordCount

-------------------------------------------
-------------------------------------------
-------------------------------------------
-------------------------------------------
-------------------------------------------
-------------------------------------------
说明:如果一个批次中有多个RDD进入队列,最终计算前都会合并到一个RDD计算
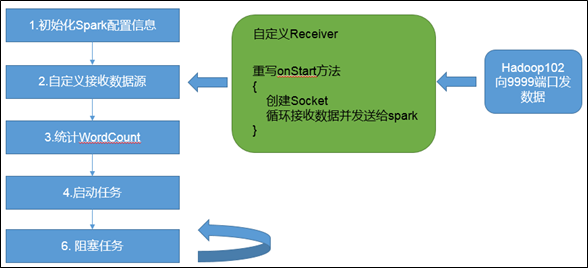
自定义数据源
需要继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
3.2.2 案例实操
[hadoop@hadoop102 ~]$ nc -lk 9999
Kafka数据源(面试、开发重点)
DirectAPI:是由计算的Executor来主动消费Kafka的数据,速度由自身控制。
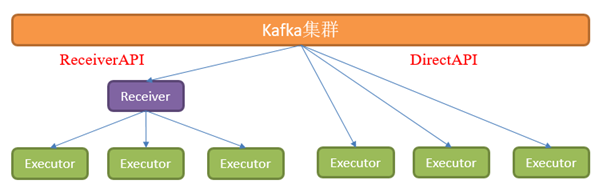
注意:目前spark3.0.0以上版本只有Direct模式。
http://spark.apache.org/docs/2.4.7/streaming-kafka-integration.html
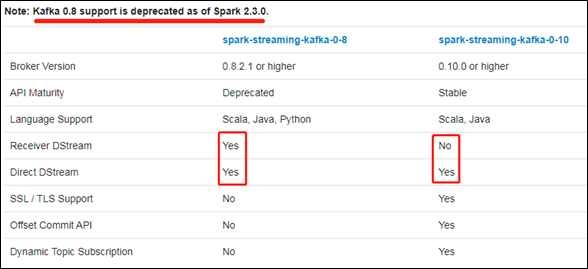
http://spark.apache.org/docs/3.0.0/streaming-kafka-0-10-integration.html
总结:不同版本的offset存储位置
0-8 ReceiverAPI offset默认存储在:Zookeeper中
0-8 DirectAPI offset默认存储在:CheckPoint
手动维护:MySQL等有事务的存储系统
0-10 DirectAPI offset默认存储在:_consumer_offsets系统主题
手动维护:MySQL等有事务的存储系统
- Kafka 0-10 Direct模式
1)需求:通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算,最终打印到控制台。

2)导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
3)编写代码
- import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
- import org.apache.kafka.common.serialization.StringDeserializer
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.{DStream, InputDStream}
- import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming04_DirectAuto {
- def main(args: Array[String]): Unit = {
- //1.创建SparkConf
- val sparkConf: SparkConf = new SparkConf().setAppName("sparkstreaming").setMaster("local[*]")
- //2.创建StreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3.定义Kafka参数:kafka集群地址、消费者组名称、key序列化、value序列化
- val kafkaPara: Map[String, Object] = Map[String, Object](
- ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
- ConsumerConfig.GROUP_ID_CONFIG -> "group_1",
- ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
- ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
- )
- //4.读取Kafka数据创建DStream
- val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
- ssc,
- LocationStrategies.PreferConsistent, //优先位置
- ConsumerStrategies.Subscribe[String, String](Set("testTopic"), kafkaPara)// 消费策略:(订阅多个主题,配置参数)
- )
- //5.将每条消息的KV取出
- val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
- //6.计算WordCount
- valueDStream.flatMap(_.split(" "))
- .map((_, 1))
- .reduceByKey(_ + _)
- .print()
- //7.开启任务
- ssc.start()
- ssc.awaitTermination()
- }
- }
4)测试
(1)分别启动Zookeeper和Kafka集群
zk.sh start
kf.sh start
(2)创建一个Kafka的Topic主题testTopic,两个分区
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 1 --partitions 2 --topic testTopic
(3)查看Topic列表
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka -list
(4)查看Topic详情
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --describe --topic testTopic
(5)创建Kafka生产者
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic testTopic
Hello spark
Hello spark
(6)创建Kafka消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic testTopic
5)查看_consumer_offsets主题中存储的offset
bin/kafka-consumer-groups.sh --bootstrap-server hadoop102:9092 --describe --group group_1
GROUP TOPIC PARTITION CURRENT-OFFSET
LOG-END-OFFSET
Group_1 testTopic 0 13 13
在生产者中生产数据,再次观察offset变化
DStream转换
DStream上的操作与RDD的类似,分为转换和输出两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
无状态转化操作
无状态转化操作:就是把RDD转化操作应用到DStream每个批次上,每个批次相互独立,自己算自己的。
常规无状态转化操作
DStream的部分无状态转化操作列在了下表中,都是DStream自己的API。
注意,针对键值对的DStream转化操作,要添加import StreamingContext._才能在Scala中使用,比如reduceByKey()。
|
函数名称 |
目的 |
Scala示例 |
函数签名 |
|
map() |
对DStream中的每个元素应用给定函数,返回由各元素输出的元素组成的DStream。 |
ds.map(x=>x + 1) |
f: (T) -> U |
|
flatMap() |
对DStream中的每个元素应用给定函数,返回由各元素输出的迭代器组成的DStream。 |
ds.flatMap(x => x.split(" ")) |
f: T -> Iterable[U] |
|
filter() |
返回由给定DStream中通过筛选的元素组成的DStream |
ds.filter(x => x != 1) |
f: T -> Boolean |
|
repartition() |
改变DStream的分区数 |
ds.repartition(10) |
N / A |
|
reduceByKey() |
将每个批次中键相同的记录规约。 |
ds.reduceByKey( (x, y) => x + y) |
f: T, T -> T |
|
groupByKey() |
将每个批次中的记录根据键分组。 |
ds.groupByKey() |
N / A |
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD批次组成,且无状态转化操作是分别应用到每个RDD批次上的。
Transform
需求:通过Transform可以将DStream每一批次的数据直接转换为RDD的算子操作。

- 代码编写
- import org.apache.spark.SparkConf
- import org.apache.spark.rdd.RDD
- import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming05_Transform {
- def main(args: Array[String]): Unit = {
- //1 创建SparkConf
- val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- //2 创建StreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3 创建DStream
- val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
- // 在Driver端执行,全局一次
- println("111111111:" + Thread.currentThread().getName)
- //4 转换为RDD操作
- val wordToSumDStream: DStream[(String, Int)] = lineDStream.transform(
- rdd => {
- // 在Driver端执行(ctrl+n JobGenerator),一个批次一次
- println("222222:" + Thread.currentThread().getName)
- val words: RDD[String] = rdd.flatMap(_.split(" "))
- val wordToOne: RDD[(String, Int)] = words.map(x=>{
- // 在Executor端执行,和单词个数相同
- println("333333:" + Thread.currentThread().getName)
- (x, 1)
- })
- val value: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
- value
- }
- )
- //5 打印
- wordToSumDStream.print
- //6 启动
- ssc.start()
- ssc.awaitTermination()
- }
- }
有状态转化操作
有状态转化操作:计算当前批次RDD时,需要用到历史RDD的数据。
UpdateStateByKey
updateStateByKey()用于键值对形式的DStream,可以记录历史批次状态。例如可以实现累加WordCount。
updateStateByKey()参数中需要传递一个函数,在函数内部可以根据需求对新数据和历史状态进行整合处理,返回一个新的DStream。
注意:使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
checkpoint小文件过多
checkpoint记录最后一次时间戳,再次启动的时候会把间隔时间的周期再执行一次
0)需求:更新版的WordCount
1)编写代码
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.ReceiverInputDStream
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object sparkStreaming06_updateStateByKey {
- // 定义更新状态方法,参数seq为当前批次单词次数,state为以往批次单词次数
- val updateFunc = (seq: Seq[Int], state: Option[Int]) => {
- // 当前批次数据累加
- val currentCount = seq.sum
- // 历史批次数据累加结果
- val previousCount = state.getOrElse(0)
- // 总的数据累加
- Some(currentCount + previousCount)
- }
- def createSCC(): StreamingContext = {
- //1 创建SparkConf
- val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- //2 创建StreamingContext
- val ssc = new StreamingContext(conf, Seconds(3))
- ssc.checkpoint("./ck")
- //3 获取一行数据
- val lines = ssc.socketTextStream("hadoop102", 9999)
- //4 切割
- val words = lines.flatMap(_.split(" "))
- //5 统计单词
- val wordToOne = words.map(word => (word, 1))
- //6 使用updateStateByKey来更新状态,统计从运行开始以来单词总的次数
- val stateDstream = wordToOne.updateStateByKey[Int](updateFunc)
- stateDstream.print()
- ssc
- }
- def main(args: Array[String]): Unit = {
- val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck",()=>createSCC())
- //7 开启任务
- ssc.start()
- ssc.awaitTermination()
- }
- }
2)启动程序并向9999端口发送数据
nc -lk 9999
hello hadoop
hello hadoop
3)结果展示
-------------------------------------------
Time: 1603441344000 ms
-------------------------------------------
(hello,1)
(hadoop,1)
-------------------------------------------
Time: 1603441347000 ms
-------------------------------------------
(hello,2)
(hadoop,2)
4)原理说明
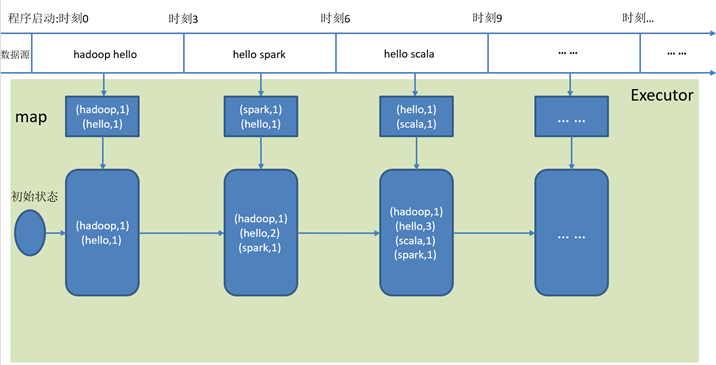
WindowOperations(窗口函数)
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
窗口时长:计算内容的时间范围;
滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集批次大小的整数倍。
如下图所示WordCount案例:窗口大小为批次的2倍,滑动步等于批次大小。
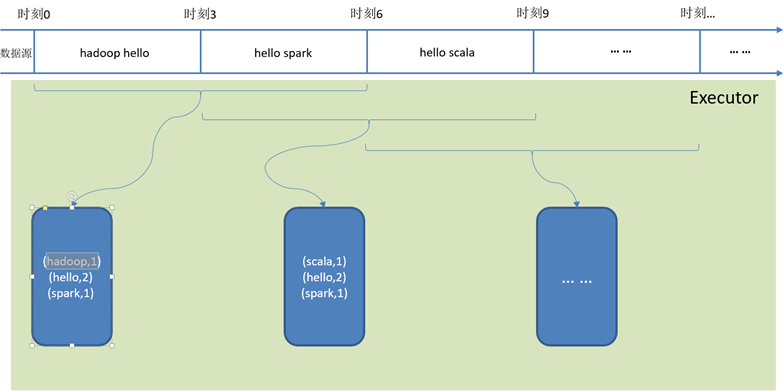
Window
1)基本语法:window(windowLength, slideInterval): 基于对源DStream窗口的批次进行计算返回一个新的DStream。
2)需求:统计WordCount:3秒一个批次,窗口12秒,滑步6秒。
3)代码编写:
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.DStream
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming07_window {
- def main(args: Array[String]): Unit = {
- // 1 初始化SparkStreamingContext
- val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- val ssc = new StreamingContext(conf, Seconds(3))
- // 2 通过监控端口创建DStream,读进来的数据为一行行
- val lines = ssc.socketTextStream("hadoop102", 9999)
- // 3 切割=》变换
- val wordToOneDStream = lines.flatMap(_.split(" "))
- .map((_, 1))
- // 4 获取窗口返回数据
- val wordToOneByWindow: DStream[(String, Int)] = wordToOneDStream.window(Seconds(12), Seconds(6))
- // 5 聚合窗口数据并打印
- val wordToCountDStream: DStream[(String, Int)] = wordToOneByWindow.reduceByKey(_+_)
- wordToCountDStream.print()
- // 6 启动=》阻塞
- ssc.start()
- ssc.awaitTermination()
- }
- }
5)如果有多批数据进入窗口,最终也会通过window操作变成统一的RDD处理。
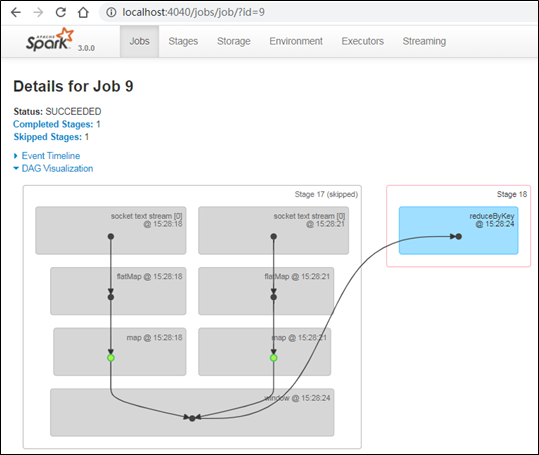
reduceByKeyAndWindow
1)基本语法:
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
2)需求:统计WordCount:3秒一个批次,窗口12秒,滑步6秒。
3)代码编写:
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming08_reduceByKeyAndWindow {
- def main(args: Array[String]): Unit = {
- // 1 初始化SparkStreamingContext
- val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- val ssc = new StreamingContext(conf, Seconds(3))
- // 保存数据到检查点
- ssc.checkpoint("./ck")
- // 2 通过监控端口创建DStream,读进来的数据为一行行
- val lines = ssc.socketTextStream("hadoop102", 9999)
- // 3 切割=》变换
- val wordToOne = lines.flatMap(_.split(" "))
- .map((_, 1))
- // 4 窗口参数说明: 算法逻辑,窗口12秒,滑步6秒
- val wordCounts = wordToOne.reduceByKeyAndWindow((a: Int, b: Int) => (a + b), Seconds(12), Seconds(6))
- // 5 打印
- wordCounts.print()
- // 6 启动=》阻塞
- ssc.start()
- ssc.awaitTermination()
- }
- }
reduceByKeyAndWindow(反向Reduce)
1)基本语法:
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并"反向reduce"离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的"加""减"计数。通过前边介绍可以想到,这个函数只适用于"可逆的reduce函数",也就是这些reduce函数有相应的"反reduce"函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。
2)需求:统计WordCount:3秒一个批次,窗口12秒,滑步6秒。
3)代码编写:
- import org.apache.spark.{HashPartitioner, SparkConf}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming09_reduceByKeyAndWindow_reduce {
- def main(args: Array[String]): Unit = {
- // 1 初始化SparkStreamingContext
- val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- val ssc = new StreamingContext(conf, Seconds(3))
- // 保存数据到检查点
- ssc.checkpoint("./ck")
- // 2 通过监控端口创建DStream,读进来的数据为一行行
- val lines = ssc.socketTextStream("hadoop102", 9999)
- // 3 切割=》变换
- val wordToOne = lines.flatMap(_.split(" "))
- .map((_, 1))
- // 4 窗口参数说明: 算法逻辑,窗口12秒,滑步6秒
- /*
- val wordToSumDStream: DStream[(String, Int)]= wordToOne.reduceByKeyAndWindow(
- (a: Int, b: Int) => (a + b),
- (x: Int, y: Int) => (x - y),
- Seconds(12),
- Seconds(6)
- )*/
- // 处理单词统计次数为0的问题
- val wordToSumDStream: DStream[(String, Int)]= wordToOne.reduceByKeyAndWindow(
- (a: Int, b: Int) => (a + b),
- (x: Int, y: Int) => (x - y),
- Seconds(12),
- Seconds(6),
- new HashPartitioner(2),
- (x:(String, Int)) => x._2 > 0
- )
- // 5 打印
- wordToSumDStream.print()
- // 6 启动=》阻塞
- ssc.start()
- ssc.awaitTermination()
- }
- }
Window的其他操作
(1)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(2)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
DStream输出
DStream通常将数据输出到,外部数据库或屏幕上。
DStream与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个Context就都不会启动。
1)输出操作API如下:
- saveAsTextFiles(prefix, [suffix]):以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。"prefix-Time_IN_MS[.suffix]"。
- saveAsObjectFiles(prefix, [suffix]):以Java对象序列化的方式将DStream中的数据保存为 SequenceFiles 。每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。
- saveAsHadoopFiles(prefix, [suffix]):将Stream中的数据保存为 Hadoop files。每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。
注意:以上操作都是每一批次写出一次,会产生大量小文件,在生产环境,很少使用。
- print():在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。
- foreachRDD(func):这是最通用的输出操作,即将函数func用于产生DStream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者写入数据库。
在企业开发中通常采用foreachRDD(),它用来对DStream中的RDD进行任意计算。这和transform()有些类似,都可以让我们访问任意RDD。在foreachRDD()中,可以重用在Spark中实现的所有行动操作。比如,常见的用例之一是把数据写到如MySQL的外部数据库中。
- foreachRDD代码实操
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object SparkStreaming10_output {
- def main(args: Array[String]): Unit = {
- // 1 初始化SparkStreamingContext
- val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
- val ssc = new StreamingContext(conf, Seconds(3))
- // 2 通过监控端口创建DStream,读进来的数据为一行行
- val lineDStream = ssc.socketTextStream("hadoop102", 9999)
- // 3 切割=》变换
- val wordToOneDStream = lineDStream.flatMap(_.split(" "))
- .map((_, 1))
- // 4 输出
- wordToOneDStream.foreachRDD(
- rdd=>{
- // 在Driver端执行(ctrl+n JobScheduler),一个批次一次
- // 在JobScheduler 中查找(ctrl + f)streaming-job-executor
- println("222222:" + Thread.currentThread().getName)
- rdd.foreachPartition(
- //5.1 测试代码
- iter=>iter.foreach(println)
- //5.2 企业代码
- //5.2.1 获取连接
- //5.2.2 操作数据,使用连接写库
- //5.2.3 关闭连接
- )
- }
- )
- // 5 启动=》阻塞
- ssc.start()
- ssc.awaitTermination()
- }
- }
3)注意
(1)连接不能写在Driver层面(序列化)
(2)如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
(3)增加foreachPartition,在分区创建(获取)。
优雅关闭
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所以配置优雅的关闭就显得至关重要了。
关闭方式:使用外部文件系统来控制内部程序关闭。
- 主程序
- import java.net.URI
- import org.apache.hadoop.conf.Configuration
- import org.apache.hadoop.fs.{FileSystem, Path}
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.ReceiverInputDStream
- import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
- object SparkStreaming11_stop {
- def main(args: Array[String]): Unit = {
- //1.初始化Spark配置信息
- val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStreaming")
- //2.初始化SparkStreamingContext
- val ssc: StreamingContext = new StreamingContext(sparkconf, Seconds(3))
- // 设置优雅的关闭
- sparkconf.set("spark.streaming.stopGracefullyOnShutdown", "true")
- // 接收数据
- val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
- // 执行业务逻辑
- lineDStream.flatMap(_.split(" ")).map((_,1)).print()
- // 开启监控程序
- new Thread(new MonitorStop(ssc)).start()
- //4 启动SparkStreamingContext
- ssc.start()
- // 将主线程阻塞,主线程不退出
- ssc.awaitTermination()
- }
- }
- // 监控程序
- class MonitorStop(ssc: StreamingContext) extends Runnable{
- override def run(): Unit = {
- // 获取HDFS文件系统
- val fs: FileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration(),"hadoop")
- while (true){
- Thread.sleep(5000)
- // 获取/stopSpark路径是否存在
- val result: Boolean = fs.exists(new Path("hdfs://hadoop102:8020/stopSpark"))
- if (result){
- val state: StreamingContextState = ssc.getState()
- // 获取当前任务是否正在运行
- if (state == StreamingContextState.ACTIVE){
- // 优雅关闭
- ssc.stop(stopSparkContext = true, stopGracefully = true)
- System.exit(0)
- }
- }
- }
- }
- }
2)测试
(1)发送数据
nc -lk 9999
hello
(2)启动Hadoop集群
sbin/start-dfs.sh
hadoop fs -mkdir /stopSpark
Spark详解(07) - SparkStreaming的更多相关文章
- Spark详解
原文连接 http://xiguada.org/spark/ Spark概述 当前,MapReduce编程模型已经成为主流的分布式编程模型,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的 ...
- 【Linux】一步一步学Linux——VMware虚拟机三种网络模式详解(07)
目录 00. 目录 01. 虚拟网络连接组件 02. 常见网络连接配置 03. 桥接模式 04. NAT 模式 05. 仅主机模式 06. 自定义模式 07. 附录 00. 目录 @ 01. 虚拟网络 ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- 小甲鱼PE详解之输入表(导入表)详解(PE详解07)
捷径并不是把弯路改直了,而是帮你把岔道堵上! 走得弯路跟成长的速度是成正比的!不要害怕走上弯路,弯路会让你懂得更多,最终还是会在终点交汇! 岔路会将你引入万劫不复的深渊,并越走越深…… 在开始讲解输入 ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
- HttpURLConnection详解
HttpURLConnection详解 07. 五 / J2EE / 没有评论 HttpURLConnection类的作用是通过HTTP协议向服务器发送请求,并可以获取服务器发回的数据. Http ...
- Spark小课堂Week6 启动日志详解
Spark小课堂Week6 启动日志详解 作为分布式系统,Spark程序是非常难以使用传统方法来进行调试的,所以我们主要的武器是日志,今天会对启动日志进行一下详解. 日志详解 今天主要遍历下Strea ...
- Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕
Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕 今天会逐行解析一下SparkStreaming运行的日志,运行的是WordCountO ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
随机推荐
- 前端枚举enum的应用(Element)封装
什么是枚举Enum 枚举 Enum是在众多语言中都有的一种数据类型,JavaScript中还没有(TypeScript有).用来表示一些特定类别的常量数据,如性别.学历.方向.账户状态等,项目开发中是 ...
- 手写编程语言-如何为 GScript 编写标准库
版本更新 最近 GScript 更新了 v0.0.11 版本,重点更新了: Docker 运行环境 新增了 byte 原始类型 新增了一些字符串标准库 Strings/StringBuilder 数组 ...
- Magnet: Push-based Shuffle Service for Large-scale Data Processing
本文是阅读 LinkedIn 公司2020年发表的论文 Magnet: Push-based Shuffle Service for Large-scale Data Processing 一点笔记. ...
- golang中的字符串
0.1.索引 https://waterflow.link/articles/1666449874974 1.字符串编码 在go中rune是一个unicode编码点. 我们都知道UTF-8将字符编码为 ...
- python批量加密文件
1.文件名的加密与解密 #coding:utf-8 from docx import Document import os,sys from docx.oxml.ns import qn def fi ...
- 9.异步redis
在使用Python代码操作redis时候,连接.操作.断开都是网络IO #安装支持异步redis的模块 pip3 install aioredis async def execute(address, ...
- 9_Vue事件修饰符
概述 首先需要理解下什么是事件修饰符 常用事件修饰符 案例1_阻止默认行为发生 我这里有一个a标签 这个标签呢我会给它配置一个点击事件 点击事件输出一句话,那么效果是这样的 代码 <body&g ...
- 17_Vue列表过滤_js模糊查询
列表过滤 需求分析 这里呢有张列表,假设这个列表有一百多条数据 当我在这个 搜索框当中 搜索 单个关键字的时候 (冬,周,伦),它能把带了这几个关键字的信息都给我罗列出来 === 跟数据库的 模糊查询 ...
- C# 语法分析器(二)LR(0) 语法分析
系列导航 (一)语法分析介绍 (二)LR(0) 语法分析 (三)LALR 语法分析 (四)二义性文法 (五)错误恢复 (六)构造语法分析器 首先,需要介绍下 LALR 语法分析的基础:LR(0) 语法 ...
- Java单例模式,看这一篇就够了
在创建型设计模式中,我们第一个学习的是单例模式(Singleton Pattern),这是设计模式中最简单的模式之一. 单例是什么意思呢? 单例就是单实例的意思,即在系统全局,一个类只创建一个对象,并 ...