微服务框架——MybatisPlus
MybatisPlus
一、快速入门
1.mybatisPlus特性
- 无侵入:只增强,不改变。
- 损耗小:启动的时候直接注入基本CRUD
- 强大的CRUD操作:提供通用Mapper,通用service,条件构造器等
- Lambda:支持lambda形式的调用
- 主键自动生成
- 支持ActiveRecord模式:实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作
- 内置代码生成器
- 内置分页插件,且支持多种数据库
- 内置性能分析插件:输出sql语句执行时间
- 内置全局拦截插件
2.快速开始
屏蔽数据库建表插入数据细节,Employee表,Employee实体类。忽略架构层级细节
导入依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
Mapper类
@Repository
@Mapper
public interface EmployeeMapper extends BaseMapper<Employee> {
}
测试类
@SpringBootTest
class BoottestApplicationTests extends AbstractJUnit4SpringContextTests { @Autowired
EmployeeMapper employeeMapper; @Test
void contextLoad2() {
//UserMapper 中的 selectList() 方法的参数为 MP 内置的条件封装器 Wrapper,所以不填写就是无任何条件
List<Employee> list = employeeMapper.selectList(null);
for (Employee employee : list) {
System.out.println(employee);
}
}
}
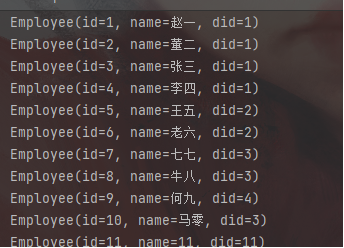
输出成功:
3.相关注解
@TableName
标识实体类对应的表
@TableName("employee")
public class Employee {
private int id;
private String name;
private int did;
}
@TableId
标识主键
public class Employee {
@TableId
private int id;
private String name;
private int did;
}
type值可以设置当前主键的生成策略

@TableField
标识数据库的其他字段
public class Employee {
@TableId
private int id;
@TableField("name")
private String name;
private int did;
}
@Version
乐观锁注解,标识在对应字段属性上
@EnumValue
普通枚举类注解
@TableLogic
表字段逻辑处理注解(逻辑删除等)
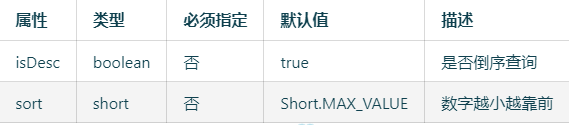
@OrderBy
内置sql默认指定排序
二、基本功能
1.逻辑删除
逻辑删除是为了方便数据恢复和保护数据本身价值等等的一种方案,但实际对用户来说就是删除。只是管理员可以选择去管理删除掉的数据。
使用(在实体类的对应字段上添加@TableLogic注解)
@TableLogic
private Integer deleted;
配置
mybatis-plus:
global-config:
db-config:
logic-delete-field: flag # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
实际场景
实际场景中,官方推荐直接在数据库中设置逻辑删除字段的默认值。
如果不想设置默认值,可以在insert的时候插入到实体类对象中或者使用mp的自动填充功能
2.自动填充
自定义填充功能意在某些场景下减少程序员的工作量,比如注册时间、更新时间这些,或者说上文的逻辑删除需要在插入时赋值等。可以让mp直接托管字段的赋值,非常银杏。
使用:
public class User {
// 注意!这里需要标记为填充字段
@TableField(fill = FieldFill.INSERT)
private String fillField;
....
}
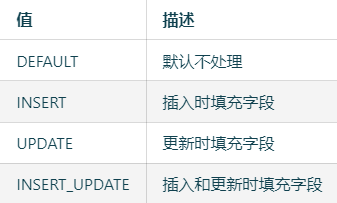
填充字段的值一共有4种。对应的值对应某个插入场景。
配置:填充功能的配置需要实现MetaObjectHandler接口。
@Component
public class MyMetaObjectHandler implements MetaObjectHandler { @Override
public void insertFill(MetaObject metaObject) {
//参数(参数类,填充字段名,填充类型,填充值)
this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐使用)
// 或者
this.strictInsertFill(metaObject, "createTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
} @Override
public void updateFill(MetaObject metaObject) {
this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐)
// 或者
this.strictUpdateFill(metaObject, "updateTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
}
}
3.主键策略
public enum IdType {
//数据库ID自增,数据库需要支持主键自增(如MySQL),并设置主键自增
AUTO(0),
//该类型为未设置主键类型,默认使用雪花算法生成
NONE(1),
//用户输入ID,数据类型和数据库保持一致就行
//该类型可以通过自己注册自动填充插件进行填充
INPUT(2),
//以下3种类型、只有当插入对象ID 为空,才自动填充。 */
//全局唯一ID (idWorker),数值类型 数据库中也必须是数值类型 否则会报错
ID_WORKER(3),
//全局唯一ID (UUID,不含中划线)
UUID(4),
//字符串全局唯一ID (idWorker 的字符串表示),数据库也要保证一样字符类型
ID_WORKER_STR(5);
}
如果在@TableId中使用type指定了主键策略的话,那么就得配置主键策略相关的bean使其生效。
我们也可以直接选择在yml中配置全局策略使其生效。
mybatis-plus:
global-config:
db-config:
id-type: auto
甚至可以自定义自己的主键策略,只需要实现IdentifierGenerator接口即可
@Component
public class CustomIdGenerator implements IdentifierGenerator {
@Override
public Long nextId(Object entity) {
//id生成逻辑
...
//返回生成的id
return id;
}
}
注入自定义的主键策略
@Bean
public IdentifierGenerator idGenerator() {
return new CustomIdGenerator();
}
4.默认CRUD注入
MP为我们自动注入了很多基本的crud操作,这在极大程度上省去了很多的工作量
Service
编写自己的service类继承mp的service基类IService<>,泛型为表映射的实体类名
@Service
public interface IEmployeeService extends IService<Employee> { }
常用api
@Test
void mpService(){
Employee employee = new Employee();
List<Employee> employeeList = Collections.singletonList(employee);
//插入一条记录
iEmployeeService.save(employee);
//批量插入
iEmployeeService.saveBatch(employeeList);
//存在更新,不存在则插入
iEmployeeService.saveOrUpdate(employee);
iEmployeeService.saveOrUpdate(employee,new UpdateWrapper<>());
iEmployeeService.saveOrUpdateBatch(employeeList);
//条件删除
iEmployeeService.remove(new QueryWrapper<>());
iEmployeeService.removeById(1);
//批量删除
iEmployeeService.removeByIds(employeeList.stream().map(Employee::getId).collect(Collectors.toList()));
//根据id查询
Employee employee1 = iEmployeeService.getById(1);
//条件查询
Map<String, Object> employeeMap = iEmployeeService.getMap(new QueryWrapper<>());
Employee employee2 = iEmployeeService.getOne(new QueryWrapper<>());
//查询全表
List<Employee> employeeList1 = iEmployeeService.list();
List<Employee> employeeList2 = iEmployeeService.listByIds(employeeList.stream().map(Employee::getId).collect(Collectors.toList()));
//分页查询
Page<Employee> employeePage1 = iEmployeeService.page(new Page<>());
Page<Employee> employeePage2 = iEmployeeService.page(new Page<>(),new QueryWrapper<>());
//查询数量
int count = iEmployeeService.count(new QueryWrapper<>());
//链式查询
iEmployeeService.query().eq("name","马云").ge()....
//链式条件删除
iEmployeeService.update().eq("name","马云").remove();
//链式条件更新
iEmployeeService.update().eq("name","马云").update();
}
Mapper
编写自己的Mapper类继承mp的mapper基类BaseMapper<>,泛型为表映射的实体类名
@Repository
@Mapper
public interface EmployeeMapper extends BaseMapper<Employee> {
}
常用api
@Test
void mpMapper(){
Employee employee = new Employee();
List<Employee> employeeList = Collections.singletonList(employee);
//插入一条记录
employeeMapper.insert(employee);
//条件删除
employeeMapper.delete(new QueryWrapper<>());
//批量删除
employeeMapper.deleteBatchIds(employeeList.stream().map(Employee::getId).collect(Collectors.toList()));
employeeMapper.deleteById(1);
employeeMapper.updateById(employee);
//批量查找
List<Employee> employeeList1 = employeeMapper.selectList(new QueryWrapper<>());
List<Employee> employeeList2 = employeeMapper.selectBatchIds(employeeList.stream().map(Employee::getId).collect(Collectors.toList()));
//查询数量
Integer count = employeeMapper.selectCount(new QueryWrapper<>());
//分页查询
Page<Employee> employeePage = employeeMapper.selectPage(new Page<>(), new QueryWrapper<>());
}
Class
实体类继承mp的Model基类之后,可以直接使用实体类的对象进行基本的crud操作,非常银杏
public class Employee extends Model<Employee> implements Serializable {
...
}
@Test
void mpModel(){
Employee employee = new Employee();
employee.insert();
employee.deleteById();
employee.updateById();
employee.selectById();
}
三、条件构造器
在前文的很多地方都能看到条件构造器的身影,他们是mp用于生成 sql 的 where 条件的一个工具类。比较常用的就是queryWrapper和updateWrapper
1.QueryWrapper
等值比较
eq(R column, Object val); // 等于 =,比如 eq("name", "老六") ---> name = '老六'
ne(R column, Object val); // 不等于 <>
gt(R column, Object val); // 大于 >
ge(R column, Object val); // 大于等于 >=
lt(R column, Object val); // 小于 <
le(R column, Object val); // 小于等于 <=
范围比较
between(R column, Object val1, Object val2); // between a and b, 例: between("age", 18, 30) ---> age between 18 and 30
notBetween(R column, Object val1, Object val2); // not between a and b
in(R column, Object... values); // IN (v0, v1, ...)
notIn(R column, Object... values); // NOT IN (v0, v1, ...)
inSql(R column, String value); // IN sql语句
notInSql(R column, String value); // NOT IN sql语句
模糊匹配
like(R column, Object val); // LIKE '%值%',比如like("name", "王") ---> name like '%王%'
notLike(R column, Object val); // NOT LIKE '%值%'
likeLeft(R column, Object val); // LIKE '%值'
likeRight(R column, Object val); // LIKE '值%'
空值比较
isNull(R column); // IS NULL,例: isNull("name") ---> name is null
isNotNull(R column); // IS NOT NULL
分组排序
groupBy(R... columns); // 等价于 GROUP BY colums ..., 例: groupBy("id", "name") ---> group by id,name
orderByAsc(R... columns); // ORDER BY colums... ASC 升序
orderByDesc(R... columns); // ORDER BY colums ... DESC 降序
having(String sqlHaving, String value); // HAVING ( sql语句 )
实际中sql语句不建议直接在wrapper语句中写。如果有wrapper实现不了的语句,直接使用原始的mybatis写即可。
四、扩展功能
1.代码生成器
新版本的代码生成器需要额外导入一个mybatis-plus-generator的依赖,并且只有3.5.1及以上版本适用新的生成器
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
生成器需要一个可运行的程序,可以直接自定义一个工具程序,在main函数里运行生成程序。
新版本的改进是优化了旧版本的set注入,而是采用链式编程的方式。以FastAutoGenerator为启动器进行配置
//数据库驱动配置
FastAutoGenerator.create("url",username,password)
//基本配置,参数为一个函数式接口,之后的配置相同
.globalConfig(new Consumer<GlobalConfig.Builder>() {
@Override
public void accept(GlobalConfig.Builder builder) {
builder.outputDir(System.getProperty("user.dir") + "/src/main/java")//包输出路径
.author("姬如千泷")//作者名
.dateType(DateType.ONLY_DATE)//时间类型
.fileOverride()//文件覆盖
.enableSwagger()//开启swagger
.enableKotlin()//开启kotlin模式,泛用性更广的编程语言
.commentDate(String)//日期格式化串
.build();//构建
}
})
//包配置
.packageConfig(builder -> {
builder.parent("com...")//父包名,默认为com.baomidou
.
.entity("entity")//实体类包名
.mapper("mapper")//mapper包名
.controller("controller")//controller包名
.service("service");//service包名
.serviceImpl("service.impl")//实现类包名
.xml("mapper.xml")//xml包名
.other("other")//自定义文件包名
.pathInfo("")//输出路径
.build();//构建
})
//模板配置
.templateConfig(builder -> {
builder.disable()//禁用所有模板
.disable(TemplateType.ENTITY...)//禁用部分模板
.entity("/templates/entity.java")//设置实体类模板路径,下同
.service("/templates/service.java")
.serviceImpl("/templates/serviceImpl.java")
.mapper("/templates/mapper.java")
.mapperXml("/templates/mapper.xml")
.controller("/templates/controller.java")
})
//策略配置
.strategyConfig(builder -> {
builder.addInclude("employee","department","company")//添加要生成代码结构的表
.enableCapitalMode()//开启大写命名
.enableSkipView()//开启跳过视图
.disableSqlFilter()//禁用sql过滤
.likeTable(new LikeTable("USER"))//模糊表匹配
.addTablePrefix("t_", "c_")//表过滤前缀
.addFieldSuffix("_flag")//字段过滤后缀
.build();
}).execute();//执行整个配置
不仅如此,在strategyConfig配置中好可以引申更多的详细配置,比如乐观锁、主键策略等等
.strategyConfig(builder -> {
builder
//实体类配置
.entityBuilder()
.superClass(BaseEntity.class)//设置父类
.disableSerialVersionUID()//禁用SerialVersionUID生成
.enableChainModel()//开启链式模式
.enableLombok()//启用lombok
.enableRemoveIsPrefix()//bool字段移除is
.enableTableFieldAnnotation()//开启字段注解
.enableActiveRecord()//开启ActiveRecord模型
.versionColumnName("version")//乐观锁字段名
.logicDeleteColumnName("deleted")//逻辑删除字段名
.naming(NamingStrategy.no_change)//表名映射策略——下划线转驼峰
.columnNaming(NamingStrategy.underline_to_camel)//字段名映射策略——下划线转驼峰
.addSuperEntityColumns("id", "created_by", "created_time", "updated_by", "updated_time")//父类公共字段
.addIgnoreColumns("age")//忽略字段
.addTableFills(new Column("create_time", FieldFill.INSERT))//表字段填充
.addTableFills(new Property("updateTime", FieldFill.INSERT_UPDATE))
.idType(IdType.AUTO)//主键策略
.formatFileName("%sEntity")//.java文件名
//controller配置
.build().controllerBuilder()
.superClass(BaseController.class)//父类
.enableHyphenStyle()//驼峰转连字符,如user_hello
.enableRestStyle()//生成restcontroller注解
.formatFileName("%sAction")//文件名
//service配置
.build().serviceBuilder()
.superServiceClass(BaseService.class)//接口父类
.superServiceImplClass(BaseServiceImpl.class)//实现类父类
.formatServiceFileName("%sService")//接口文件名
.formatServiceImplFileName("%sServiceImp")//接口实现类文件名
//mapper配置
.build().mapperBuilder()
.superClass(BaseMapper.class)//父类mapper
.enableMapperAnnotation()//开启@Mappper注解
.enableBaseResultMap()//启用BaseResultMap
.enableBaseColumnList()//启用BaseColumnList
.cache(MyMapperCache.class)//缓存实现类
.formatMapperFileName("%sDao")//mapper文件名
.formatXmlFileName("%sXml")//xml文件名
})
2.SQL性能分析插件
mp提供了一种用来帮助程序员检测优化sql语句的插件,可以打印出sql的详情以及执行时长。使用前需要导入依赖包
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>最新版本</version>
</dependency>
在yml中进行配置注入
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:h2:mem:test
...
官方提供的关于spy插件的配置
#3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
#3.2.1以下使用或者不配置
#modulelist=com.p6spy.engine.logging.P6LogFactory,com.p6spy.engine.outage.P6OutageFactory
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
# 使用日志系统记录 sql
#appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 实际驱动可多个
#driverlist=org.h2.Driver
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2

3.MybatisX插件
MybatisX 是一款基于 IDEA 的快速开发插件,为效率而生,可视化了大部分的mp功能。直接在插件库下载即可
官方文档:MybatisX快速开发插件 | MyBatis-Plus (baomidou.com)
微服务框架——MybatisPlus的更多相关文章
- 搭建SpringCloud微服务框架:一、结构和各个组件
搭建微服务框架(结构和各个组件) 简介 SQuid是基于Spring,SpringBoot,使用了SpringCloud下的组件进行构建,目的是想搭建一套可以快速开发部署,并且很好上手的一套微服务框架 ...
- 从 1.5 开始搭建一个微服务框架——日志追踪 traceId
你好,我是悟空. 前言 最近在搭一个基础版的项目框架,基于 SpringCloud 微服务框架. 如果把 SpringCloud 这个框架当做 1,那么现在已经有的基础组件比如 swagger/log ...
- 基于thrift的微服务框架
前一阵开源过一个基于spring-boot的rest微服务框架,今天再来一篇基于thrift的微服务加框,thrift是啥就不多了,大家自行百度或参考我之前介绍thrift的文章, thrift不仅支 ...
- 基于spring-boot的rest微服务框架
周末在家研究spring-boot,参考github上的一些开源项目,整了一个rest微服务框架,取之于民,用之于民,在github上开源了,地址如下: https://github.com/yjmy ...
- [goa]golang微服务框架学习--安装使用
当项目逐渐变大之后,服务增多,开发人员增加,单纯的使用go来写服务会遇到风格不统一,开发效率上的问题. 之前研究go的微服务架构go-kit最让人头疼的就是定义服务之后,还要写很多重复的框架代码, ...
- 【GoLang】go 微服务框架 && Web框架学习资料
参考资料: 通过beego快速创建一个Restful风格API项目及API文档自动化: http://www.cnblogs.com/huligong1234/p/4707282.html Go 语 ...
- 【GoLang】golang 微服务框架 go-kit
golang-Microservice Go kit - A toolkit for microservices kubernetes go-kit_百度搜索 Peter Bourgon谈使用Go和& ...
- Java微服务框架
Java的微服务框架dobbo.spring boot.redkale.spring cloud 消息中间件RabbitMQ.Kafka.RocketMQ
- 基于.NET CORE微服务框架 -surging的介绍和简单示例 (开源)
一.前言 至今为止编程开发已经11个年头,从 VB6.0,ASP时代到ASP.NET再到MVC, 从中见证了.NET技术发展,从无畏无知的懵懂少年,到现在的中年大叔,从中的酸甜苦辣也只有本人自知.随着 ...
随机推荐
- JavaScript基础&实战(3)js中的流程控制语句、条件分支语句、for循环、while循环
文章目录 1.流程控制语句 1.1 代码 1.2 测试结果 2.弹窗提示输入内容 2.1 代码 2.2 测试结果 3.条件分支语句 3.1 代码 3.2 测试结果 4.while和 do...whil ...
- 禁忌搜索算法TSA 旅行商问题TSP python
import math import random import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot ...
- windows和虚拟机上的Ubuntu互传文件
1.简介 本文讲述的是通过ssh登录虚拟机上的Ubuntu系统,实现互传文件 2.Ubuntu端 2.1.安装ssh sudo apt-get update sudo apt-get install ...
- django 生产环境部署手册
Django 是 python 的 web 框架,以下是其部署到生产环境的详细步骤,包含 Apache 和 nginx 版本. 部署环境 操作系统:centeros7.3 数据库:MySQL5.6.5 ...
- 解决ffmpeg的播放摄像头的延时优化问题(项目案例使用有效)
在目前的项目中使用了flv的播放摄像头的方案,但是延时达到了7-8秒,所以客户颇有微词,没有办法,只能开始优化播放延时的问题,至于对接摄像头的方案有好几种,这种咱们以后在聊,今天只要聊聊聊优化参数的问 ...
- 六、dockerfile
一.什么是镜像 镜像可以看成是由多个镜像层叠加起来的一个文件系统(通过UnionFS与AUFS文件联合系统实现),镜像层也可以简单理解为一个基本的镜像,而每个镜像层之间通过指针的形式进行叠加. 根据上 ...
- 嵌入式-C语言基础:字符串结束标识符
#include<stdio.h> int main() { char cdata[]={'h','e','l','l','o'}; char cdata2[]="hello&q ...
- 2022春每日一题:Day 32
题目:[USACO12DEC]First! G 不太记得当时怎么想的了,但是显然,当一个字符串的前缀存在则他一定不是first,然后做法:对于每个字符串,把每个字符结尾跟他有相同前缀的单词的同元素建边 ...
- 广州2022CCPC补题
I Infection 知识点: 树上背包 第一次写树上背包的题目,没想到就是在区域赛中 神奇的是树上背包的复杂度,看起来是\(O(n^3)\),但是实际计算只有\(O(n^2)\) 学会树上背包后可 ...
- 【Spring系列】- Bean生命周期底层原理
Bean生命周期底层原理 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! 前言 上次学到动 ...