下载nltk数据包报错
安装nltk需要两步:安装nltk和安装nltk_data数据包
安装nltk
安装nltk很简单,可以直接在pycharm环境中安装,flie —> settings—> Python Interpreter —> 点击+ —> 搜索nltk —> intall Package
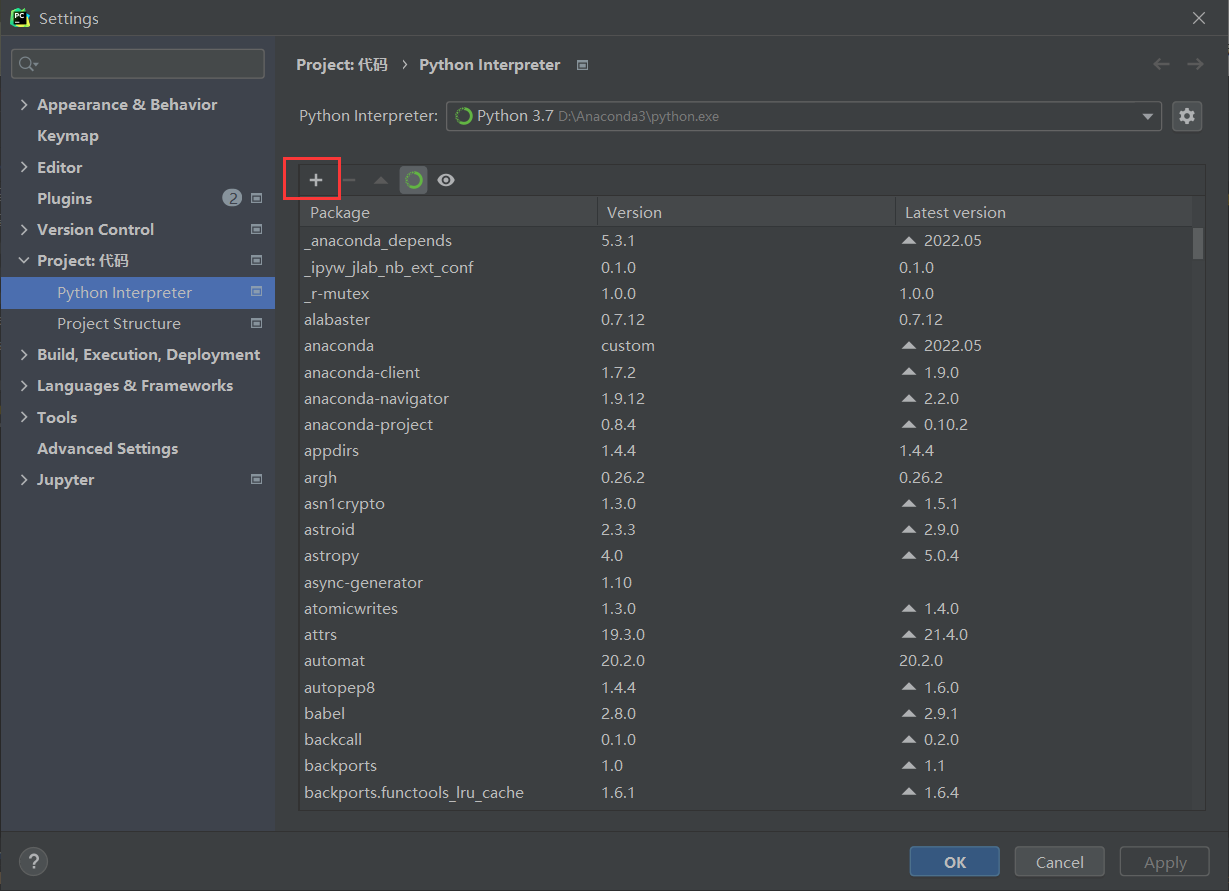
接下来需要安装nltk_data数据包才能使用nltk
手动安装nltk
最简单的办法:在pychram里使用下面两行代码安装:
1 import nltk
2 nltk.download()
但通常这样安装都会提示:getaddrinfo failed
这是因为这里自动弹出的server index里提供的网址找不到对应的IP
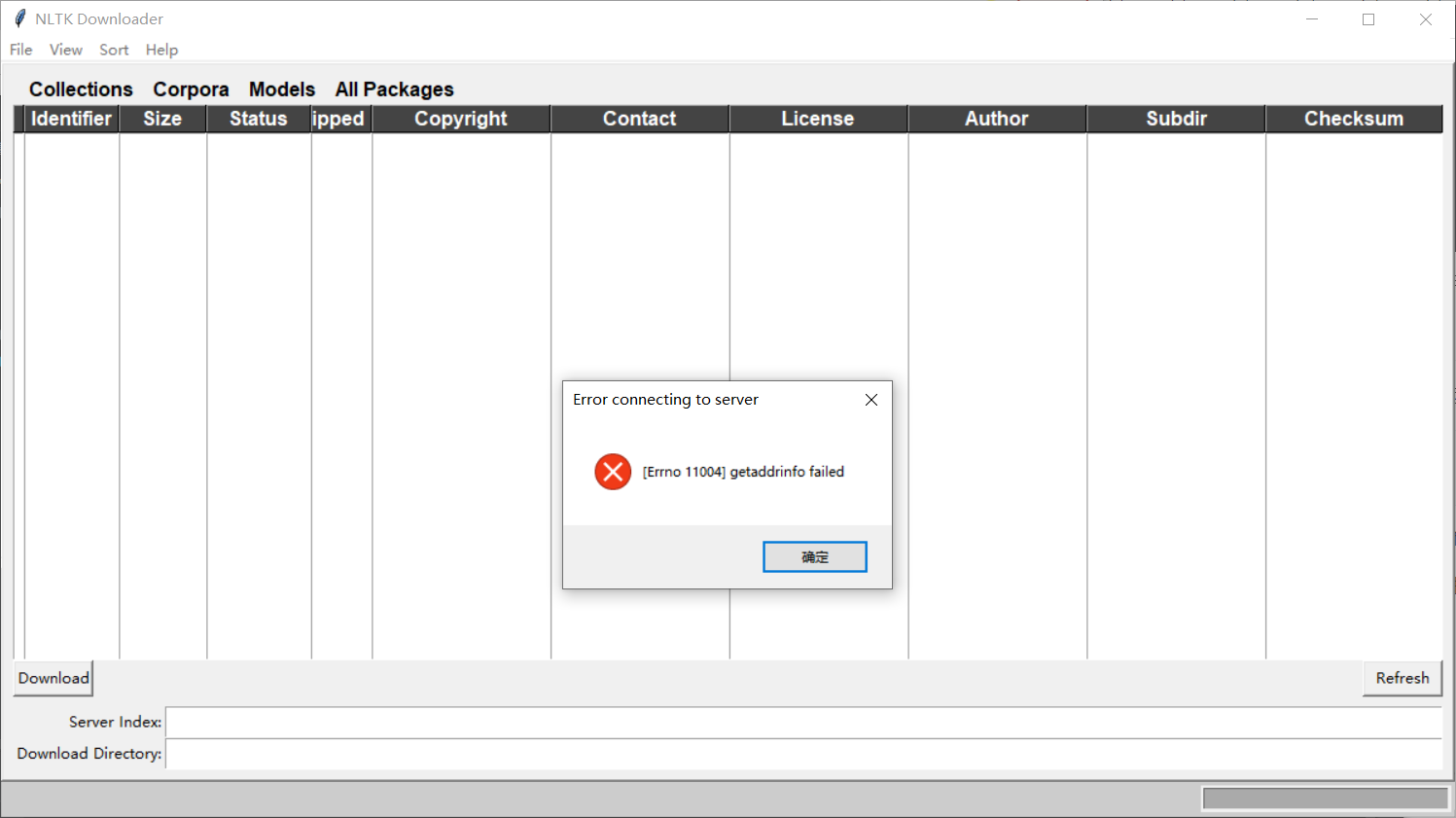
可见,直接代码安装不行
因为其他方法我都试过了,都没有成功,这里推荐我试了之后成功的方法
先进入这个网站:https://github.com/nltk/nltk_data/tree/gh-pages
依次点击Code—>Download Zip下载压缩包
接着执行以下代码:
1 import nltk
2 from nltk_book import *
因为此时还没有安装nltk_data安装包,它会提示找不到数据,并且提示他找数据时的默认路径:
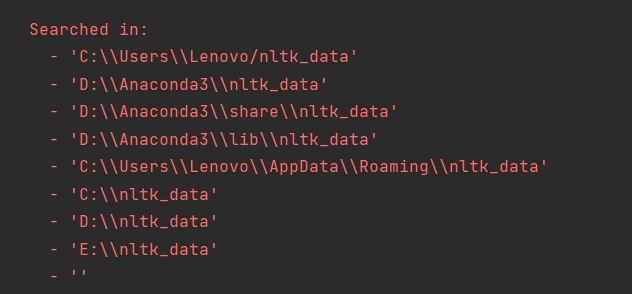
所以我们把nltk_data安装包里packages里的这些文件解压到上述任意路径,重命名为nltk_data即可,我解压到D:\Anaconda3
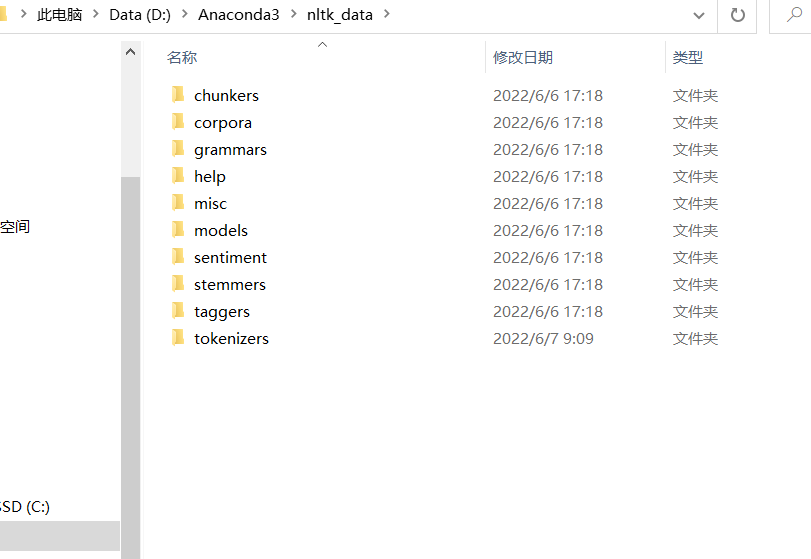
注意:下载下来的压缩包中,除了packages还有其他文件,这里只需要把packages中的文件就行。我之前就是因为直接把下载下来的压缩包全部解压到Aconda3中,导致后面验证的时候还是一直报错找不到数据!!!
完后以上步骤,执行下面代码试验一下有没有安装成功
1 import nltk
2 from nltk.book import *
出现以下内容,即成功!
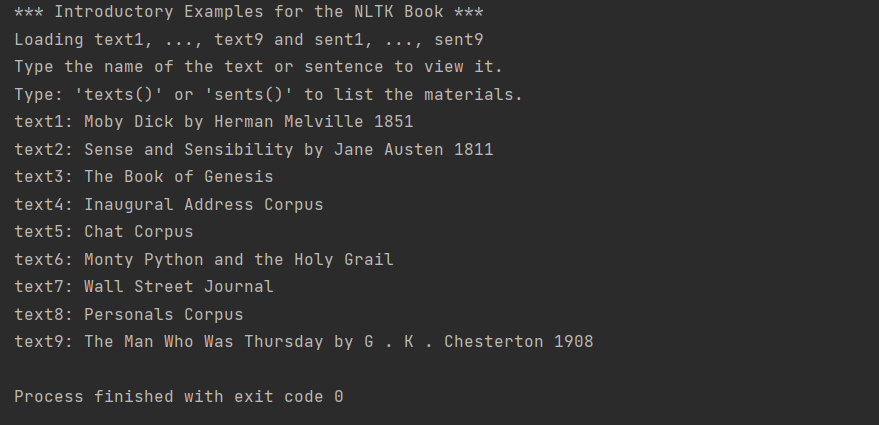
注意:在Github上下载的这个压缩数据包,里面的一些子文件夹下还有压缩内容,例如,如果调用nltk进行句子分割,会用到这个函数: word_tokenize():
1 import nltk
2
3 sen = 'hello, how are you?'
4 res = nltk.word_tokenize(sen)
5 print(res)
会提示 Resource punkt not found. Please use the NLTK Downloader to obtain the resource: 即punkt数据未找到:
类似这样的错误,其实如果找到查找的路径,也就是上面我们放数据包的地方,是可以在tokenizers文件夹下找到这个punkt的,原因就在于没有解压,那么,把punkt.zip解压到文件夹中,再运行分割句子的代码就没问题了。如果有其他的一些数据也是这样的,如果遇到显示没有找到某个数据包,不妨试一试。(如果打开其他的文件夹,发现里面也有未解压的那些文件,我们可以手动将其解压)
下载nltk数据包报错的更多相关文章
- maven 导包报错
作为初学者本应当是持之以恒的但是很长时间没有冒泡了这次冒个泡写maven项目的时候遇到了很多的bug,今天给大家分享一下解决的办法(常见的错误就是导不进来自己想要的包)要么就是导包报错以下是解决方法 ...
- 解决windows下rstudio安装playwith包报错问题
一.playwith包简介 playwith包提供了一个GTK+图形用户界面(GUI),使得用户可以编辑R图形并与其交互.playwith()函数允许用户识别和标注点.查看一个观测所有的变量值.缩放和 ...
- flask+sqlite3+echarts2+ajax数据可视化报错:UnicodeDecodeError: 'utf8' codec can't decode byte解决方法
flask+sqlite3+echarts2+ajax数据可视化报错: UnicodeDecodeError: 'utf8' codec can't decode byte 解决方法: 将 py文件和 ...
- 关于Spring运用过程中jar包报错问题
使用Spring进行web开发时,第一步就是导入jar包,今天使用SPring Task开发定时器时,导入了好多次jar包,都是报错,不知道是因为jar包版本不同还是因为需要依赖的jar包没加入,反正 ...
- 编译APR包报错 rm: cannot remove `libtoolT': No such file or directory
centos 6 编译APR包报错 在当前apr 目录 : #Vi configure +31880 ,注释掉此行 再次编译即可.
- eclispe集成Scalas环境后,导入外部Spark包报错:object apache is not a member of package org
在Eclipse中集成scala环境后,发现导入的Spark包报错,提示是:object apache is not a member of package org,网上说了一大推,其实问题很简单: ...
- 数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题
数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题 2个解决方法: 1.临时修改:mysql>set global max_a ...
- PyCharm导入tensorflow包报错的问题
[注]PyCharm导入tensorflow包报错的问题 若是你也遇到这个问题,说明你也没有理解tensorflow到底在哪里. 当安装了anaconda3.6后,在PyCharm中设置interpr ...
- 数据导入报错 Got a packet bigger than‘max_allowed_packet’bytes
数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题 2个解决方法: 1.临时修改:mysql>set global max_a ...
随机推荐
- JDK1.8.0_181的无限制强度加密策略文件变动(转载)
JDK1.8.0_181的无限制强度加密策略文件变动 原文地址 https://my.oschina.net/my1313677/blog/3109613 作者 葉者 日常记录 2019/09/23 ...
- 利用js获取不同页面间跳转需要传递的参数
获取参数的js函数如下: function GetQueryValue(queryName) { var query = decodeURI(window.location.search.substr ...
- Java语言学习day09--7月08日
今日内容介绍 1.方法基础知识 2.方法高级内容 3.方法案例 ###01方法的概述 * A: 为什么要有方法 * 提高代码的复用性 * B: 什么是方法 ...
- 2021.08.16 P1363 幻象迷宫(dfs,我感受到了出题人浓浓的恶意)
2021.08.16 P1363 幻象迷宫(dfs,我感受到了出题人浓浓的恶意) P1363 幻象迷宫 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题意: 幻象迷宫可以认为是无限 ...
- 为何数据库连接池不采用IO多路复用?
今天我们聊一个不常见的 Java 面试题:为什么数据库连接池不采用 IO 多路复用? 这是一个非常好的问题.IO多路复用被视为是非常好的性能助力器.但是一般我们在使用 DB 时,还是经常性采用c3 ...
- golang /js index 转换excel字母表头
Golang 1 package main 2 3 import "fmt" 4 5 func main() { 6 var Letters = []string{"A& ...
- 2003031121-浦娟-python数据分析五一假期作业
项目 内容 课程班级博客链接 20级数据班(本) 这个作业要求链接 Python作业 博客名称 2003031121-浦娟-python数据分析五一假期作业 要求 每道题要有题目,代码(使用插入代码, ...
- 谁动了我的主机? 之活用History命令
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! Linux系统下可通过history命令查看用户所有的历 ...
- 超清晰的 DNS 原理入门指南,看这一篇就够了~
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! DNS 是互联网核心协议之一.不管是上网浏览,还是编程开 ...
- 为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》
大家好,我是咔咔 不期速成,日拱一卒 之前ElasticSearch系列文章中提到了如何处理空值,若为Null则会直接报错,因为在ElasticSearch中当字段值为null时.空数组.null值数 ...