SMO优化算法(Sequential minimal optimization)
原文:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html
SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。关于SMO最好的资料就是他本人写的《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》了。
我拜读了一下,下面先说讲义上对此方法的总结。
首先回到我们前面一直悬而未解的问题,对偶函数最后的优化问题:
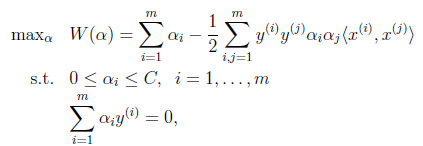
要解决的是在参数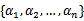 上求最大值W的问题,至于
上求最大值W的问题,至于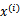 和
和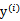 都是已知数。C由我们预先设定,也是已知数。
都是已知数。C由我们预先设定,也是已知数。
按照坐标上升的思路,我们首先固定除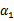 以外的所有参数,然后在
以外的所有参数,然后在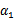 上求极值。等一下,这个思路有问题,因为如果固定
上求极值。等一下,这个思路有问题,因为如果固定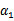 以外的所有参数,那么
以外的所有参数,那么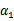 将不再是变量(可以由其他值推出),因为问题中规定了
将不再是变量(可以由其他值推出),因为问题中规定了
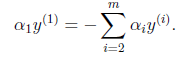
因此,我们需要一次选取两个参数做优化,比如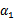 和
和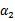 ,此时
,此时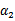 可以由
可以由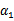 和其他参数表示出来。这样回带到W中,W就只是关于
和其他参数表示出来。这样回带到W中,W就只是关于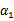 的函数了,可解。
的函数了,可解。
这样,SMO的主要步骤如下:

意思是,第一步选取一对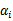 和
和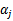 ,选取方法使用启发式方法(后面讲)。第二步,固定除
,选取方法使用启发式方法(后面讲)。第二步,固定除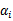 和
和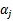 之外的其他参数,确定W极值条件下的
之外的其他参数,确定W极值条件下的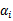 ,
,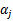 由
由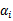 表示。
表示。
SMO之所以高效就是因为在固定其他参数后,对一个参数优化过程很高效。
下面讨论具体方法:
假设我们选取了初始值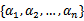 满足了问题中的约束条件。接下来,我们固定
满足了问题中的约束条件。接下来,我们固定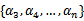 ,这样W就是
,这样W就是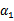 和
和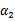 的函数。并且
的函数。并且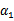 和
和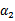 满足条件:
满足条件:
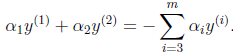
由于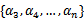 都是已知固定值,因此为了方面,可将等式右边标记成实数值
都是已知固定值,因此为了方面,可将等式右边标记成实数值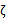 。
。
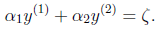
当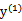 和
和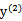 异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。如下图:
异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。如下图:
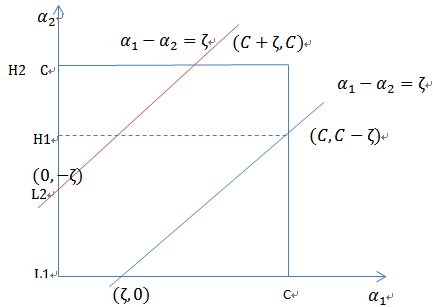
横轴是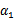 ,纵轴是
,纵轴是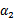 ,
,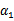 和
和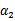 既要在矩形方框内,也要在直线上,因此
既要在矩形方框内,也要在直线上,因此
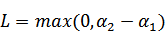 ,
,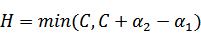
同理,当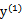 和
和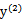 同号时,
同号时,
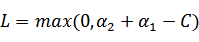 ,
,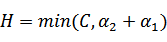
然后我们打算将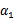 用
用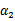 表示:
表示:
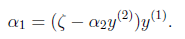
然后反代入W中,得
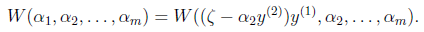
展开后W可以表示成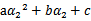 。其中a,b,c是固定值。这样,通过对W进行求导可以得到
。其中a,b,c是固定值。这样,通过对W进行求导可以得到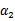 ,然而要保证
,然而要保证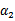 满足
满足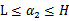 ,我们使用
,我们使用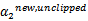 表示求导求出来的
表示求导求出来的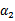 ,然而最后的
,然而最后的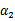 ,要根据下面情况得到:
,要根据下面情况得到:
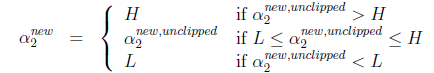
这样得到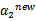 后,我们可以得到
后,我们可以得到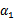 的新值
的新值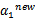 。
。
下面进入Platt的文章,来找到启发式搜索的方法和求b值的公式。
这边文章使用的符号表示有点不太一样,不过实质是一样的,先来熟悉一下文章中符号的表示。
文章中定义特征到结果的输出函数为

与我们之前的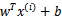 实质是一致的。
实质是一致的。
原始的优化问题为:
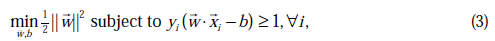
求导得到:

经过对偶后为:
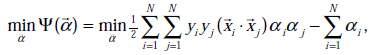
s.t. 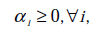
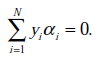
这里与W函数是一样的,只是符号求反后,变成求最小值了。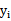 和
和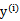 是一样的,都表示第i个样本的输出结果(1或-1)。
是一样的,都表示第i个样本的输出结果(1或-1)。
经过加入松弛变量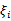 后,模型修改为:
后,模型修改为:
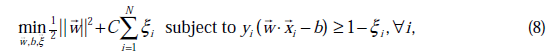

由公式(7)代入(1)中可知,

这个过程和之前对偶过程一样。
重新整理我们要求的问题为:
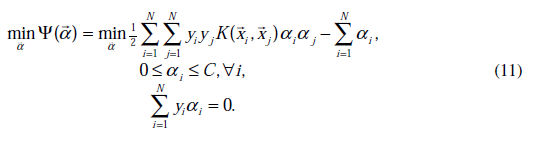
与之对应的KKT条件为:

这个KKT条件说明,在两条间隔线外面的点,对应前面的系数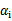 为0,在两条间隔线里面的对应
为0,在两条间隔线里面的对应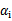 为C,在两条间隔线上的对应的系数
为C,在两条间隔线上的对应的系数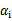 在0和C之间。
在0和C之间。
将我们之前得到L和H重新拿过来:
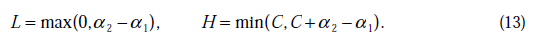
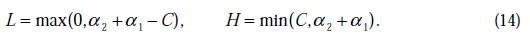
之前我们将问题进行到这里,然后说将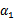 用
用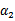 表示后代入W中,这里将代入
表示后代入W中,这里将代入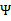 中,得
中,得
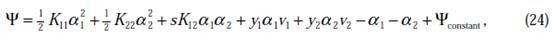
其中
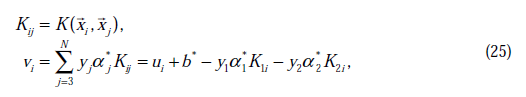
这里的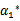 和
和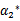 代表某次迭代前的原始值,因此是常数,而
代表某次迭代前的原始值,因此是常数,而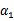 和
和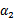 是变量,待求。公式(24)中的最后一项是常数。
是变量,待求。公式(24)中的最后一项是常数。
由于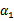 和
和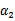 满足以下公式
满足以下公式
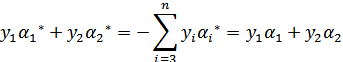
因为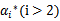 的值是固定值,在迭代前后不会变。
的值是固定值,在迭代前后不会变。
那么用s表示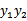 ,上式两边乘以
,上式两边乘以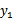 时,变为:
时,变为:

其中
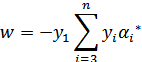
代入(24)中,得
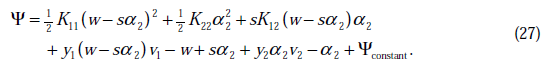
这时候只有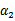 是变量了,求导
是变量了,求导
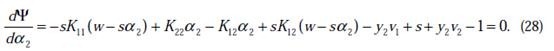
如果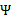 的二阶导数大于0(凹函数),那么一阶导数为0时,就是极小值了。
的二阶导数大于0(凹函数),那么一阶导数为0时,就是极小值了。
假设其二阶导数为0(一般成立),那么上式化简为:
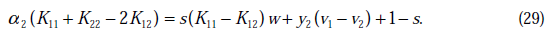
将w和v代入后,继续化简推导,得(推导了六七行推出来了)
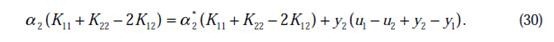
我们使用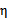 来表示:
来表示:
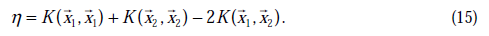
通常情况下目标函数是正定的,也就是说,能够在直线约束方向上求得最小值,并且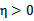 。
。
那么我们在(30)两边都除以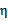 可以得到
可以得到

这里我们使用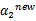 表示优化后的值,
表示优化后的值,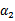 是迭代前的值,
是迭代前的值,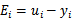 。
。
与之前提到的一样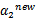 不是最终迭代后的值,需要进行约束:
不是最终迭代后的值,需要进行约束:
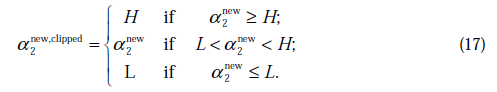
那么
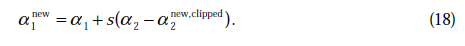
在特殊情况下,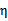 可能不为正,如果核函数K不满足Mercer定理,那么目标函数可能变得非正定,
可能不为正,如果核函数K不满足Mercer定理,那么目标函数可能变得非正定,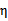 可能出现负值。即使K是有效的核函数,如果训练样本中出现相同的特征x,那么
可能出现负值。即使K是有效的核函数,如果训练样本中出现相同的特征x,那么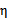 仍有可能为0。SMO算法在
仍有可能为0。SMO算法在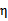 不为正值的情况下仍有效。为保证有效性,我们可以推导出
不为正值的情况下仍有效。为保证有效性,我们可以推导出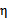 就是
就是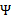 的二阶导数,
的二阶导数,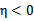 ,
,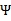 没有极小值,最小值在边缘处取到(类比
没有极小值,最小值在边缘处取到(类比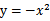 ),
),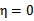 时更是单调函数了,最小值也在边缘处取得,而
时更是单调函数了,最小值也在边缘处取得,而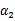 的边缘就是L和H。这样将
的边缘就是L和H。这样将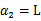 和
和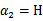 分别代入
分别代入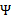 中即可求得
中即可求得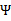 的最小值,相应的
的最小值,相应的 还是
还是 也可以知道了。具体计算公式如下:
也可以知道了。具体计算公式如下:
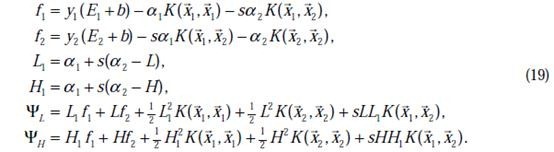
至此,迭代关系式出了b的推导式以外,都已经推出。
b每一步都要更新,因为前面的KKT条件指出了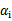 和
和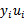 的关系,而
的关系,而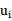 和b有关,在每一步计算出
和b有关,在每一步计算出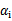 后,根据KKT条件来调整b。
后,根据KKT条件来调整b。
b的更新有几种情况:

来自罗林开的ppt
这里的界内指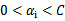 ,界上就是等于0或者C了。
,界上就是等于0或者C了。
前面两个的公式推导可以根据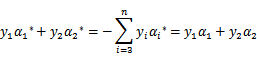
和对于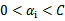 有
有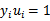 的KKT条件推出。
的KKT条件推出。
这样全部参数的更新公式都已经介绍完毕,附加一点,如果使用的是线性核函数,我们就可以继续使用w了,这样不用扫描整个样本库来作内积了。
w值的更新方法为:
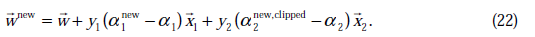
根据前面的

公式推导出。
12 SMO中拉格朗日乘子的启发式选择方法
终于到了最后一个问题了,所谓的启发式选择方法主要思想是每次选择拉格朗日乘子的时候,优先选择样本前面系数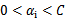 的
的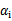 作优化(论文中称为无界样例),因为在界上(
作优化(论文中称为无界样例),因为在界上(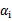 为0或C)的样例对应的系数
为0或C)的样例对应的系数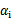 一般不会更改。
一般不会更改。
这条启发式搜索方法是选择第一个拉格朗日乘子用的,比如前面的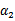 。那么这样选择的话,是否最后会收敛。可幸的是Osuna定理告诉我们只要选择出来的两个
。那么这样选择的话,是否最后会收敛。可幸的是Osuna定理告诉我们只要选择出来的两个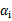 中有一个违背了KKT条件,那么目标函数在一步迭代后值会减小。违背KKT条件不代表
中有一个违背了KKT条件,那么目标函数在一步迭代后值会减小。违背KKT条件不代表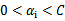 ,在界上也有可能会违背。是的,因此在给定初始值
,在界上也有可能会违背。是的,因此在给定初始值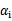 =0后,先对所有样例进行循环,循环中碰到违背KKT条件的(不管界上还是界内)都进行迭代更新。等这轮过后,如果没有收敛,第二轮就只针对
=0后,先对所有样例进行循环,循环中碰到违背KKT条件的(不管界上还是界内)都进行迭代更新。等这轮过后,如果没有收敛,第二轮就只针对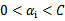 的样例进行迭代更新。
的样例进行迭代更新。
在第一个乘子选择后,第二个乘子也使用启发式方法选择,第二个乘子的迭代步长大致正比于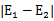 ,选择第二个乘子能够最大化
,选择第二个乘子能够最大化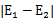 。即当
。即当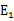 为正时选择负的绝对值最大的
为正时选择负的绝对值最大的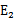 ,反之,选择正值最大的
,反之,选择正值最大的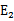 。
。
最后的收敛条件是在界内(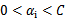 )的样例都能够遵循KKT条件,且其对应的
)的样例都能够遵循KKT条件,且其对应的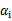 只在极小的范围内变动。
只在极小的范围内变动。
至于如何写具体的程序,请参考John C. Platt在论文中给出的伪代码。
13 总结
这份SVM的讲义重点概括了SVM的基本概念和基本推导,中规中矩却又让人醍醐灌顶。起初让我最头疼的是拉格朗日对偶和SMO,后来逐渐明白拉格朗日对偶的重要作用是将w的计算提前并消除w,使得优化函数变为拉格朗日乘子的单一参数优化问题。而SMO里面迭代公式的推导也着实让我花费了不少时间。
对比这么复杂的推导过程,SVM的思想确实那么简单。它不再像logistic回归一样企图去拟合样本点(中间加了一层sigmoid函数变换),而是就在样本中去找分隔线,为了评判哪条分界线更好,引入了几何间隔最大化的目标。
之后所有的推导都是去解决目标函数的最优化上了。在解决最优化的过程中,发现了w可以由特征向量内积来表示,进而发现了核函数,仅需要调整核函数就可以将特征进行低维到高维的变换,在低维上进行计算,实质结果表现在高维上。由于并不是所有的样本都可分,为了保证SVM的通用性,进行了软间隔的处理,导致的结果就是将优化问题变得更加复杂,然而惊奇的是松弛变量没有出现在最后的目标函数中。最后的优化求解问题,也被拉格朗日对偶和SMO算法化解,使SVM趋向于完美。
另外,其他很多议题如SVM背后的学习理论、参数选择问题、二值分类到多值分类等等还没有涉及到,以后有时间再学吧。其实朴素贝叶斯在分类二值分类问题时,如果使用对数比,那么也算作线性分类器。
SMO优化算法(Sequential minimal optimization)的更多相关文章
- Sequential Minimal Optimization(SMO,序列最小优化算法)初探
什么是SVM SVM是Support Vector Machine(支持向量机)的英文缩写,是上世纪九十年代兴起的一种机器学习算法,在目前神经网络大行其道的情况下依然保持着生命力.有人说现在是神经网络 ...
- Jordan Lecture Note-8: The Sequential Minimal Optimization Algorithm (SMO).
The Sequential Minimal Optimization Algorithm (SMO) 本文主要介绍用于解决SVM对偶模型的算法,它于1998年由John Platt在论文“Seque ...
- sequential minimal optimization,SMO for SVM, (MATLAB code)
function model = SMOforSVM(X, y, C ) %sequential minimal optimization,SMO tol = 0.001; maxIters = 30 ...
- Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines 论文研读
摘要 本文提出了一种用于训练支持向量机的新算法:序列最小优化算法(SMO).训练支持向量机需要解决非常大的二 次规划(QP)优化问题.SMO 将这个大的 QP 问题分解为一系列最小的 QP 问题.这些 ...
- Support Vector Machine (2) : Sequential Minimal Optimization
目录 Support Vector Machine (1) : 简单SVM原理 Support Vector Machine (2) : Sequential Minimal Optimization ...
- 果蝇优化算法_Fruit Fly Optimization
1. 果蝇优化算法背景 在夏天,果蝇是一种随处可见的昆虫.果蝇在嗅觉和视觉特别突出.腐烂的食物发出一种刺鼻的味道,温度越高这种气味的扩散速度较快,果蝇对这种味道非常敏感.腐烂的味道和食物的位置有关.一 ...
- Sequential Minimal Optimization (SMO) 算法
SVM 最终关于 $a$ 目标函数为凸优化问题,该问题具有全局最优解,许多最优化算法都可以解决该问题,但当样本容量相对很大时,通常采用 SMO 算法(比如 LIBSVM),该算法为启发式算法,考虑在约 ...
- SMO(Sequential Minimal Optimization) 伪代码(注释)
Algorithm: Simplified SMO 这个版本是简化版的,并没有采用启发式选择,但是比较容易理解. 输入: C: 调和系数 tol: 容差 (tolerance) max passes: ...
- paper 8:支持向量机系列五:Numerical Optimization —— 简要介绍求解求解 SVM 的数值优化算法。
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
随机推荐
- DNN 错误代码 0x80070005 解决方案
在IIS上创建DNN站点,可能出现的错误代码:0x80070005,因为权限不足而不能访问DNN. 解决方法:打开IIS, 1.右键目标网站->编辑权限->安全->添加组或者用户 “ ...
- Strassen算法
如题,该算法是来自德国的牛逼的数学家strassen搞出来的,因为把n*n矩阵之间的乘法复杂度降低到n^(lg7)(lg的底是2),一开始想当然地认为朴素的做法是n^3,哪里还能有复杂度更低的做法,但 ...
- JVM系列一:JVM内存组成及分配
java内存组成介绍:堆(Heap)和非堆(Non-heap)内存 按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在 Java 虚拟机启动时 ...
- Physicals
[Physicals] The physics simulation in Sprite Kit is performed by adding physics bodies to scenes. [T ...
- Android反射出一个类中的其他类对象并调用其对应方法
MainActivity如下: package cn.testreflect; import java.lang.reflect.Field; import java.lang.reflect.Met ...
- How to create custom methods for use in spring security expression language annotations
From:http://stackoverflow.com/questions/6632982/how-to-create-custom-methods-for-use-in-spring-secur ...
- SharePoint 2013 自定义翻页显示列表项
项目需求:自定义开发一个能分页显示列表项的小部件,允许左右翻页,能根据用户权限来显示管理链接等. 效果如下: 技术要求:使用sharepoint rest API 来获取列表项,这样性能高,能够快速响 ...
- Array--Good parts
js数组没有上届 --如果你用大于或等于当前length的数字作为下标来存储一个元素,那么length会被增大以容纳新元素,不会发生数组越界. 数组也是对象 --可以添加属性.a["name ...
- Oracle数据库多语言文字存储解决方案
一.关于字符集 字符集(也称字元集,Character Set)就是字符编码表(codepage),一个字符不论英文.中文.韩文等在计算机系统内存或硬盘中通过二进制的字节(Byte)保存,这个二进制的 ...
- NAT后面的FTP SERVER终极篇
原文引用:http://blog.chinaunix.net/uid-20592805-id-1918661.html 如果对于被动模式还有不同的意见,我们可以再看下这篇文章: http://ww ...