OpenCV码源笔记——RandomTrees (二)(Forest)
源码细节:
● 训练函数
const CvMat* _responses, const CvMat* _var_idx,
const CvMat* _sample_idx, const CvMat* _var_type,
const CvMat* _missing_mask, CvRTParams params )
Step1:清理现场,调用clear()函数,删除和释放所有决策树,清除训练数据等;
Step2:构造适用于单棵决策树训练的参数包CvDTreeParams,主要就是对CvRTParams中一些参数的拷贝;
Step3:构建训练数据CvDTreeTrainData,主要涉及CvDTreeTrainData::set_data()函数。CvDTreeTrainData包含CvDTreeParams格式的参数包、被所有树共享的训练数据(优化结构使最优分裂更迅速)以及response类型和类数目等常用数据,还包括最终构造出来的树节点缓存等。
Step4:检查CvRTParams::nactive_vars使其不大于最大启用变量数;若nactive_vars传参为0,则默认赋值为最大启用变量数的平方根;若小于0,则报错退出;
Step5:创建并初始化一个变量活跃Mask(1×变量总数),初始化过程设置前nactive_vars个变量mask为1(活跃),其余为0(非活跃);
Step6:调用CvRTrees::grow_forest()开始生成森林。
● 生成森林
Step1:如果需要以准确率为终止条件或者需要计算变量的重要值(is_oob_or_vimportance = true),则需要创建并初始化以下数据:
oob_sample_votes 用于分类问题,样本数量×类数量,存储每个样本的测试分类;
oob_responses 用于回归问题,2×样本数量,这是一个不直接使用的数据,旨在为以下两个数据开辟空间;
oob_predictions_sum 用于回归问题,1×样本数量,存储每个样本的预测值之和;
oob_num_of_predictions 用于回归问题,1×样本数量,存储每个样本被预测的次数;
oob_samples_perm_ptr 用于存储乱序样本,样本数量×类数量;
samples_ptr / missing_ptr / true_resp_ptr 从训练数据中拷贝的样本数组、缺失Mask和真实response数组;
maximal_response response的最大绝对值。
Step2:初始化以下数据:
trees CvForestTree格式的单棵树集合,共max_ntrees棵,max_ntrees由CvDTreeParams定义;
sample_idx_mask_for_tree 存储每个样本是否参与当前树的构建,1×样本数量;
sample_idx_for_tree 存储在构建当前树时参与的样本序号,1×样本数量;
Step3:随机生成参与当前树构建的样本集(sample_idx_for_tree定义),调用CvForestTree::train()函数生成当前树,加入树集合中。CvForestTree::train()先调用CvDTreeTrainData::subsample_data()函数整理样本集,再通过调用CvForestTree::try_split_node()完成树的生成,try_split_node是一个递归函数,在分割当前节点后,会调用分割左右节点的try_split_node函数,直到准确率达到标准或者节点样本数过少;
Step4:如果需要以准确率为终止条件或者需要计算变量的重要值(is_oob_or_vimportance = true),则:
使用未参与当前树构建的样本,测试当前树的预测准确率;
若需计算变量的重要值,对于每一种变量,对每一个非参与样本,替换其该位置的变量值为另一随机样本的该变量值,再进行预测,其正确率的统计值与上一步当前树的预测准确率的差,将会累计到该变量的重要值中;
Step5:重复Step3 – 4,直到终止条件;
Step6:若需计算变量的重要值,归一化变量重要性到[0, 1]。
●训练单棵树
Step1:调用CvDtree::calc_node_value()函数:对于分类问题,计算当前节点样本中最大样本数量的类别,最为该节点的类别,同时计算更新交叉验证错误率(命名带有cv_的数据);对于回归问题,也是类似的计算当前节点样本值的均值作为该节点的值,也计算更新交叉验证错误率;
Step2:作终止条件判断:样本数量是否过少;深度是否大于最大指定深度;对于分类问题,该节点是否只有一种类别;对于回归问题,交叉验证错误率是否已达到指定精度要求。若是,则停止分裂;
Step3:若可分裂,调用CvForestTree::find_best_split()函数寻找最优分裂,首先随机当前节点的活跃变量,再使用ForestTreeBestSplitFinder完成:ForestTreeBestSplitFinder对分类或回归问题、变量是否可数,分别处理。对于每个可用变量调用相应的find函数,获得针对某一变量的最佳分裂,再在这所有最佳分裂中依照quality值寻找最最优。find函数只关描述分类问题(回归其实差不多):
CvForestTree::find_split_ord_class():可数变量,在搜寻开始前,最主要的工作是建立一个按变量值升序的样本index序列,搜寻按照这个序列进行。最优分裂的依据是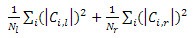
也就是左右分裂所有类别中样本数量的平方 / 左右分裂的样本总数,再相加(= =还是公式看的懂些吧。。)
比如说,排序后的 A A B A B B C B C C 这样的序列,比较这样两种分裂方法:
A A B A B B | C B C C 和 A A B A B B C B | C C
第一种的quality是 (32 + 32 + 02) / 6 + (02 + 12 + 32) / 4 = 5.5
第二种的quality是 (32 + 42 + 12) / 8 + (02 + 02 + 22) / 2 = 5.25
第一种更优秀些。感性地看,第一种的左分裂只有AB,右分裂只有BC,那么可能再来一次分裂就能完全分辨;而第二种虽然右分裂只有C,但是左分裂一团糟,其实完全没做什么事情。
最优搜寻过程中会跳过一些相差很小的以及不活跃的变量值,主要是为了避免在连续变量取值段出现分裂,这在真实预测中会降低树的鲁棒性。
CvForestTree::find_split_cat_class():不可数变量,分裂quality的计算与可数情况相似,不同的是分类的标准,不再是阈值对数值的左右划分,而是对变量取值的子集划分,比如将a b c d e五种可取变量值分为{a} + {b, c, d, e}、{a, b} + {c, d, e}等多种形式比较quality。统计的是左右分裂每个类别取该分裂子集中的变量值的样本数量的平方 / 左右分裂的样本总数,再相加。同样,搜寻会跳过样本数量很少的以及不活跃的分类取值。
Step4:若不存在最优分裂或者无法分裂,则释放相关数据后返回;否则,处理代理分裂、分割左右分裂数据、调用左右后续分裂。
References:
[1] OpenCV 2.3 Online Documentation: http://opencv.itseez.com/modules/ml/doc/random_trees.html
[2] Random Forests, Leo Breiman and Adele Cutler: http://www.stat.berkeley.edu/users/breiman/RandomForests/cc_home.htm
[3] T. Hastie, R. Tibshirani, J. H. Friedman. The Elements of Statistical Learning. ISBN-13 978-0387952840, 2003, Springer.
from: http://blog.csdn.net/yangtrees/article/details/7488913
OpenCV码源笔记——RandomTrees (二)(Forest)的更多相关文章
- OpenCV码源笔记——RandomTrees (一)
OpenCV2.3中Random Trees(R.T.)的继承结构: API: CvRTParams 定义R.T.训练用参数,CvDTreeParams的扩展子类,但并不用到CvDTreeParams ...
- OpenCV码源笔记——Decision Tree决策树
来自OpenCV2.3.1 sample/c/mushroom.cpp 1.首先读入agaricus-lepiota.data的训练样本. 样本中第一项是e或p代表有毒或无毒的标志位:其他是特征,可以 ...
- Apollo源码阅读笔记(二)
Apollo源码阅读笔记(二) 前面 分析了apollo配置设置到Spring的environment的过程,此文继续PropertySourcesProcessor.postProcessBeanF ...
- Vue2.0源码阅读笔记(二):响应式原理
Vue是数据驱动的框架,在修改数据时,视图会进行更新.数据响应式系统使得状态管理变的简单直接,在开发过程中减少与DOM元素的接触.而深入学习其中的原理十分有必要,能够回避一些常见的问题,使开发变的 ...
- async-validator 源码学习笔记(二):目录结构
上一篇文章<async-validator 源码学习(一):文档翻译>已经将 async-validator 校验库的文档翻译为中文,看着文档可以使用 async-validator 异步 ...
- Mina源码阅读笔记(二)- IoBuffer的封装
在阅读IoBuffer源码之前,我们先看Mina对IoBuffer的描述:A byte buffer used by MINA applications. This is a replacement ...
- Bottle源码阅读笔记(二):路由
前言 程序收到请求后,会根据URL来寻找相应的视图函数,随后由其生成页面发送回给客户端.其中,不同的URL对应着不同的视图函数,这就存在一个映射关系.而处理这个映射关系的功能就叫做路由.路由的实现分为 ...
- Dalvik源码阅读笔记(二)
DVM 类加载原理: DEX 文件加载到内存中 DvmDex 结构后,还没有完成类的解析工作,我们将 DEX 中的类填充到 ClassObject 结构的过程称为类加载. ClassObject 用来 ...
- Yii源码阅读笔记(二十九)
动态模型DynamicModel类,用于实现模型内数据验证: namespace yii\base; use yii\validators\Validator; /** * DynamicModel ...
随机推荐
- Linq to XML 之XElement的Descendants方法的新发现
C#操作XML的方法有很多,但个人认为最方便的莫过于Linq to XML了,特别是XElement的Descendants方法是我最常用的一个方法. 这个方法可以根据节点名(Name)找到当前调用的 ...
- Android SDK Android NDK 官方下载地址
Android NDK r6b Windows http://dl.google.com/android/ndk/android-ndk-r6b-windows.zip Mac OS X(intel) ...
- IIS Express start introduction and applicationHost modification
1. First you need create a web project in VS 2. When you finish your project, click start then IIS E ...
- JAVA里的String、Timestamp、Date相互转换(转)
转自:http://blog.sina.com.cn/s/blog_6675493d0100lbfl.html Timestamp转化为String: SimpleDateFormat df = ne ...
- html+css学习笔记 4[定位]
如何让图1中的div2移动到如图2上的位置: 思路:哪些css命令能够影响盒子显示的位置呢? relative相对定位/定位偏移量 position:relative; 相对定位 a ...
- git/github在windows上使用
问题描述: git在Windows上的使用 问题解决: (1)下载安装git http://msysgit.github.io/ 到该网址中下载msgit软件 注: 安装msg ...
- C++ 操作法重载
http://www.weixueyuan.net/view/6382.html http://wuyuans.com/2012/09/cpp-operator-overload/
- Linux操作系统下软件的安装方法大全
一.rpm包安装方式步骤: 1.找到相应的软件包,比如soft.version.rpm,下载到本机某个目录: 2.打开一个终端,su -成root用户: 3.cd soft.version.rpm所在 ...
- poj 2362
回溯加剪枝 #include <cstdio> #include <cstdlib> #include <cmath> #include <map> # ...
- Scrum敏捷开发简介
Agile 敏捷开发实践中,强调团队的自我管理.在 Scrum 中,自我团队管理体现在每天的 Scrum 会议中和日常的协同工作,在每天的 Scrum 例会中,团队成员一般回答一下几个问题 : 昨天完 ...