[大牛翻译系列]Hadoop(7)MapReduce:抽样(Sampling)
4.3 抽样(Sampling)
用基于MapReduce的程序来处理TB级的数据集,要花费的时间可能是数以小时计。仅仅是优化代码是很难达到良好的效果。
在开发和调试代码的时候,没有必要处理整个数据集。但如果在这种情况下要保证数据集能够被正确地处理,就需要用到抽样了。抽样是统计学中的一个方法。它通过一定的过程从整个数据中抽取出一个子数据集。这个子数据集能够代表整体数据集的数据分布状况。在MapReduce中,开发人员可以只针对这个子数据集进行开发调试,极大减小了系统负担,提高了开发效率。
技术23 水塘抽样(Reservoir sampling)
假设如下场景:在开发一个MapReduce作业的时候,需要反复不断地去测试一个超大数据集。当然,处理这个数据集很费时间,想要快速开发几乎不可能。
问题
在开发MapReduce作业的时候,如何能够只用处理超大数据集的一个小小的子集?
方案
在读取数据的那部分,自定义一个InputFormat来封装默认的InputFormat。在自定义的InputFormat中,将从默认的InputFormat中得到的数据按一定比例进行抽样。
讨论
由于水塘抽样可以从数据流中随机采样,它就特别适合于MapReduce。在MapReduce中,数据源的形式就是数据流。图4.16说明了水塘抽样的算法。

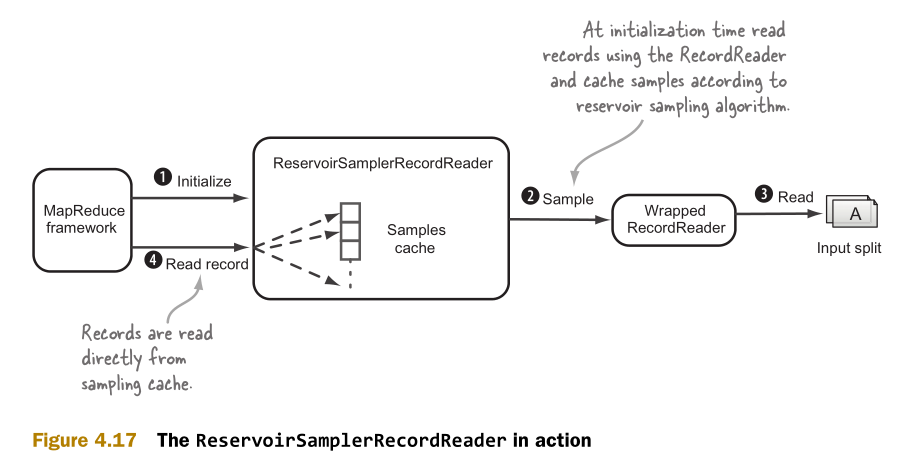
这里需要实现ReservoirSamplerRecordReader类来封装默认的InputFormat类和RecordReader类。InputFormat类的作用是对输入进行分块。RecordReader类的作用是读取记录。抽样功能则在ReservoirSamplerRecordReader类中实现。图4.17说明了ReservoirSamplerRecordReader类的工作机制。
以下是ReservoirSamplerRecordReader类的实现代码:
public static class ReservoirSamplerRecordReader<K extends Writable, V extends Writable> extends RecordReader {
private final RecordReader<K, V> rr;
private final int numSamples;
private final int maxRecords;
private final ArrayList<K> keys;
private final ArrayList<V> values;
@Override
public void initialize(InputSplit split,TaskAttemptContext context)
throws IOException, InterruptedException {
rr.initialize(split, context);
Random rand = new Random();
for (int i = 0; i < maxRecords; i++) {
if (!rr.nextKeyValue()) {
break;
}
K key = rr.getCurrentKey();
V val = rr.getCurrentValue();
if (keys.size() < numSamples) {
keys.add(WritableUtils.clone(key, conf));
values.add(WritableUtils.clone(val, conf));
} else {
int r = rand.nextInt(i);
if (r < numSamples) {
keys.set(r, WritableUtils.clone(key, conf));
values.set(r, WritableUtils.clone(val, conf));
}
}
}
}
...
在使用ReservoirSamplerInputFormat类的时候,需要设置的参数包括InputFormat等。以下是设置代码:
ReservoirSamplerInputFormat.setInputFormat(job,TextInputFormat.class);
ReservoirSamplerInputFormat.setNumSamples(job, 10);
ReservoirSamplerInputFormat.setMaxRecordsToRead(job, 10000);
ReservoirSamplerInputFormat.setUseSamplesNumberPerInputSplit(job, true);
然后在batch中执行作业,输入文件是name.txt,有88799行。经过抽样后的文件只有10行了。以下是作业执行的过程:
$ wc -l test-data/names.txt
88799 test-data/names.txt $ hadoop fs -put test-data/names.txt names.txt $ bin/run.sh com.manning.hip.ch4.sampler.SamplerJob \
names.txt output $ hadoop fs -cat output/part* | wc -l
10
前面设置的ReservoirSamplerInputFormat类的参数是抽样10行,最后的结果就是10行。
小结
抽样可以把数据集的尺寸变小,这对开发是很有帮助的。如果有时需要抽样,有时不需要抽样,怎么才能把抽样功能很好地整合到代码库中呢?这里有个方法,在作业的configure中加入一个开关,如下面的代码所示:
if(appConfig.isSampling()) {
ReservoirSamplerInputFormat.setInputFormat(job,
TextInputFormat.class);
...
} else {
job.setInputFormatClass(TextInputFormat.class);
}
这样就可以把抽样和其他各种代码整合了。
[大牛翻译系列]Hadoop(7)MapReduce:抽样(Sampling)的更多相关文章
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- [大牛翻译系列]Hadoop(14)MapReduce 性能调优:减小数据倾斜的性能损失
6.4.4 减小数据倾斜的性能损失 数据倾斜是数据中的常见情况.数据中不可避免地会出现离群值(outlier),并导致数据倾斜.这些离群值会显著地拖慢MapReduce的执行.常见的数据倾斜有以下几类 ...
- [大牛翻译系列]Hadoop(6)MapReduce 排序:总排序(Total order sorting)
4.2.2 总排序(Total order sorting) 有的时候需要将作业的的所有输出进行总排序,使各个输出之间的结果是有序的.有以下实例: 如果要得到某个网站中最受欢迎的网址(URL),就需要 ...
- [大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)
4.2 排序(SORT) 在MapReduce中,排序的目的有两个: MapReduce可以通过排序将Map输出的键分组.然后每组键调用一次reduce. 在某些需要排序的特定场景中,用户可以将作业( ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码 MapReduce执行代码的方式和普通JAVA应用不同.这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduc ...
- [大牛翻译系列]Hadoop(13)MapReduce 性能调优:优化洗牌(shuffle)和排序阶段
6.4.3 优化洗牌(shuffle)和排序阶段 洗牌和排序阶段都很耗费资源.洗牌需要在map和reduce任务之间传输数据,会导致过大的网络消耗.排序和合并操作的消耗也是很显著的.这一节将介绍一系列 ...
随机推荐
- .NET和SQL Server中“空值”辨析 (DBNull与Null的区别)
对表进行插入操作,如datetime和int类型的两个字段,都允许为null,用“sqlcmd.Parameters.Add("@t12",tb12.Text)”参数绑定时.dat ...
- 短小实用 渗透用的Python小脚本
渗透的很多时候,找到的工具并不适用,自己码代码才是王道,下面三个程序都是渗透时在网络上找不到合适工具,自己辛苦开发的,短小实用. 一.记录root密码小工具 root.py #!/usr/bin/py ...
- iOS 定位系统 知识
最近在做考勤定位系统 总结一些定位系统的知识. 后期会出一份算法主要攻克地球坐标和火星坐标转换的 1.关于百度的火星坐标定位策略 地图SDK/定位SDK的定位策略: WIFI + 基站 +GPS 三者 ...
- iOS 全局竖屏 单个viewcontroller点击按钮支持横屏
问题描述:项目工程只支持竖屏,在播放器页面需要点击按钮进行横竖屏切换,并能根据手机的方向进行自动旋转 如图:只勾选了竖屏 解决方法:(主要是采用视图transform的原理 横屏时调整视频视图上的每个 ...
- ASP.NET页面与IIS底层交互和工作原理详解(第一回)
引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是站在一个比较高的层次上讲解Asp.Net.他们耐心.细致地告诉你如何一步步拖放控件.设置控件属性.编写CodeBehind代码,以实现某个特定 ...
- mysql_DML_insert
1.指定字段插入数据 insert into wsb2(stu_name,salary)values ('nan','10000'); insert into wsb2(stu_name,salary ...
- 【转】ConcurrentHashMap完全解析(JDK6/7、JDK8)
转自http://my.oschina.net/hosee/blog/675884 并发编程实践中,ConcurrentHashMap是一个经常被使用的数据结构,相比于Hashtable以及Colle ...
- Java基础--访问权限控制符
今天我们来探讨一下访问权限控制符. 使用场景一:攻城狮A编写了ClassA,但是他不想所有的攻城狮都可以使用该类,应该怎么办? 使用场景二:攻城狮A编写了ClassA,里面有func1方法和func2 ...
- 使用tornado的gen.coroutine进行异步编程
在tornado3发布之后,强化了coroutine的概念,在异步编程中,替代了原来的gen.engine, 变成现在的gen.coroutine.这个装饰器本来就是为了简化在tornado中的异步编 ...
- ASP.NET多线程下使用HttpContext.Current
本来要实现asp.net下使用tcp通讯方式向服务器获取数据,开始采用的方式是 参考: ASP.NET多线程下使用HttpContext.Current为null解决方案 http://www.cnb ...